

Image by Editor | Canva
When it comes to the practice of data science, having quick access to essential concepts and commands can make all the difference in your workflow. Whether you’re a beginner finding your footing or an experienced practitioner looking for a reliable reference, cheat sheets serve as invaluable companions in your coding journey. This curated collection of KDnuggets exclusive cheat sheets brings together five fundamental areas that help form the backbone of modern data science from a programmatic point of view: Python control flow, Python string processing, SQL, Pandas, and Scikit-learn.
These cheat sheets are designed to be your companions in your data science journey, starting with basic programming concepts and progressing through data manipulation, database querying, and machine learning. Whether you’re writing your first Python script or fine-tuning machine learning models, these references will help you navigate the technical landscape more efficiently. Get yourself a reference that includes practical syntax examples
1. Python Control Flow
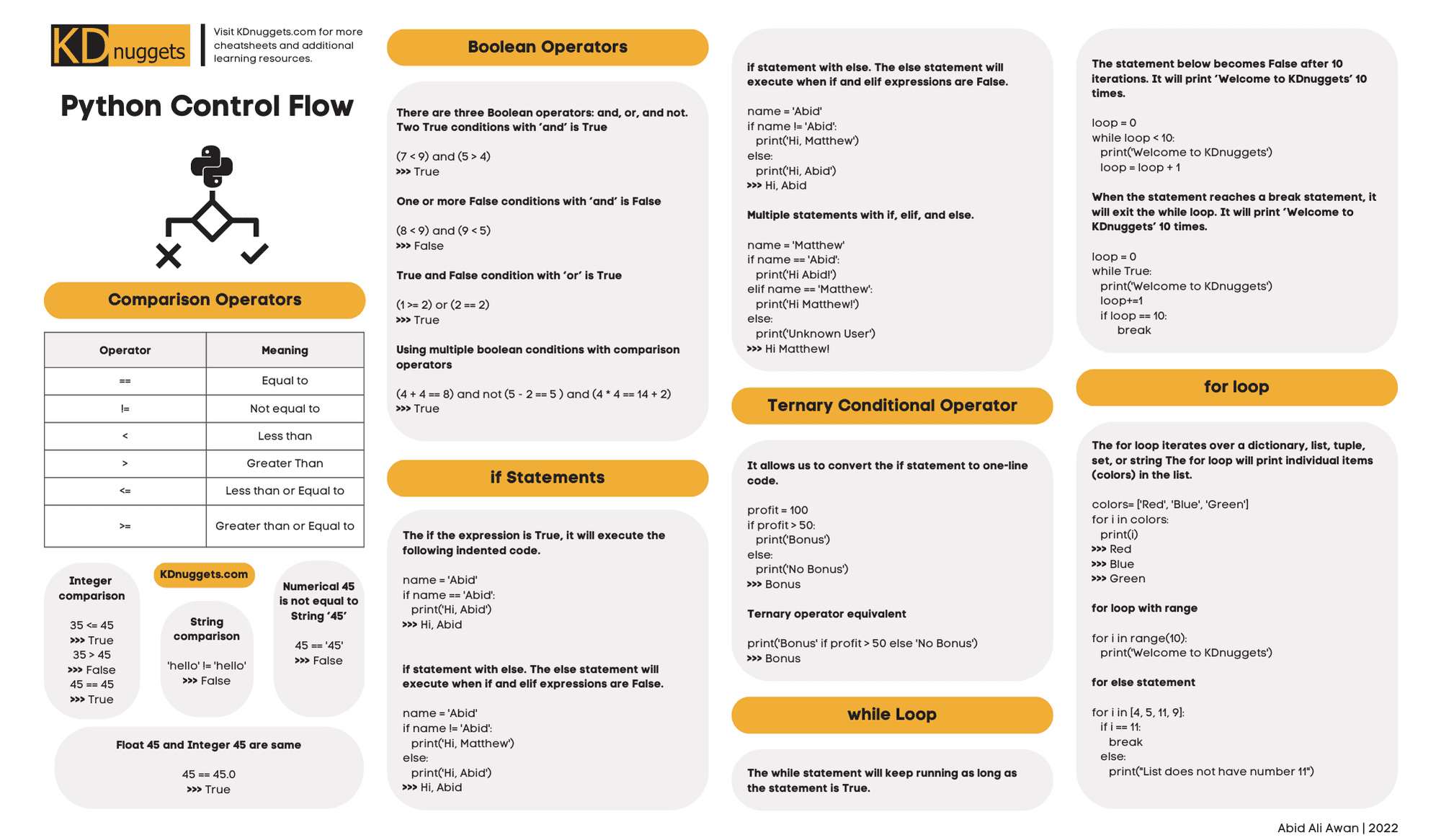
Flow control — the art of directing how and when code executes — is fundamental to programming. It’s what transforms a simple list of commands into sophisticated algorithms by determining the sequence and conditions under which code runs. Python, like other modern languages, offers sophisticated flow control patterns. Python provides particularly intuitive and readable ways to manage code execution through structures like loops, conditionals, and functions. Understanding these control structures is essential for programmers and practical data scientists alike, as they’re the building blocks that allow you to create everything from simple scripts to complex applications. Whether you’re just starting out or need a quick reference, mastering Python’s flow control mechanisms is key to writing effective code.
KDnuggets’ exclusive Python Control Flow cheat sheet.
2. Python String Processing

While natural language processing and text analytics are at the forefront of data science, mastering basic string manipulation is an essential first step. Advanced text analytics may employ sophisticated algorithms and tools, but the ability to process and manipulate text at a fundamental level remains crucial. Not only is this skill vital for the data preparation phase of text analytics projects, but understanding how computers handle text at a basic level provides important insights into more complex NLP concepts.
KDnuggets’ exclusive Python String Processing cheat sheet.
3. Getting Started with SQL

SQL (Structured Query Language) is arguably the most essential tool in a data scientist’s arsenal, not for its analytical capabilities, but because it’s the key to accessing data where it lives. While machine learning, statistics, and Python are crucial for analysis, they’re useless without data to work with. SQL is the universal language of relational databases, where organizations have been storing their valuable information for decades. Before you can build models, create visualizations, or derive insights, you need to extract the right data. SQL is the bridge between where data is stored and where the actual analysis begins.
KDnuggets’ exclusive Getting Started with SQL cheat sheet.
4. Getting Started with Pandas

Pandas stands as the cornerstone library for data manipulation in Python. It’s the go-to tool for data scientists working with tabular data, offering an extensive suite of features for data processing, analysis, and transformation. Whether you’re exploring datasets, running complex queries, or preparing data for machine learning models, Pandas provides efficiency and intuitive solutions. Its widespread adoption, comprehensive functionality, and versatility make it an essential tool for any data-related work in Python.
KDnuggets’ exclusive Getting Started with Pandas cheat sheet here.
5. Scikit-learn for Machine Learning

If you’re ready to dive into machine learning with Python fundamentals under your belt, Scikit-learn is your natural starting point. This comprehensive open-source library simplifies predictive data analysis through its unified interface. From classification and regression to clustering and model optimization, Scikit-learn provides a consistent framework for implementing machine learning algorithms. Once you grasp its straightforward pattern of implementation, you can tackle virtually any machine learning task. All you need is a good reference guide and your own curiosity to explore its possibilities.
KDnuggets’ exclusive Scikit-learn for Machine Learning cheat sheet.
Wrapping Up
From Python’s foundational control structures to advanced machine learning with Scikit-learn, these five cheat sheets encompass the essential toolkit for modern data science work. By mastering these tools — and keeping these references handy — you’ll be well-equipped to tackle a wide range of data science challenges, from data preparation and exploration to building predictive models. These cheat sheets aren’t just about syntax; they’re about understanding the core technologies that power today’s data-driven solutions.
Matthew Mayo (@mattmayo13) holds a master’s degree in computer science and a graduate diploma in data mining. As managing editor of KDnuggets & Statology, and contributing editor at Machine Learning Mastery, Matthew aims to make complex data science concepts accessible. His professional interests include natural language processing, language models, machine learning algorithms, and exploring emerging AI. He is driven by a mission to democratize knowledge in the data science community. Matthew has been coding since he was 6 years old.