

Image by Author | Ideogram
Interested or immersed in developing language models, and looking for strategies to ensure they work at their best? This article lists 5 tips, from the simplest tweaks to advanced optimization techniques, to help you maximize the performance of your language models.
Note: while some visuals in this article use the acronym LLM (Large Language Model), we use it to refer to the whole spectrum of language models.
1. Prompt Engineering
Prompt engineering is often the starting point in improving language model outputs without the need for directly modifying the model. It aims to get more precise responses by adjusting the formulated questions (prompts), and following specific techniques and strategies. Writing clear instructions, accompanying them with examples of the desired outcome, and breaking down a complex request into simpler ones, are some of the most common prompt engineering best practices.
This is an example of a very short yet clear prompt:
Define 'democracy' in one sentence for a high school student.
Response:
Democracy is a system of government where citizens choose their leaders through free elections.
This example is more concise while still demonstrating key prompt engineering principles:
Clear, specific task (define democracy)
Strict constraint (one sentence)
Defined audience (high school student)
2. Retrieval Augmented Generation (RAG)
RAG is a ground-breaking approach to improve language models’ performance without necessarily modifying or re-training them. It focuses on enriching user prompts with additional context information automatically extracted by an information retrieval engine, called retriever. The retriever can access a document base to retrieve relevant context knowledge that helps the language model generate a truthful and more accurate response, preventing issues like hallucinations or model obsolescence due to a lack of up-to-date knowledge about a topic.
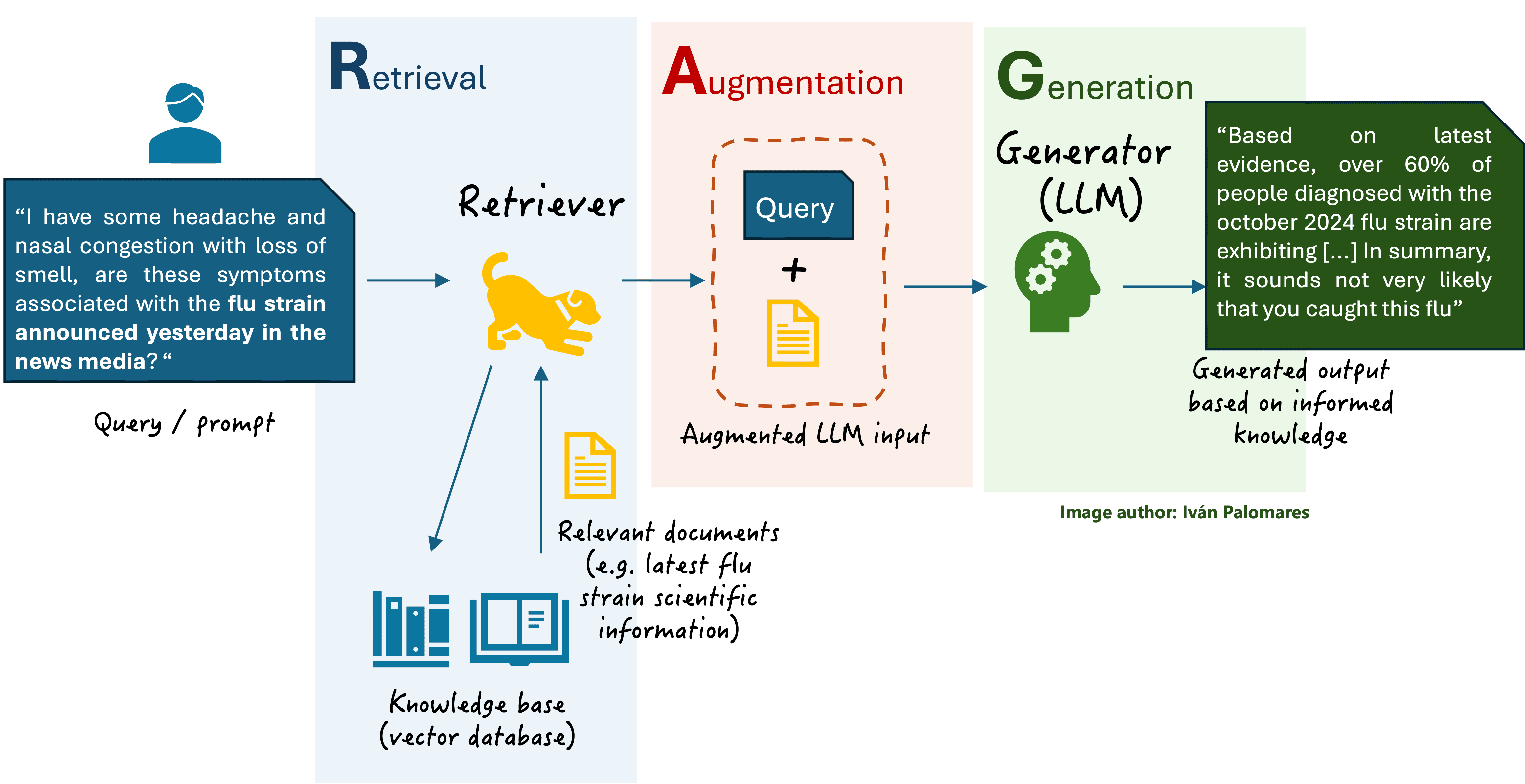
General RAG scheme
3. Fine-tuning Your Model
After embracing prompt engineering and RAG, the next step to optimize your language model is personalizing and adapting it to your specific task or needs. This is the purpose of model fine-tuning, which consists of taking a pre-trained model, and training it once again on a smaller domain-specific dataset, so that model parameters are adjusted to specialize in addressing language tasks in that domain (for instance, for summarizing dentistry papers as shown below).
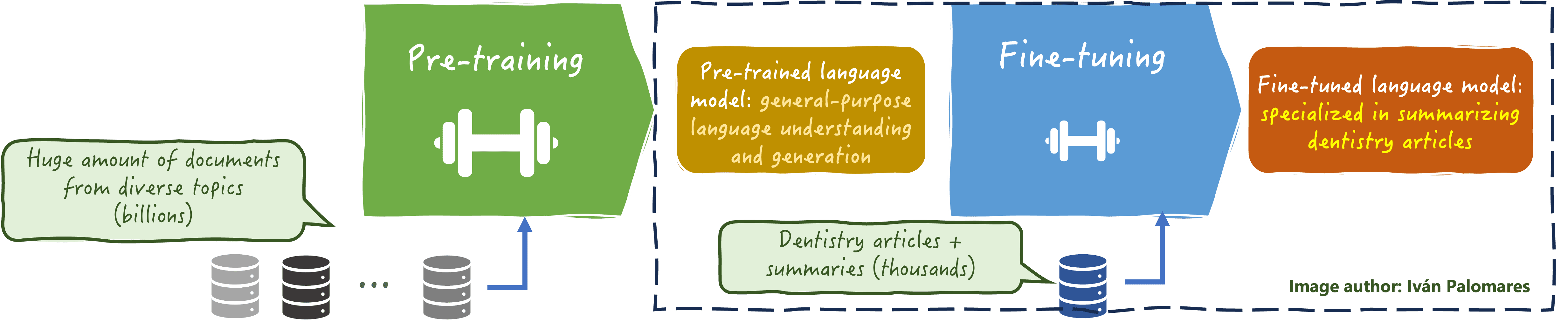
Fine-tuning a language model for domain-specific tasks
4. Hyperparameter Tuning
Besides personalizing your model by fine-tuning it, you can further optimize it by adjusting some key hyperparameters that may help enhance its performance, and precision, and reduce issues like overfitting. Common hyperparameters to play with in language models include the learning rate, batch size, number of training epochs, and dropout rate. However, fine-tuning these hyperparameters can be time-consuming and computationally intensive.
5. Model Compression and Pruning
The last and most advanced tip is compressing your language model, that is, reducing its size and parameter complexity. Compression helps make your model more accessible and feasible for real-life applications by reducing computational requirements and costs while trying to preserve its performance as much as possible. For example, techniques like pruning allow language models to operate on mobile devices with limited resources, improving inference efficiency and expanding the deployment capabilities of these models.
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.