
Image by Author
Look, data science is awesome. But you know what’s not? Waiting forever for your code to run. Whether it’s slow data loading, inefficient loops, or hyperparameter tuning that takes all night, these bottlenecks are killing your productivity. The good news? There are ways to fix this. Let’s talk about five solid techniques to make your workflow faster, smoother, and less frustrating.
Prerequisites
Before we get into it, you should already be comfortable with:
- Python (if you’re still struggling with for loops, we need another conversation)
- Jupyter Notebook or an IDE (unless you enjoy writing Python in Notepad, in which case… why?)
- Machine Learning Pipelines (you should know what preprocessing, feature engineering, and model evaluation are)
- Parallel Computing & Multi-threading (even just the basics—think multiprocessing, threading, or async execution)
- Git & Version Control (because losing your progress is a special kind of pain)
- GPU Acceleration (ever heard of CuPy? It’s like NumPy on steroids)
- Apache Arrow (not mandatory, but if you work with big data, this one’s worth knowing)
Data science is like an exciting journey full of new ideas, experiments, and sudden moments of clarity until something unusual happens, disrupting your progress. If you’ve ever sat there, watching a dataset load as slow as a snail or waited forever for a model to train, you know exactly what I mean.
Speeding things up isn’t about cutting corners. It’s about working smarter. The best data scientists don’t just build great models—they make sure every step of their process runs efficiently so they’re spending time solving problems, not waiting around for progress bars to inch forward.
This guide offers five ways to speed up and smooth down your workflow. Whether you are wrestling with dirty data, fine-tuning models, or automating boring tasks, these techniques will help you cut wasted time and focus on what really matters: attaining insight and creating an effect.
And if some of these conditions seem a bit frightening, do not stress. Think of adaptation like upgrading to a slow, screaming bike in a high-demonstration sports car. It’s the same destination—just fast and with less despair. Let’s do it.
1. Optimize Data Loading and Preprocessing
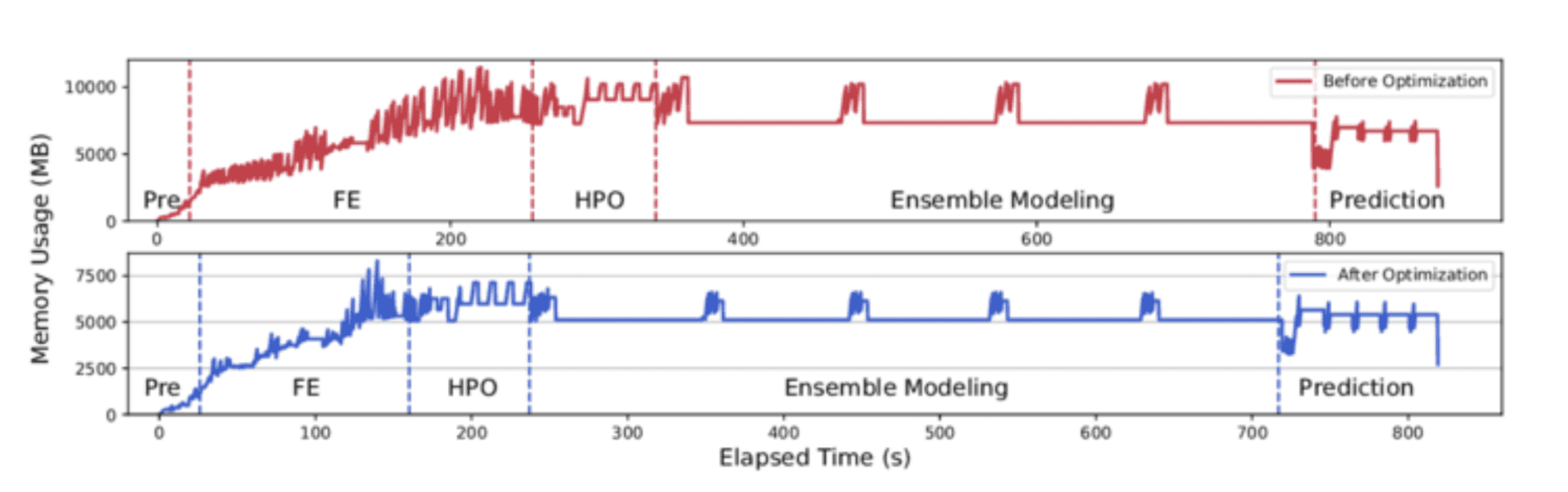
Credit: ResearchGate
The Problem
Big datasets mean big headaches. Slow loading, inefficient data types, and memory bloat can make even simple tasks a slog.
The Fix
Use pandas.read_csv() properly. Set data types, process data in chunks, and avoid loading unnecessary columns.
import pandas as pd
# Use specific data types to save memory
dtypes = {"column1": "int32", "column2": "float32"}
# Read with chunking for large files
chunksize = 10000
df_list = []
for chunk in pd.read_csv("large_file.csv", dtype=dtypes, chunksize=chunksize):
df_list.append(chunk)
df = pd.concat(df_list)
✅ Set dtypeto prevent memory bloat.
❌ Don’t just read_csv() without thinking—unless you enjoy crashes.
2. Leverage Vectorized Operations and Optimized Libraries
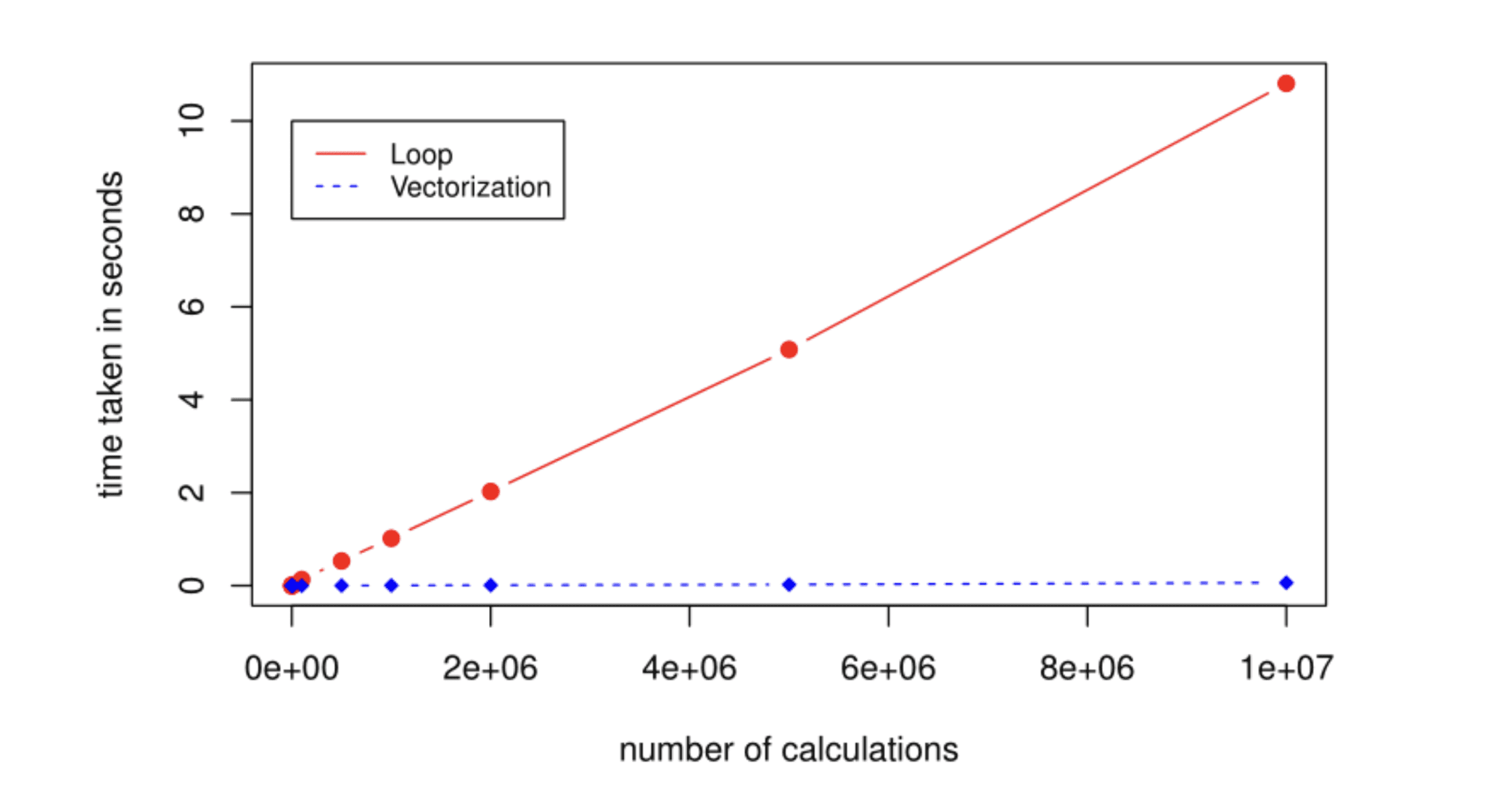
Credit: Ben’s Blog
A side-by-side comparison of loop-based vs. vectorized code performance
The Problem
Python loops are painfully slow.
The Fix
Use NumPy instead of loops.
import numpy as np
# Inefficient
squared = [i**2 for i in range(1000000)]
# Efficient
squared = np.arange(1000000) ** 2
✅ Use NumPy and Pandas to speed things up.
❌ Don’t loop through rows in Pandas. Ever.
3. Implement Parallel and Distributed Computing
Credit: PureStorage
The Problem
Your computer is working hard, but it’s only using one core.
The Fix
Use joblib to parallelize your code.
from joblib import Parallel, delayed
import time
def square(n):
time.sleep(1)
return n * n
numbers = range(10)
results = Parallel(n_jobs=4)(delayed(square)(n) for n in numbers)
print(results)
✅ Use Dask if your dataset is too big for memory.
❌ Don’t spawn too many processes or you’ll create chaos instead of speed.
4. Use Efficient Model Selection and Hyperparameter Tuning
The Problem
Grid search takes forever.
The Fix
Use RandomizedSearchCV instead of brute-force grid search.
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
param_dist = {"n_estimators": [10, 50, 100, 200], "max_depth": [None, 10, 20, 30]}
model = RandomForestClassifier()
random_search = RandomizedSearchCV(model, param_distributions=param_dist, n_iter=10, cv=5)
random_search.fit(X_train, y_train)
✅ Try Bayesian Optimization (Optuna).
❌ Don’t blindly use GridSearchCV unless you have unlimited time.
5. Automate Repetitive Tasks with Pipelines
The Problem
Manually repeating preprocessing steps is error-prone and boring.
The Fix
Use scikit-learn Pipelines.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', RandomForestClassifier(n_estimators=100))
])
pipeline.fit(X_train, y_train)
✅ Modularize your preprocessing.
❌ Don’t overcomplicate pipelines—keep them readable.
Bonus: Supercharge Performance with GPU Acceleration
The Problem
Even with good libraries, CPUs can still be very slow when handling large datasets or tricky calculations (I guess you’ll agree with me on this).
The Fix
Try CuPy—it’s like NumPy but way faster for NVIDIA GPUs. The best part? Switching from NumPy to CuPy is super easy.
import numpy as np
import cupy as cp
import time
size = (10000, 10000)
cpu_matrix = np.random.rand(*size)
gpu_matrix = cp.random.rand(*size)
# CPU computation (NumPy)
start = time.time()
cpu_result = np.dot(cpu_matrix, cpu_matrix)
end = time.time()
print(f"CPU time: {end - start:.4f} seconds")
# GPU computation (CuPy)
start = time.time()
gpu_result = cp.dot(gpu_matrix, gpu_matrix)
cp.cuda.Device(0).synchronize()
end = time.time()
print(f"GPU time: {end - start:.4f} seconds")
✅ Use CuPy for large matrix operations.
❌ Don’t use it for tiny datasets—the GPU transfer overhead cancels out speed gains.
Did You Know?
💡 Pandas + Modin lets you use multiple CPU cores. It’s like switching from a bicycle and now driving a sports car.
Common Mistakes
❌ Overusing loops instead of vectorized operations.
❌ Ignoring memory-efficient data types.
Conclusion
Optimizing your workflow isn’t about working harder—it’s about working smarter. Eliminate slow processes, use the right tools, and automate repetitive tasks to save time. Small tweaks can save you hours. Stay sharp, keep optimizing, and make your work feel effortless. Start applying these today, and watch your productivity soar.
References
Shittu Olumide is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.