
Image by Author | Created on Canva
If you’ve spent any time working with pandas in Python, you know that certain errors have a way of popping up just when you least expect them.
Understanding these common issues and their solutions speeds up your debugging process. Also, it helps you write more robust code from the start. In this article, we’ll look at such common pandas errors with simple examples.
Note: ▶️ If you’d like to see all the code in one place, here’s the Google Colab notebook for this tutorial.
Let’s start by importing the required libraries:
import pandas as pd
import numpy as np
1. DataFrame Merge Key Mismatches
Mismatched keys when merging dataframes is one of the most frequent errors you’ll run into.
In this example, we try to merge two dataframes where the customer ID columns had different names (“customer_id” vs “CustomerID”). If you try to merge, you’ll run into a KeyError exception:
# Create sample dataframes
sales_df = pd.DataFrame(
'customer_id': [101, 102, 103, 104],
'sale_amount': [1500, 2300, 1800, 3200]
)
customer_df = pd.DataFrame(
'CustomerID': [101, 102, 103, 105], # Note the different column name and slightly different data
'customer_name': ['Alice', 'Bob', 'Charlie', 'Eve']
)
try:
# This will raise an error
merged_df = sales_df.merge(customer_df, left_on='customer_id', right_on='customer_id')
except KeyError as e:
print("KeyError:", e)
The error occurs because pandas can’t find the matching column names:
Always check your column names using df.columns before merging. And then rename columns as needed for consistency.
You can also explicitly specify the columns on which to merge—the correct column names that is—using the left_on and right_on parameters:
merged_df = sales_df.merge(customer_df, left_on='customer_id', right_on='CustomerID')
This should give you:
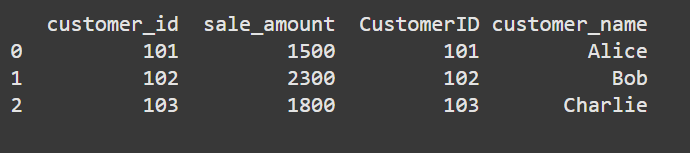
Though this works, I suggest renaming column “CustomerID” to “customer_id” for consistency.
By default, merge does an inner join so only those records with customer IDs that occur in both the dataframes appear in the merged dataframe.
If you want info on all the customer records, you can consider using an outer join so that the union of the keys appearing in both the dataframes is considered.
2. Mixed Data Types in Operations
Always check the data types of the different columns and make sure they’re of the right type.
Let’s take an example. Notice how our ‘value’ column contains strings, including ‘NA’:
# Create sample dataframe with mixed types
mixed_df = pd.DataFrame(
'value': ['100', '200', 'NA', '400', '500']
)
try:
# This will raise an error
result = mixed_df['value'].mean()
except TypeError as e:
print("TypeError:", e)
When we try to calculate the mean, Python throws a TypeError because we can’t average strings:
TypeError: Could not convert string '100200NA400500' to numeric
Always check your column types using df.dtypes. And to fix such errors, convert values to numeric values using pd.to_numeric() with errors="coerce" to handle non-numeric values gracefully.
mixed_df['value'] = pd.to_numeric(mixed_df['value'], errors="coerce")
result = mixed_df['value'].mean()
If you print out the result variable, you’ll see:
3. DataFrame View vs. Copy (The SettingWithCopyWarning)
The SettingWithCopyWarning often confuses even experienced developers. It happens when you try to modify a view of a dataframe rather than a copy. This is super common when you have chained assignments.
The issue is that pandas cannot guarantee whether the operation will affect the original data or not. Let’s take a simple example:
# Create sample dataframe
data = pd.DataFrame(
'category': ['A', 'A', 'B', 'B', 'C'],
'value': [1, 2, 3, 4, 5]
)
# This will trigger a warning
subset_data = data[data['category'] == 'A']
subset_data['value'] = subset_data['value'] * 2
To learn more about this warning, read Returning a- view- vs. a copy and SettingWithCopyWarning.

To fix this, explicitly create a copy using .copy() when you’re working with a subset of your data like so:
subset_data = data[data['category'] == 'A'].copy()
subset_data['value'] = subset_data['value'] * 2
4. NaN Propagation in Calculations
When you have one or more numeric columns, you have to spend time handling NaN entries when cleaning the dataset. This is particularly tricky because it might not raise an error at all – it just silently propagates NaN values through your calculations.
In our example, any calculation involving NaN will result in NaN:
# Create sample dataframe with NaN values
finance_df = pd.DataFrame(
'revenue': [1000, 2000, np.nan, 4000],
'costs': [500, np.nan, 1500, 2000]
)
# This will give unexpected results
profit = finance_df['revenue'] - finance_df['costs']
Without handling those np.nans, you’ll get:
0 500.0
1 NaN
2 NaN
3 2000.0
dtype: float64
Depending on the specific dataset, you might want to fill NaN values with 0, interpolate them, or drop them entirely:
profit = finance_df['revenue'].fillna(0) - finance_df['costs'].fillna(0)
This should give the following profit values:
0 500.0
1 2000.0
2 -1500.0
3 2000.0
dtype: float64
5. Index Alignment Issues
When operating on multiple dataframes, pandas tries to align indexes automatically. This can lead to unexpected results or errors when indexes don’t match.
# Create sample dataframes with different indices
df_1 = pd.DataFrame('value': [1, 2, 3], index=['A', 'B', 'C'])
df_2 = pd.DataFrame('value': [4, 5, 6], index=['B', 'C', 'D'])
try:
result = df_1['value'] + df_2['value']
except Exception as e:
print("Exception:", e)
This might give unexpected results:
A NaN
B 6.0
C 8.0
D NaN
Name: value, dtype: float64
You should always check your index values using df.index before operations.
Also, you can use methods like .add() with fill_value parameter instead of simple operators.
result = df_1['value'].add(df_2['value'], fill_value=0)
This should give the expected output:
A 1.0
B 6.0
C 8.0
D 6.0
Name: value, dtype: float64
6. Memory Issues with Large DataFrames
While not strictly an error, this is a common performance issue. Creating multiple copies of large dataframes is inefficient.
Here’s an example:
def processing_func():
# Create a large dataframe (this is a small example)
big_df = pd.DataFrame(np.random.randn(1000000, 10))
# Inefficient way (creates multiple copies)
processed_df = big_df
for col in big_df.columns:
processed_df = processed_df[processed_df[col] > 0]
return processed_df
A better way to do this is to chain operations where possible:
def a_better_processing_func():
# Create a large dataframe (this is a small example)
big_df = pd.DataFrame(np.random.randn(1000000, 10))
# Efficient solution (chain operations)
mask = (big_df > 0).all(axis=1)
processed_df = big_df[mask]
return processed_df
You can also monitor memory usage of each column using the memory_usage() method.
Wrapping Up
We’ve gone over the most frequent pandas errors/challenges that data scientists face in their day-to-day work. We’ve seen how to:
- Handle tricky merge operations where column names don’t quite match up
- Work with mixed data types that can break our calculations
- Use dataframe views vs. copies
- Handle NaN values
- Manage memory when working with large datasets
Most importantly, we’ve looked at why these errors occur and how to spot them before they become major issues. I hope you found this helpful. Happy data analysis! 🙂
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she’s working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.