
DeepSeek’s R1 model has disrupted the LLM landscape by enabling more thoughtful reasoning without requiring human feedback. The key behind this breakthrough is Group Relative Policy Optimization (GRPO)—a reinforcement learning technique that helps models develop reasoning capabilities autonomously. Unlike Proximal Policy Optimization (PPO), which relies on a value function, GRPO optimizes responses without requiring one, making it more efficient.
The race to develop better reasoning models is in full swing. But what about those of us with limited GPU resources?
Thanks to Unsloth, training a 15B parameter model on consumer-grade GPUs with just 15GB VRAM is now possible. This guide will show you how to train your own reasoning-focused model using GRPO in a few steps.
What is GRPO?
GRPO helps AI models learn to think better by comparing their answers. Here’s how it works:
- The model writes multiple answers to a question.
- Each answer gets a score (like points for being correct, clear, following structure etc).
- The scores are averaged and each response is compared against this average.
- Answers that beat the average score get rewarded.
- The model learns to make more high-scoring answers over time.
For example, to teach math:
- Ask: “What is 2+2?”
- The model might write: “2+2=5” (wrong) or “2+2=4” (right).
GRPO rewards the correct answer, so the model learns to avoid mistakes. This technique allows models to develop structured reasoning without requiring massive labeled datasets.
Step-by-Step Guide to Train Your Own Reasoning Model
This guide walks through training a reasoning-optimized LLM using GRPO and deploying it on Hugging Face. We will be using meta-llama/meta-Llama-3.1-8B-Instruct for this article and the reference notebook provided by unsloth that you can access here.
Step 1: Environment Setup
Install Dependencies using the following code:
%%capture
# Install base packages
!pip install unsloth vllm
!pip install --upgrade pillow
# Install specific TRL version for GRPO support
!pip install git+https://github.com/huggingface/trl.git@e95f9fb74a3c3647b86f251b7e230ec51c64b72b
Key Components:
- unsloth: Optimized training framework
- vllm: High-throughput inference engine
- trl: Transformer Reinforcement Learning library
Step 2: Model Initialization
Use PatchFastRL before all functions to patch GRPO and other RL algorithms. This step ensures that the model is optimized for RL tasks by integrating specific algorithm improvements into FastLanguageModel. Then load up Llama 3.1 8B Instruct with following parameters and apply lora adaptation.
from unsloth import FastLanguageModel, PatchFastRL, is_bfloat16_supported
import torch
# Enable GRPO patches
PatchFastRL("GRPO", FastLanguageModel)
# Configuration
max_seq_length = 512 # Increase for complex reasoning chains
lora_rank = 32 # Balance between capacity and speed
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "meta-llama/meta-Llama-3.1-8B-Instruct",
max_seq_length = max_seq_length,
load_in_4bit = True, # False for LoRA 16bit
fast_inference = True, # Enable vLLM fast inference
max_lora_rank = lora_rank,
gpu_memory_utilization = 0.6, # Reduce if out of memory
)
model = FastLanguageModel.get_peft_model(
model,
r = lora_rank, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
], # Remove QKVO if out of memory
lora_alpha = lora_rank,
use_gradient_checkpointing = "unsloth", # Enable long context finetuning
random_state = 3407,
)
Key Parameters:
- load_in_4bit: Reduces memory usage by 4x (Quantization)
- fast_inference: Enables vLLM’s attention optimizations
- gpu_memory_utilization: Controls VRAM allocation buffer (60% in this case)
- r = lora_rank: Controls how much LoRA adaptation is allowed. We have set it to 32 ( Larger rank = smarter, but slower)

Step 3: Dataset Preparation
In this step, we prepare a dataset that trains our model to reason step-by-step before producing an answer. The dataset format is important, as it influences how the model structures its responses. The base notebook originally uses GSM8K (Grade School Math 8K), a dataset of 8.5K grade school math word problems requiring multi-step reasoning. However, we will be using a different dataset that provides a broader reasoning coverage across multiple domains that you can find here – KingNish/reasoning-base-20k.
Data Fields:
- user: The user’s query or problem statement.
- assistant: The correct answer to the problem.
- reasoning: A detailed, step-by-step reasoning process that explains how to arrive at the correct answer.
- template: A preapplied RChatML chat template
We format the dataset using a structured response template to ensure our model learns to separate reasoning from the final answer.
import re
from datasets import load_dataset, Dataset
from difflib import SequenceMatcher
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
reasoning
</reasoning>
<answer>
answer
</answer>
"""
Now, load the Reasoning Base 20K dataset.
def get_reasoning_questions(split="train") -> Dataset:
data = load_dataset("KingNish/reasoning-base-20k", split=split)
data = data.map(lambda x:
"prompt": [
"role": "system", "content": SYSTEM_PROMPT,
"role": "user", "content": x["user"]
],
"reasoning": x["reasoning"],
"answer": x["assistant"]
)
return data
# Load dataset
dataset = get_reasoning_questions()

Step 4: Reward Function Design – Most Important
Reward functions are crucial in training a reasoning-optimized model as they guide the model what “good” performance means. The right reward design ensures that the model generates logically sound, well-formatted, and high-quality responses. Our dataset requires a different approach than GSM8K, as our responses contain detailed reasoning steps rather than just a numeric answer. Hence, our reward function evaluates multiple aspects:
- Content Quality → Semantic alignment with reference answers
- Structural Compliance → XML-style formatting
- Process Quality → Complexity of reasoning steps
In the sample code below, you will find several reward functions—each focuses on a different aspect of the response. Below is a closer look at these functions:
1. Answer Relevance Reward
This function measures how well the model’s response covers key terms in both the question prompt and a reference answer (if available). This ensures that the model at least mentions or addresses critical topics from the question.
- Extracts key terms from question, response, and reference answer.
- If >30% of question terms appear in response, it adds 0.5 to the score.
- If >30% of reference answer terms appear in response, it adds 0.5 to the score.
- Ensures the model answers the question correctly and logically.
def answer_relevance_reward(prompts, completions, answer, **kwargs) -> list[float]:
responses = [completion[0]["content"] for completion in completions]
questions = [prompt[-1]["content"] for prompt in prompts]
def check_relevance(response, question, reference):
score = 0.0
# Extract key terms from question
question_terms = set(question.lower().split())
response_terms = set(response.lower().split())
reference_terms = set(reference.lower().split())
# 1) Check if response addresses key terms from question
if len(question_terms) > 0:
common_qr = question_terms.intersection(response_terms)
if len(common_qr) / len(question_terms) > 0.3:
score += 0.5
# 2) Check if response uses similar key terms as reference
if len(reference_terms) > 0:
common_rr = response_terms.intersection(reference_terms)
if len(common_rr) / len(reference_terms) > 0.3:
score += 0.5
return score
return [check_relevance(r, q, a) for r, q, a in zip(responses, questions, answer)]
2. Strict Format Compliance Reward
This function ensures that the output strictly follows the required XML-style structure to maintain consistent output formatting for structured reasoning. Rewards 0.5 if the format is correct, else 0.0.
def strict_format_reward_func(completions, **kwargs) -> list[float]:
pattern = r"^\n.*?\n \n\n.*?\n \n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r, flags=re.DOTALL) for r in responses]
return [0.5 if match else 0.0 for match in matches]
3. Soft Format Compliance Reward
A more flexible reward function that allows minor deviations but still requires proper XML-style formatting. Also awards 0.5 points if matched, else 0.0. This can be helpful if the strict format is too rigid and might penalize small differences that do not affect usability.
def soft_format_reward_func(completions, **kwargs) -> list[float]:
pattern = r".*? \s*.*? "
responses = [completion[0]["content"] for completion in completions]
matches = [re.search(pattern, r, re.DOTALL) for r in responses]
return [0.5 if match else 0.0 for match in matches]
4. XML Tag Count Reward (Heuristic Example)
This function evaluates how well the response adheres to expected XML structure by counting required tags. It penalizes if extra content appears after and provides partial credit instead of binary rewards.
def count_xml(text) -> float:
count = 0.0
if text.count("\n") == 1:
count += 0.125
if text.count("\n \n") == 1:
count += 0.125
if text.count("\n\n") == 1:
count += 0.125
count -= len(text.split("\n \n")[-1]) * 0.001
if text.count("\n") == 1:
count += 0.125
count -= (len(text.split("\n")[-1]) - 1) * 0.001
return count
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]
In practice, you often want to combine some or all of these different signals for the final reward score calculation. The original notebook employed int and correctness reward functions, as the dataset contained single numerical answers. However, given our general reasoning model, a broader evaluation approach is necessary. Hence, we used the following reward functions:
reward_funcs = [
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
answer_relevance_reward
]
Step 5: GRPO Training Configuration & Execution
Now, set up the GRPO Trainer and all configurations. I have reduced max_steps from 250 to 150 to save time and decreased num_generations from 6 to 4 to conserve memory. However, Unsloth recommends running for at least 300 steps to observe significant improvement. All other configurations remain the same and are as follows:
from trl import GRPOConfig, GRPOTrainer
training_args = GRPOConfig(
use_vllm = True, # use vLLM for fast inference!
learning_rate = 5e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.1,
lr_scheduler_type = "cosine",
optim = "paged_adamw_8bit",
logging_steps = 1,
bf16 = is_bfloat16_supported(),
fp16 = not is_bfloat16_supported(),
per_device_train_batch_size = 1,
gradient_accumulation_steps = 1, # Increase to 4 for smoother training
num_generations = 4, # Decrease if out of memory
max_prompt_length = 256,
max_completion_length = 200,
# num_train_epochs = 1, # Set to 1 for a full training run
max_steps = 150,
save_steps = 150,
max_grad_norm = 0.1,
report_to = "none", # Can use Weights & Biases
output_dir = "outputs",
)
Now, let’s initialize and run the GRPO Trainer:
trainer = GRPOTrainer(
model = model,
processing_class = tokenizer,
reward_funcs = reward_funcs,
args = training_args,
train_dataset = dataset,
)
trainer.train()
The training logs provide insights into reward trends, loss values, and response quality improvements. Initially, rewards fluctuate due to random exploration, but they gradually improve over time. It took me approximately 2 hours and 7 minutes to run this notebook on a Colab T4 GPU, and the final training loss after 150 steps was 0.0003475.
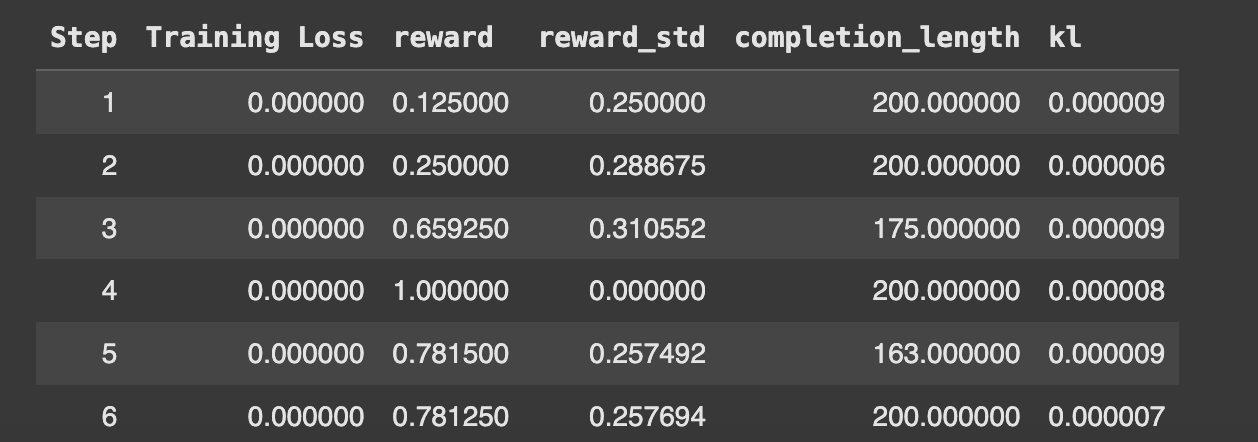
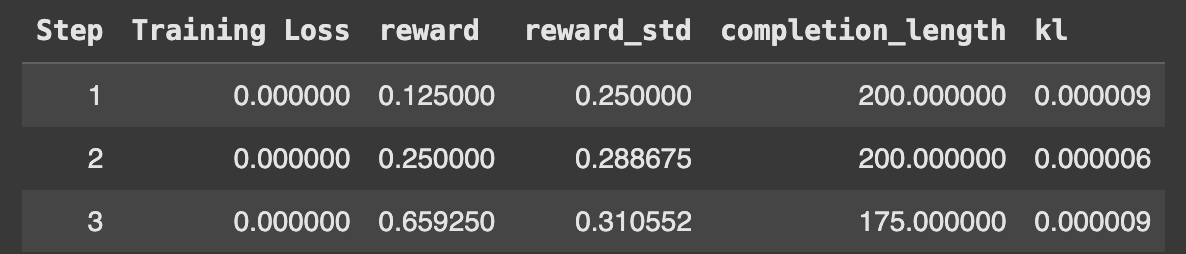
Step 6: Model Evaluation
Now that we have trained the model, let’s compare the performance of the baseline LLaMA 3.1 8B Instruct with the GRPO-trained model.
Before GRPO Training
text = tokenizer.apply_chat_template([
"role" : "user", "content" : "How many r's are in strawberry?",
], tokenize = False, add_generation_prompt = True)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
[text],
sampling_params = sampling_params,
lora_request = None,
)[0].outputs[0].text
output
Output:
There are 2 'r's in the word "strawberry".
The baseline model incorrectly identifies the number of ‘r’s in “strawberry,” highlighting a gap in factual reasoning.
After GRPO Training
Now we load the LoRA and test:
model.save_lora("grpo_saved_lora")
text = tokenizer.apply_chat_template([
"role" : "system", "content" : SYSTEM_PROMPT,
"role" : "user", "content" : "How many r's are in strawberry?",
], tokenize = False, add_generation_prompt = True)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
text,
sampling_params = sampling_params,
lora_request = model.load_lora("grpo_saved_lora"),
)[0].outputs[0].text
output
Output:
<reasoning>
To determine the number of 'r's in the word "strawberry," we need to spell it out and count the occurrences of 'r'. The word "strawberry" is spelled as S-T-R-A-W-B-E-R-R-Y. The letter 'r' appears in the 3rd, 8th, and 9th positions.
</reasoning>
<answer>
There are 3 'r's in the word "strawberry."
</answer>
After GRPO training, the model shows improved accuracy and reasoning but is still not perfect. Since it was trained for only 2 hours on a T4 GPU, extending the sequence length and training time would further enhance its performance.
Step 7: Deployment & Scaling
Once the model has been fine-tuned and evaluated, the next step is deploying it for real-world use and ensuring it can scale efficiently. Deployment involves converting the model into an optimized format, integrating it into an inference server, and making it accessible through an API or application. To ensure efficient inference, we save the trained LoRA adapters and push them to Hugging Face Hub for easy access. This allows others to load the fine-tuned model without needing extensive computational resources.
# Just LoRA adapters
if True: model.save_pretrained_merged("model", tokenizer, save_method = "lora",)
if True: model.push_to_hub_merged("kanwal-mehreen18/Llama3.1-8B-GRPO", tokenizer, save_method = "lora", token = "YOUR_HF_KEY")
Saved lora model to https://huggingface.co/kanwal-mehreen18/Llama3.1-8B-GRPO.
Best Practices by Unsloth
- Use models >1.5B parameters for reliable reasoning
- Train for minimum 12 hours for complex tasks
- Combine multiple reward signals (3-5 functions ideal)
Kanwal Mehreen Kanwal is a machine learning engineer and a technical writer with a profound passion for data science and the intersection of AI with medicine. She co-authored the ebook “Maximizing Productivity with ChatGPT”. As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She’s also recognized as a Teradata Diversity in Tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having founded FEMCodes to empower women in STEM fields.