
Understanding RAG Part IX: Fine-Tuning LLMs for RAG
Image by Editor | Midjourney & Canvas
Be sure to check out the previous articles in this series:
In previous articles of the Understanding RAG series, which focuses on various aspects of retrieval augmented generation, we put the lens on the retriever component that is integrated with a large language model (LLM) to retrieve meaningful and truthful context knowledge to enhance the quality of LLM inputs and, consequently, its generated output response. Concretely, we learned how to manage the length of the context passed to the LLM, how to optimize retrieval, and how vector databases and indexing strategies work to retrieve knowledge effectively.
This time, we will shift our attention to the generator component, that is, the LLM, by investigating how (and when) to fine-tune an LLM inside an RAG system to ensure its responses keep being coherent, factually accurate, and aligned with domain-specific knowledge.
Before moving on to understanding the nuances of fine-tuning an LLM that is part of an RAG system, let’s recap the notion and process of fine-tuning in “conventional” or standalone LLMs.
What is LLM Fine-Tuning?
Just like a newly purchased cellphone is tuned with personalized settings, apps, and a decorative case to suit the preferences and personality of its owner, fine-tuning an existing (and previously trained) LLM consists of adjusting its model parameters using additional, specialized training data to enhance its performance in a specific use case or application domain.
Fine-tuning is an important part of LLM development, maintenance, and reuse, for two reasons:
- It allows the model to adapt to a more domain-specific, often smaller, dataset, improving its accuracy and relevance in specialized areas such as legal, medical, or technical fields. See the example in the image below.
- It ensures the LLM stays up-to-date on evolving knowledge and language patterns, avoiding issues like outdated information, hallucinations, or misalignment with current facts and best practices.
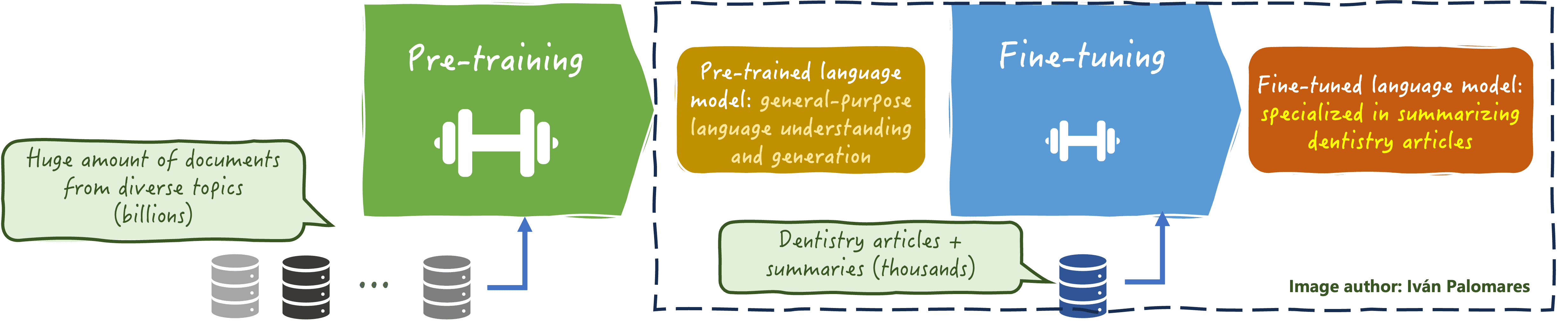
LLM fine-tuning
The downside of keeping an LLM updated by periodically fine-tuning all or some of its parameters is, as you might guess, the cost, both in terms of acquiring new training data and the computational resources required. RAG helps reduce the need for constant LLM fine-tuning. However, fine-tuning the underlying LLM to an RAG system remains beneficial in certain cases.
LLM Fine-Tuning in RAG Systems: Why and How?
While in some application scenarios, the retriever’s job of extracting relevant, up-to-date information for building an accurate context is enough to not need periodical LLM retraining, there are more concrete cases where this is not sufficient.
One example is when your RAG application requires a very deep and ambitious understanding of specialized jargon or domain-specific reasoning not captured through the LLM’s original training data. This could be a RAG system in the medical domain, where it may do a great job in retrieving relevant documents, but the LLM may struggle in correctly interpreting pieces of knowledge in the input before being fine-tuned on specific datasets that contain useful information to assimilate such domain-specific reasoning and language interpretation mechanisms.
A balanced fine-tuning frequency on your RAG system’s LLM could also help improve system efficiency, for instance by reducing excessive token consumption and consequently avoiding unnecessary retrieval.
How does LLM fine-tuning take place from the perspective of RAG? While most of the classical LLM fine-tuning can also applied to the RAG system, some approaches are particularly popular and effective in these systems.
Domain-Adaptive Pre-training (DAP)
Despite its name, DAP can be used as an intermediate strategy between general model pretraining and task-specific fine-tuning of base LLMs inside RAG. It consists in utilizing a domain-specific corpus to have the model gain a better understanding of a certain domain, including jargon, writing styles, etc. Unlike conventional fine-tuning, it may still use a relatively large dataset, and it often is done before integrating the LLM with the rest of the RAG system, after which more focused and task-specific fine-tuning on smaller datasets would take place instead.
Retrieval Augmented Fine-Tuning
This is an interested and more RAG-specific fine-tuning strategy, whereby the LLM is specifically retrained on examples that incorporate both the retrieved context — augmented LLM input — and the desired response. This makes the LLM more skilled at leveraging and optimally utilizing retrieved knowledge, generating responses that will better integrate that knowledge. In other words, through this strategy, the LLM gets more skilled in properly using the RAG architecture it sits on.
Hybrid RAG Fine-Tuning
Also called hybrid instruction-retrieval fine-tuning, this approach combines traditional instruction fine-tuning (training an LLM to follow instructions by exposing it to examples of instruction-output pairs) with retrieval methods. In the dataset used for this hybrid strategy, two types of examples coexist: some include retrieved information whereas others contain instruction-following information. The result? A more flexible model that can make better use of retrieved information and also follow instructions properly.
Wrapping Up
This article discussed the LLM fine-tuning process in the context of RAG systems. After revisiting fine-tuning processes in standalone LLMs and outlining why it is needed, we shifted the discussion to the necessity of LLM fine-tuning in the context of RAG, describing some popular strategies often applied to fine-tune the generator model in RAG applications. Hopefully this is information you can use moving forward with your own RAG system implementation.