
Sponsored Content
Image by Author
Most data science happens after the fact, working with static datasets that reflect what’s already happened. But data in the real world is continuous. Clicks, transactions, sensor updates, and reviews, these all arrive in real time, not in batches.
To work with that kind of data, you need a different approach.
This guide introduces data streaming from a data science perspective. We’ll explain what it is, why it matters, and how to use tools like Apache Kafka, Apache Flink, and PyFlink to build real-time pipelines. Along the way, we’ll walk through examples like anomaly detection and review analysis using foundation models like GPT-4.
If you’re curious about how to bring your work closer to the data, and the decisions it drives, this is a practical place to start.
What Is Data Streaming and Why Should Data Scientists Care?
Data streaming is the practice of processing data continuously as it’s generated. Instead of waiting for a batch of data to arrive, you handle each event, each click, message, or update, as it comes in.
This shift matters because more data is being generated in real time. Think of:
- A user browsing a website, every click, scroll, or search is a signal.
- A payment processor flagging suspicious transactions as they happen.
- A fleet of delivery trucks sends GPS and sensor data every second.
- A chatbot agent adapting its behavior based on live feedback from users.
For data scientists, this opens up new opportunities. You can build models that react to the present. You can deploy analytics that surface insights instantly. You can support AI systems that depend on timely, context-rich data.
Streaming isn’t a replacement for batch processing, it’s a complement. Use it when low latency, high frequency, or continuous monitoring is critical. For long-term trend modeling or large-scale historical training, batch still works well.
That said, streaming unlocks some things that batch simply can’t do. There are three high-impact areas for ML workflows:
- Online predictions: Instead of generating recommendations or predictions every few hours in a batch, you can generate them on the fly. For example, an e-commerce site can compute real-time discounts based on what a user is browsing right now.
- Real-time monitoring: Rather than waiting for a batch job to flag issues with a model, you can compute metrics on live data, reducing your time for detection and response. This is especially valuable after deploying new models.
- Continual learning: You may not be updating models every hour, but if you’re collecting fresh data in real time, streaming helps shorten feedback loops, test retraining iterations, and evaluate updated models on the fly.
Streaming systems also allow for stateful processing, which avoids re-processing the same data over and over.
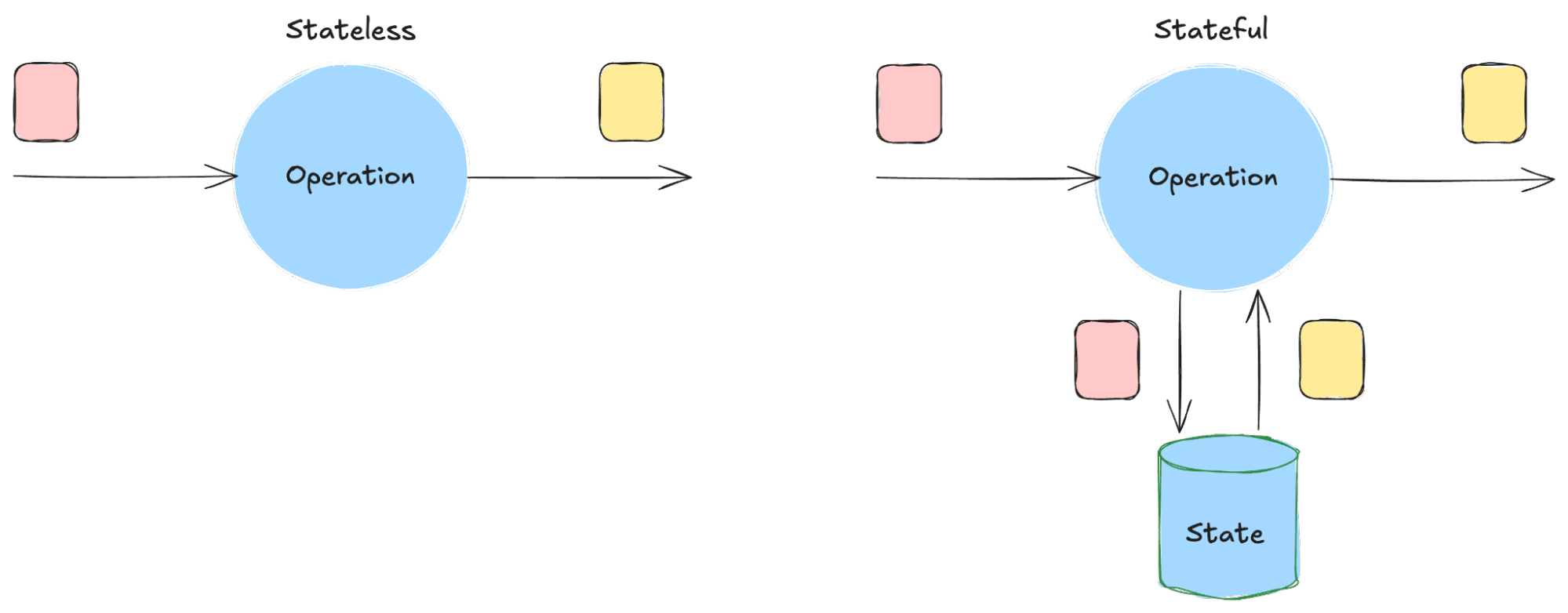
Stateless Processing versus Stateful Processing
For example, if you’re calculating a user’s average cart value over the past 30 minutes, you don’t need to start from scratch each time. The system remembers where it left off. This is faster, cheaper, and scales better than stateless compute like serverless functions or ad hoc batch jobs.
The Tools Behind Streaming: Apache Kafka and Apache Flink
Two technologies have become the foundation of most real-time data systems:
- Apache Kafka is a distributed event streaming platform. It lets you publish and subscribe to streams of events, store them reliably, and process them as they arrive. It’s the backbone for moving data between systems in real time.
- Apache Flink is a stream processing engine. It’s designed to handle continuous, unbounded data and supports both low-level event processing and high-level analytics. Flink can process millions of events per second with exactly-once guarantees and low latency.
Together, Kafka and Flink form the core of modern streaming architecture. Kafka handles data ingestion and transport; Flink handles computation and analysis.

Typical Streaming Pipeline
In a typical streaming pipeline, Kafka ingests data from upstream systems (like websites or IoT devices), and Flink subscribes to those topics to run analytics or model inference. Processed data is then pushed downstream into new Kafka topics, databases, or dashboards.
Where Streaming Already Delivers Value
Many of the world’s most data-driven companies already rely on streaming to drive customer experiences in real time.
- Netflix uses Kafka as the backbone of its personalization engine. Every click, pause, and playback feeds into Kafka Streams that help refine what each user sees next.
- Pinterest also relies on Kafka and stream processing to power its recommendation engine. As users engage with content, their most recent actions are processed in real time, enabling Pinterest to surface new, relevant pins within seconds. Stateful processing lets Pinterest keep track of context across sessions and actions, not just react to isolated events.
These are just two examples, but the pattern applies broadly.
Meet PyFlink: Stream Processing with Python
Flink is a powerful tool, but like many tools in the data engineering world, it’s written in Java and Scala. That’s where PyFlink comes in. It’s the Python API for Apache Flink, making it accessible to data scientists and Python developers.
With PyFlink, you can build powerful streaming pipelines without leaving the Python ecosystem.
Flink exposes two main APIs:
- Table API: A high-level, SQL-like abstraction ideal for working with structured data. Great for filtering, aggregating, and joining streams in a declarative way.
- DataStream API: A lower-level, more flexible API that gives you fine-grained control over event handling and processing. Best when you need to apply custom logic or integrate with ML models.
For data scientists, this flexibility is key. You might use the Table API to join a stream of customer clicks with product metadata. Or you might use the DataStream API to apply an anomaly detection model to sensor data in real time.
Flink is especially well-suited for AI use cases because it can process massive volumes of data with low latency and high fault tolerance, critical for real-time inference, monitoring, and feedback loops. It supports exactly-once guarantees, dynamic scaling, and native state management, making it a strong choice for building AI pipelines.
Industries like finance, e-commerce, manufacturing, and logistics already rely on Flink to power real-time decisioning systems from fraud detection and recommendation engines to predictive maintenance and supply chain alerts.
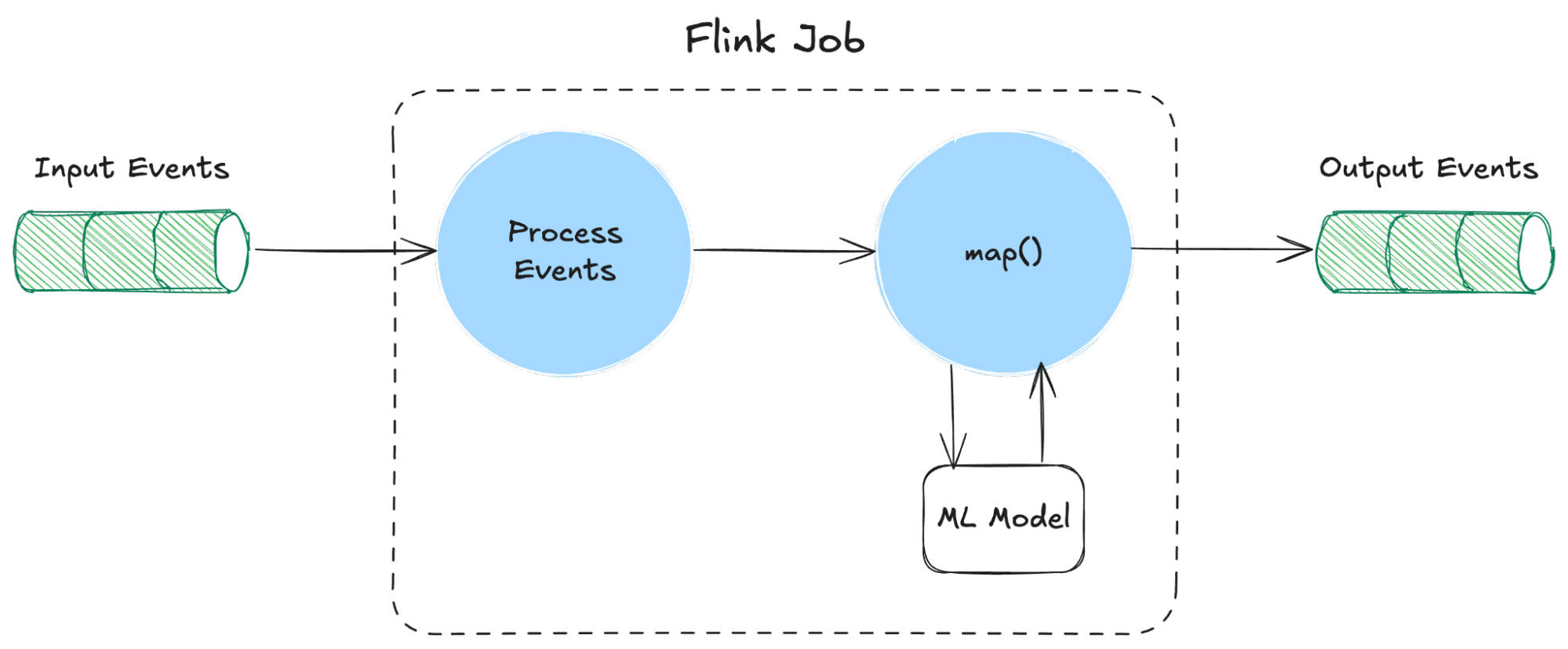
Example Flow for Real-time Monitoring or Online Prediction
Let’s walk through a simple example of anomaly detection using the DataStream API.
Example: Real-Time Anomaly Detection with PyFlink and Kafka
Suppose we have a Kafka topic streaming sensor data from a factory. Each message contains a device_id, a timestamp, and a temperature reading. We want to detect temperature anomalies in real time and write flagged events to another Kafka topic for alerting or further analysis.
Here’s a minimal PyFlink pipeline that reads from Kafka, flags temperature anomalies, and writes them to a downstream topic (see here for the full source).
First, define a simple anomaly detection function:
def detect_anomalies(event_str):
try:
event = clean_and_parse(event_str)
temperature = float(event.get('temperature', 0))
if temperature > 100: # simple threshold for demo
event['anomaly'] = True
return json.dumps(event)
except Exception:
pass
return None
Then, set up your streaming environment:
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
Create a Kafka source to read incoming events:
source = KafkaSource.builder() \
.set_bootstrap_servers(confluent_config.get("bootstrap.servers")
) \
.set_topics("sensor_data") \
.set_properties(confluent_config) \
.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
ds = env.from_source(source, WatermarkStrategy.for_monotonous_timestamps(), "Kafka Source")
Define a Kafka sink for flagged anomalies:
sink = KafkaSink.builder() \
.set_bootstrap_servers(confluent_config.get("bootstrap.servers")
) \
.set_record_serializer(
KafkaRecordSerializationSchema.builder()
.set_topic("sensor_anomalies")
.set_value_serialization_schema(SimpleStringSchema())
.build()
) \
.set_delivery_guarantee(DeliveryGuarantee.AT_LEAST_ONCE) \
.set_property("security.protocol", confluent_config.get("security.protocol")) \
.set_property("sasl.mechanism", confluent_config.get("sasl.mechanism")) \
.set_property("sasl.jaas.config", confluent_config.get("sasl.jaas.config")) \
.build()
Apply the transformation and send anomalies to the sink:
anomalies_stream = ds.map(detect_anomalies, output_type=Types.STRING()) \
.filter(lambda x: x is not None)
anomalies_stream.sink_to(sink)
env.execute()
What’s Happening Here
This pipeline processes each event as it arrives, detects anomalies in real time, and routes them downstream. The example above is extremely simple, but swap in a proper ML model (e.g., outlier detection with scikit-learn), add state, or route the output to a monitoring system, it all builds on this same pattern.
Let’s look at another, more complex example.
Example: Real-Time Thematic Analysis of Product Reviews with GPT-4
Understanding what customers are saying, at scale and in real time, has always been a hard problem. Traditional approaches to sentiment or topic analysis rely on batch pipelines: collect reviews, clean them, run models offline, and then generate reports. By the time insights surface, the moment has passed.
But with streaming infrastructure and models like GPT-4, we can do this differently. We can analyze reviews as they arrive, extract themes immediately, and categorize them for real-time dashboards or alerts.
Here’s why real-time matters:
- Faster feedback loops: Catch product issues or customer pain points as soon as they emerge.
- Smarter personalization: Adjust recommendations based on the latest feedback.
- Operational awareness: Alert product, support, or marketing teams to spikes in specific themes (e.g., “battery life,” “delivery issues,” “customer service”).
Let’s say customer reviews are being pushed into a Kafka topic. We can build a PyFlink pipeline that reads each review, passes it through GPT-4 to extract themes, and writes the structured results to another stream or analytics store. We can also process the aggregated themes to identify trends in real-time.
Step 1: Extract Themes with GPT-4
Let’s first define functions to extract the themes from the incoming Kafka product review events (see here for the full source):
def extract_themes(review_text):
try:
client = OpenAI(api_key=open_ai_key)
chat_completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "user", "content": f"""Identify key themes in this product review: {review_text}
Return a JSON array of themes"""}
]
)
content = chat_completion.choices[0].message.content
logging.info(f"OpenAI API call successful: {content}")
return json.loads(chat_completion.choices[0].message.content)
except Exception as e:
print(f"Error in extract_themes: {e}")
return []
def process_reviews(event_str):
try:
review = clean_and_parse(event_str)
review_text = review.get('review_text', '')
review['themes'] = extract_themes(review_text)
return json.dumps(review)
except Exception:
pass
return None
We’ll skip the setup boilerplate for the Kafka source and sink. In short, we consume reviews from the product_reviews topic, apply the process_reviews function to extract themes, and write the enriched output to a new topic, product_reviews_with_themes.
themes_stream = ds.map(process_reviews, output_type=Types.STRING()) \
.filter(lambda x: x is not None)
themes_stream.sink_to(sink)
Step 2: Analyze Themes in Real Time
Now that themes are being extracted and written to the product_reviews_with_themes topic as reviews come in, we can analyze them in real time by aggregating their counts. This lets us track which topics are trending as customers leave feedback.
themes_source = KafkaSource.builder()...
ds_themes = env.from_source(themes_source, WatermarkStrategy.for_monotonous_timestamps(), "Kafka Themes Source")
# Process reviews and count themes
theme_counts = ds_themes.map(clean_and_parse, output_type=Types.MAP(Types.STRING(), Types.OBJECT_ARRAY(Types.BYTE()))) \
.filter(lambda x: x is not None and "themes" in x) \
.flat_map(lambda review: [(theme.lower(), 1) for theme in review["themes"]], output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \
.key_by(lambda x: x[0]) \
.sum(1)
# Print results
theme_counts.print()
Why This Matters
Historically, thematic analysis required manual tagging, rules-based NLP pipelines, or post-hoc topic modeling like Latent Dirichlet allocation (LDA). These approaches don’t scale well, struggle with nuance, and lack immediacy.
Now, with tools like GPT-4 and PyFlink, you can analyze subjective, unstructured data in real time, no need to wait for batch jobs or build custom NLP models from scratch.
This opens the door for smarter customer feedback loops, real-time product monitoring, and richer analytics, all powered by streaming data and foundation models.
Wrapping Up
Data streaming shifts how we work with data. For data scientists, it’s a chance to move closer to where value is created: the moment data is generated, and the moment decisions are made.
By building and using models and analytics that work in real time, you’re no longer waiting on yesterday’s data to explain what happened. You’re helping shape what happens next. That’s a powerful position, one that connects your work more directly to customers, operations, and revenue.
With tools like Kafka, Flink, and PyFlink, and the emergence of foundation models like GPT-4, the barriers to working with streaming data are lower than ever. Bringing your models closer to live data means bringing your impact closer to the business.