
Deep neural networks (DNNs) have achieved remarkable success across various fields, including computer vision, natural language processing, and speech recognition. This success is largely attributed to first-order optimizers like stochastic gradient descent with momentum (SGDM) and AdamW. However, these methods face challenges in efficiently training large-scale models. Second-order optimizers, such as K-FAC, Shampoo, AdaBK, and Sophia, demonstrate superior convergence properties but often incur significant computational and memory costs, hindering their widespread adoption for training large models within limited memory budgets.
Two main approaches have been explored to reduce the memory consumption of optimizer states: factorization and quantization. Factorization uses low-rank approximation to represent optimizer states, a strategy applied to both first-order optimizers and second-order optimizers. In a distinct line of work, quantization techniques utilize low-bit representations to compress the 32-bit optimizer states. While quantization has been successfully applied to first-order optimizers, adapting it to second-order optimizers poses a greater challenge due to the matrix operations involved in these methods.
Researchers from Beijing Normal University and Singapore Management University present the first 4-bit second-order optimizer, taking Shampoo as an example, while maintaining performance comparable to its 32-bit counterpart. The key contribution is quantizing the eigenvector matrix of the preconditioner in 4-bit Shampoo instead of directly quantizing the preconditioner itself. This approach preserves the small singular values of the preconditioner, which are crucial for accurately computing the inverse fourth root, thereby avoiding performance degradation. Also, computing the inverse fourth root from the quantized eigenvector matrix is straightforward, ensuring no increase in wall-clock time. Two techniques are proposed to enhance performance: Björck orthonormalization to rectify the orthogonality of the quantized eigenvector matrix, and linear square quantization outperforming dynamic tree quantization for second-order optimizer states.
The key idea is to quantize the eigenvector matrix U of the preconditioner A=UΛUT using a quantizer Q, instead of quantizing A directly. This preserves the singular value matrix Λ, which is crucial for accurately computing the matrix power A^(-1/4) via matrix decompositions like SVD. Björck orthonormalization is applied to rectify the loss of orthogonality in the quantized eigenvectors. Linear square quantization is used instead of dynamic tree quantization for better 4-bit quantization performance. The preconditioner update utilizes the quantized eigenvectors V and unquantized singular values Λ to approximate A≈VΛVT. The inverse 4th root A^(-1/4) is approximated by quantizing it to get its quantized eigenvectors and reconstructing using the quantized eigenvectors and diagonal entries. Further orthogonalization enables accurate computation of matrix powers As for arbitrary s.
By doing thorough experimentation, researchers demonstrate the superiority of the proposed 4-bit Shampoo over first-order optimizers like AdamW. While first-order methods require running 1.2x to 1.5x more epochs, resulting in longer wall-clock times, they still achieve lower test accuracies compared to second-order optimizers. In contrast, 4-bit Shampoo achieves comparable test accuracies to its 32-bit counterpart, with differences ranging from -0.7% to 0.5%. The increases in wall-clock time for 4-bit Shampoo range from -0.2% to 9.5% compared to 32-bit Shampoo, while providing memory savings of 4.5% to 41%. Remarkably, the memory costs of 4-bit Shampoo are only 0.8% to 12.7% higher than first-order optimizers, marking a significant advancement in enabling the use of second-order methods.
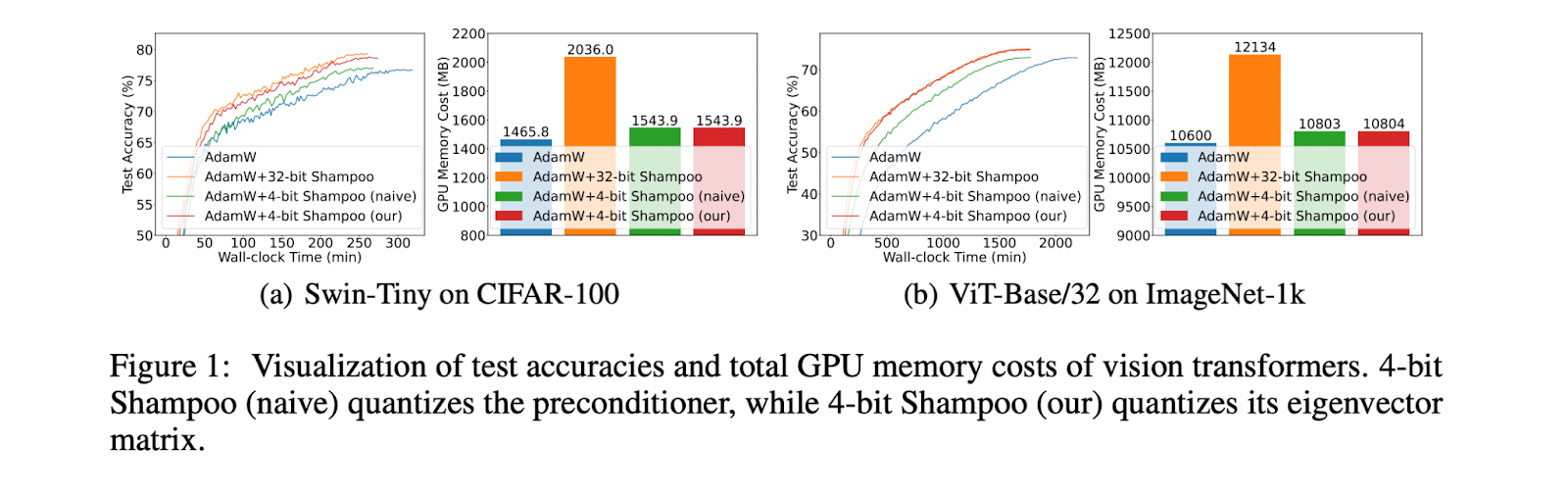
This research presents the 4-bit Shampoo, designed for memory-efficient training of DNNs. A key finding is that quantizing the eigenvector matrix of the preconditioner, instead of the preconditioner itself, is crucial to minimizing quantization errors in its inverse 4th root computation at 4-bit precision. This is due to the sensitivity of small singular values, which are preserved by quantizing only the eigenvectors. To further enhance performance, orthogonal rectification and linear square quantization mapping techniques are introduced. Across various image classification tasks involving different DNN architectures, 4-bit Shampoo achieves performance on par with its 32-bit counterpart, while offering significant memory savings. This work paves the way for enabling the widespread use of memory-efficient second-order optimizers in training large-scale DNNs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.