
Natural Language Processing (NLP) is a critical area of artificial intelligence that focuses on the interaction between computers and human language. It involves developing algorithms and models that enable computers to comprehend, interpret, and generate human language. This technology finds applications in various domains, such as machine translation, sentiment analysis, and information retrieval.
What presents a challenge is the evaluation of long-context language models. These models are crucial for tasks that require understanding and generating text based on extensive context. However, they often need help maintaining consistency and accuracy over long passages, leading to potential errors and inefficiencies in applications requiring deep contextual understanding.
Existing research includes frameworks like “needle-in-a-haystack” (NIAH) for long-context language model evaluation. Models such as GPT-4 and RULER are evaluated using these methods. These frameworks typically involve synthetic tasks generated programmatically or by language models, which can lack real-world complexity. Benchmarks like NIAH and its variants must fully capture the nuances of narrative text, often failing in global reasoning tasks. This synthetic nature of current methods limits their effectiveness in assessing true language comprehension.
Researchers from UMass Amherst, Allen Institute for AI, and Princeton University have introduced a new evaluation methodology called NOCHA (Narrative Open-Contextualized Human Annotation). This approach is designed to assess the performance of long-context language models more accurately. NOCHA involves collecting minimal narrative pairs, where one claim is true, and the other is false, both written by readers of books.
The NOCHA methodology involves collecting narrative minimal pairs from recently published fictional books. Annotators familiar with these books generate pairs of true and false claims based on the content. This dataset includes 1,001 pairs derived from 67 books used to evaluate models like GPT-4 and RULER. Each model is prompted with these claims and the entire book content to verify the claims. The process ensures models are tested on realistic, contextually rich scenarios. Data collection and quality control involve multiple annotators and extensive reviews to maintain high accuracy in claim verification.
The research demonstrated that current long-context language models, including GPT-4 and its variants, achieve varying degrees of accuracy. For example, GPT-4 attained an accuracy of 76.7% on balanced data but only 55.8% when proper context utilization was required. This result indicates a substantial gap between human and model performance, highlighting the need for further advancements.
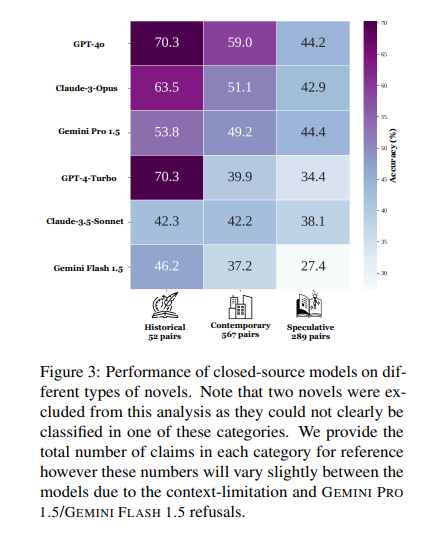
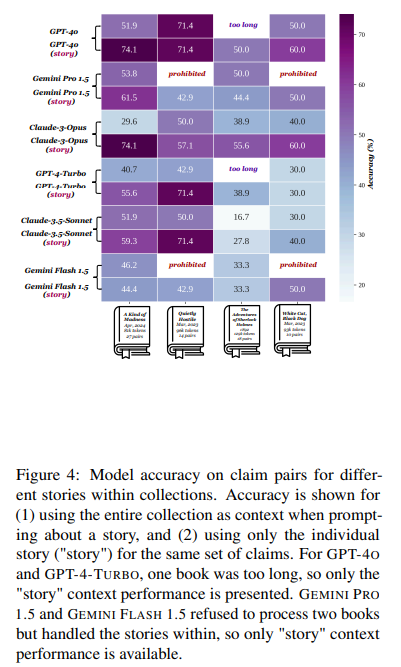
The performance of these models was evaluated on various metrics, including their ability to verify claims about book content accurately. Human readers achieved a claim verification accuracy of 96.9%, significantly higher than the best-performing model. This result underscores the models’ struggles with tasks that require global reasoning over extended contexts instead of simple sentence-level retrieval.
In conclusion, the research identifies significant challenges in evaluating long-context language models and introduces a novel methodology to address these issues. The NOCHA approach offers a more realistic and rigorous framework for testing these models, providing valuable insights into their strengths and limitations. This work emphasizes the importance of developing more sophisticated evaluation techniques to advance the field of NLP.
Check out the Paper, GitHub, and Leaderboard. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
🚀 Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.