
Large Language Models (LLMs) have gained significant attention in recent years, with researchers focusing on improving their performance across various tasks. A critical challenge in developing these models lies in understanding the impact of pre-training data on their overall capabilities. While the importance of diverse data sources and computational resources has been established, a crucial question remains: what properties of data contribute most effectively to general performance? Surprisingly, code data has become a common component in pre-training mixtures, even for models not explicitly designed for code generation. This inclusion raises questions about the precise impact of code data on non-code tasks. This topic has yet to be systematically investigated despite its potential significance in advancing LLM capabilities.
Researchers have made numerous attempts to understand and improve LLM performance through data manipulation. These efforts include studying the effects of data age, quality, toxicity, and domain, as well as exploring techniques like filtering, de-duplication, and data pruning. Some studies have investigated the role of synthetic data in enhancing performance and bridging gaps between open-source and proprietary models. While these approaches offer valuable insights into general data characteristics, they do not specifically address the impact of code data on non-code tasks.
The inclusion of code in pre-training mixtures has become a common practice, even for models not primarily designed for code-related tasks. Previous studies suggest that code data improves LLM performance on various natural language processing tasks, including entity linking, commonsense reasoning, and mathematical reasoning. Some researchers have demonstrated the benefits of using Python code data in low-resource pre-training settings. However, these studies often focused on specific aspects or limited evaluation setups, lacking a comprehensive examination of code data’s impact across various tasks and model scales.
Researchers from Cohere For AI and Cohere conducted an extensive set of large-scale controlled pre-training experiments to investigate the impact of code data on LLM performance. Their study focused on various aspects, including the timing of code introduction in the training process, code proportions, scaling effects, and the quality and properties of the code data used. Despite the significant computational cost of these ablations, the results consistently demonstrated that code data provides critical improvements to non-code performance.
The study’s key findings reveal that compared to text-only pre-training, the best variant with code data inclusion resulted in relative increases of 8.2% in natural language reasoning, 4.2% in world knowledge, 6.6% in generative win rates, and a 12-fold boost in code performance. Also, performing cooldown with code led to additional improvements: 3.7% in natural language reasoning, 6.8% in world knowledge, and 20% in code performance, relative to cooldown without code.
Several factors proved crucial, including optimizing the proportion of code, enhancing code quality through synthetic code and code-adjacent data, and utilizing code across multiple training stages, including cool down. The researchers conducted extensive evaluations on a wide range of benchmarks, covering world knowledge tasks, natural language reasoning, code generation, and LLM-as-a-judge win rates. These experiments spanned models ranging from 470 million to 2.8 billion parameters.
The research methodology involved a comprehensive experimental framework to evaluate the impact of code on LLM performance. The study used SlimPajama, a high-quality text dataset, as the primary source for natural language data, carefully filtering out code-related content. For code data, researchers employed multiple sources to explore different properties:
1. Web-based Code Data: Derived from the Stack dataset, focusing on the top 25 programming languages.
2. Markdown Data: Including markup-style languages like Markdown, CSS, and HTML.
3. Synthetic Code Data: A proprietary dataset of formally verified Python programming problems.
4. Code-Adjacent Data: Incorporating GitHub commits, Jupyter notebooks, and StackExchange threads.
The training process consisted of two phases: continued pre-training and cooldown. Continued pre-training involved training a model initialized from a pre-trained model for a fixed token budget. Cooldown, a technique to boost model quality, involved up-weighting high-quality datasets and annealing the learning rate during the final training stages.
The evaluation suite was designed to assess performance across various domains: world knowledge, natural language reasoning, and code generation. Also, the researchers employed LLM-as-a-judge win rates to evaluate generative performance. This comprehensive approach allowed for a systematic understanding of code’s impact on general LLM performance beyond just code-related tasks.

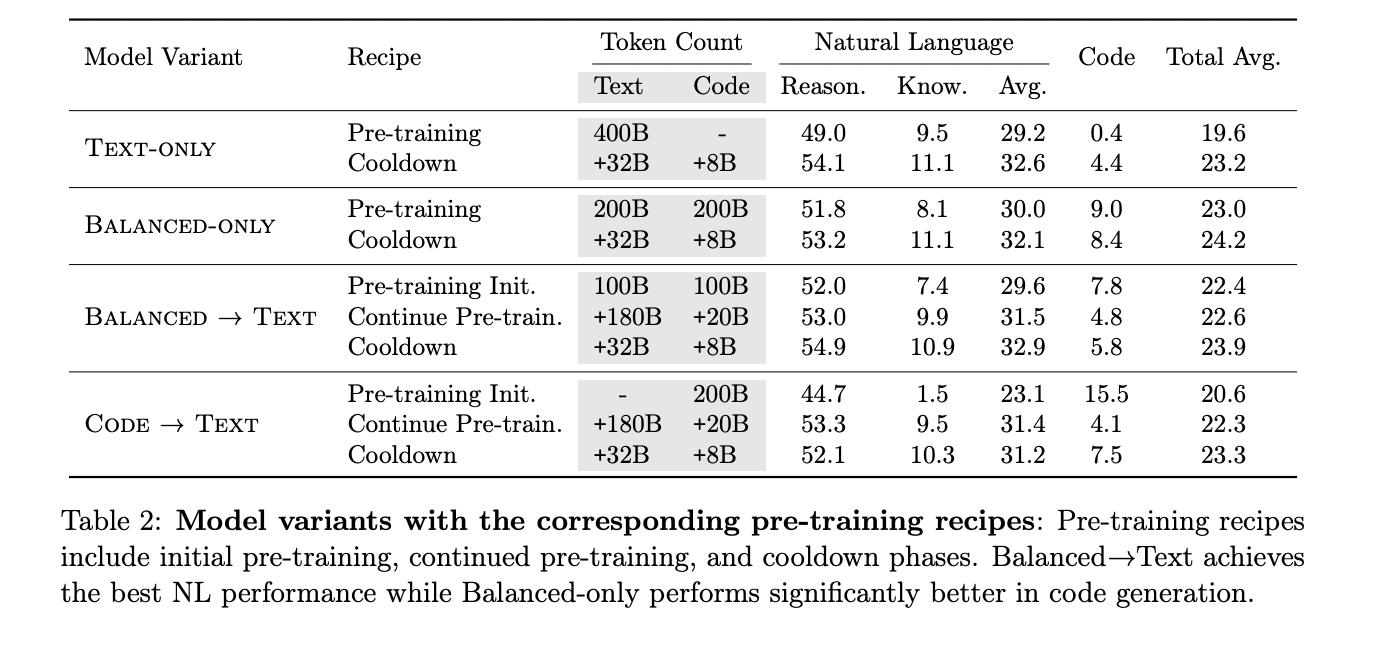
The study revealed significant impacts of code data on LLM performance across various tasks. For natural language reasoning, models initialized with code data showed the best performance. The code-initialized text model (code→text) and the balanced-initialized text model (balanced→text) outperformed the text-only baseline by 8.8% and 8.2% respectively. The balanced-only model also showed a 3.2% improvement over the baseline, indicating that initialization from a pre-trained model with a mix of code has a strong positive effect on natural language reasoning tasks.
In world knowledge tasks, the balanced→text model performed best, surpassing the code→text model by 21% and the text-only model by 4.1%. This suggests that world knowledge tasks benefit from a more balanced data mixture for initialization and a larger proportion of text in the continual pre-training stage.
For code generation tasks, the balanced-only model achieved the best performance, showing a 46.7% and 54.5% improvement over balanced→text and code→text models respectively. However, this came at the cost of lower performance in natural language tasks.
Generative quality, as measured by win rates, also improved with the inclusion of code data. Both code→text and balanced-only models outperformed the text-only variant by a 6.6% difference in win-loss rates, even on non-code evaluations.
These results demonstrate that including code data in pre-training not only enhances reasoning capabilities but also improves the overall quality of generated content across various tasks, highlighting the broad benefits of code data in LLM training.
This study provides new insights into the impact of code data on LLM performance across a wide range of tasks. The researchers conducted a comprehensive analysis, focusing not only on code-related tasks but also on natural language performance and generative quality. Their systematic approach included various ablations examining initialization strategies, code proportions, code quality and properties, and the role of code in pre-training cooldown.
Key findings from the study include:
- Code data significantly improves non-code task performance. The best variant with code data showed relative increases of 8.2% in natural language reasoning, 4.2% in world knowledge, and 6.6% in generative win rates compared to text-only pre-training.
- Code performance saw a dramatic 12-fold boost with the inclusion of code data.
- Cooldown with code further enhanced performance, improving natural language reasoning by 3.6%, world knowledge by 10.1%, and code performance by 20% relative to pre-cooldown models. This also led to a 52.3% increase in generative win rates.
- The addition of high-quality synthetic code data, even in small amounts, had a disproportionately positive impact, increasing natural language reasoning by 9% and code performance by 44.9%.
These results demonstrate that incorporating code data in LLM pre-training leads to substantial improvements across various tasks, extending far beyond code-specific applications. The study highlights the critical role of code data in enhancing LLM capabilities, offering valuable insights for future model development and training strategies.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
