
Language Foundation Models (LFMs) and Large Language Models (LLMs) have demonstrated their ability to handle multiple tasks efficiently with a single fixed model. This achievement has motivated the development of Image Foundation Models (IFMs) in computer vision, which aim to encode general information from images into embedding vectors. However, using these techniques poses a challenge in video analysis. One approach involves treating videos as a sequence of images, where each frame is sampled and embedded before combining; however, this approach faces challenges in capturing detailed motion and small changes between frames. It becomes difficult to understand the continuous flow of information in videos, especially when it comes to tracking object movement and minor frame-to-frame differences
The existing works tried to overcome these challenges using two main approaches based on the Vision Transformer architecture (ViT). The first approach uses distillation with high-performance IFMs like CLIP as teachers, and the second approach is based on masked modeling, where the model predicts missing information from partial input. However, both approaches have their limitations. Distillation-based methods, like UMT and InternVideo2, struggle with motion-sensitive benchmarks like Something-Something-v2 and Diving-48. The masked modeling-based methods, like V-JEPA, perform badly on appearance-centric benchmarks like Kinetics-400 and Moments-in-Time. These limitations highlight the difficulty in capturing the appearance of objects and their motion in videos.
A team from Twelve Labs has proposed TWLV-I, a new model designed to provide embedding vectors for videos that capture appearance and motion. Even though trained only on publicly available datasets, TWLV-I shows strong performance on appearance and motion-focused action recognition benchmarks. Moreover, the model achieves state-of-the-art performance in video-centric tasks such as temporal and spatiotemporal action localization, as well as temporal action segmentation. The current evaluation methods are enhanced to analyze the TWLV-I and other Video Foundation Models (VFMs), with a new analytical approach and a technique to find the model’s ability to differentiate videos based on motion direction, independent of appearance.
TWLV-I adopts ViT architecture, available in Base with 86M parameters and Large with 307M parameters versions. The model tokenizes input videos into patches, processes them through the transformer, and pools the resulting patch-wise embeddings to obtain the overall video embedding. Moreover, the pretraining dataset contains Kinetics-710, HowTo360K, WebVid10M, and various image datasets. The training objective of TWLV-I integrates strengths from distillation-based and masked modeling-based approaches using different reconstruction target strategies. The model utilizes two frame sampling methods, (a) Uniform Embedding for shorter videos and (b) Multi-Clip Embedding for longer videos, to overcome computational constraints.
The results obtained on TWLV-I show significant performance enhancement over existing models in action recognition tasks. Based on the average top-1 accuracy of linear probing across five action recognition benchmarks and using only publicly available datasets for pretraining, TWLV-I outperforms VJEPA (ViT-L) by 4.6% points and UMT (ViT-L) by 7.7% points. This model outperforms larger models like DFN (ViT-H) by 7.2% points, V-JEPA (ViT-H) by 2.7% points, and InternVideo2 (ViT-g) by 2.8% points. Researchers also provided embedding vectors generated by TWLV-I from widely used video benchmarks and evaluation source code that can directly utilize these embeddings.
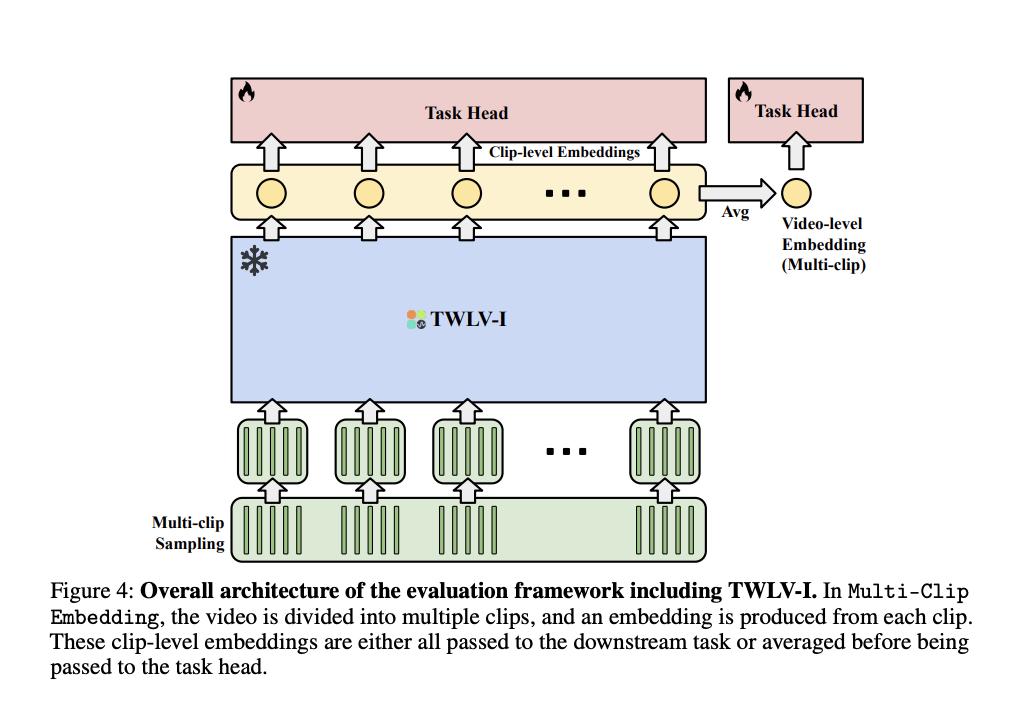
A team from Twelve Labs has proposed TWLV-I, a novel model designed to provide embedding vectors for videos that capture appearance and motion. TWLV-I proves a strong video foundation model that shows great performance in understanding motion and appearance. The TWLV-I model and its embeddings are expected to be used widely in various applications. Moreover, the evaluation and analysis methods will be actively adopted in the video foundation model domain. In the future, these methods are expected to guide research in the video understanding field, making further progress in developing more comprehensive video analysis models.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.