
Language models have gained prominence in reinforcement learning from human feedback (RLHF), but current reward modeling approaches face challenges in accurately capturing human preferences. Traditional reward models, trained as simple classifiers, struggle to perform explicit reasoning about response quality, limiting their effectiveness in guiding LLM behavior. The primary issue lies in their inability to generate reasoning traces, forcing all evaluations to occur implicitly within a single forward pass. This constraint hinders the model’s capacity to assess the nuances of human preferences thoroughly. While alternative approaches like the LLM-as-a-Judge framework have attempted to address this limitation, they generally underperform classic reward models in pairwise preference classification tasks, highlighting the need for a more effective method.
Researchers have attempted various approaches to address the challenges in reward modeling for language models. Ranking models like Bradley-Terry and Plackett-Luce have been employed, but they struggle with intransitive preferences. Some studies directly model the probability of one response being preferred over another, while others focus on modeling rewards across multiple objectives. Recent work has proposed maintaining and training the language model head as a form of regularization.
Critique-based feedback methods have also been explored, with some utilizing self-generated critiques to improve generation quality or serve as preference signals. However, these approaches differ from efforts to train better reward models when human preference data is available. Some researchers have investigated using oracle critiques or human-labeled critique preferences to teach language models to critique effectively.
The LLM-as-a-Judge framework, which uses a grading rubric to evaluate responses, shares similarities with critique-based methods but focuses on evaluation rather than revision. While this approach produces chain-of-thought reasoning, it generally underperforms classic reward models in pairwise preference classification tasks.
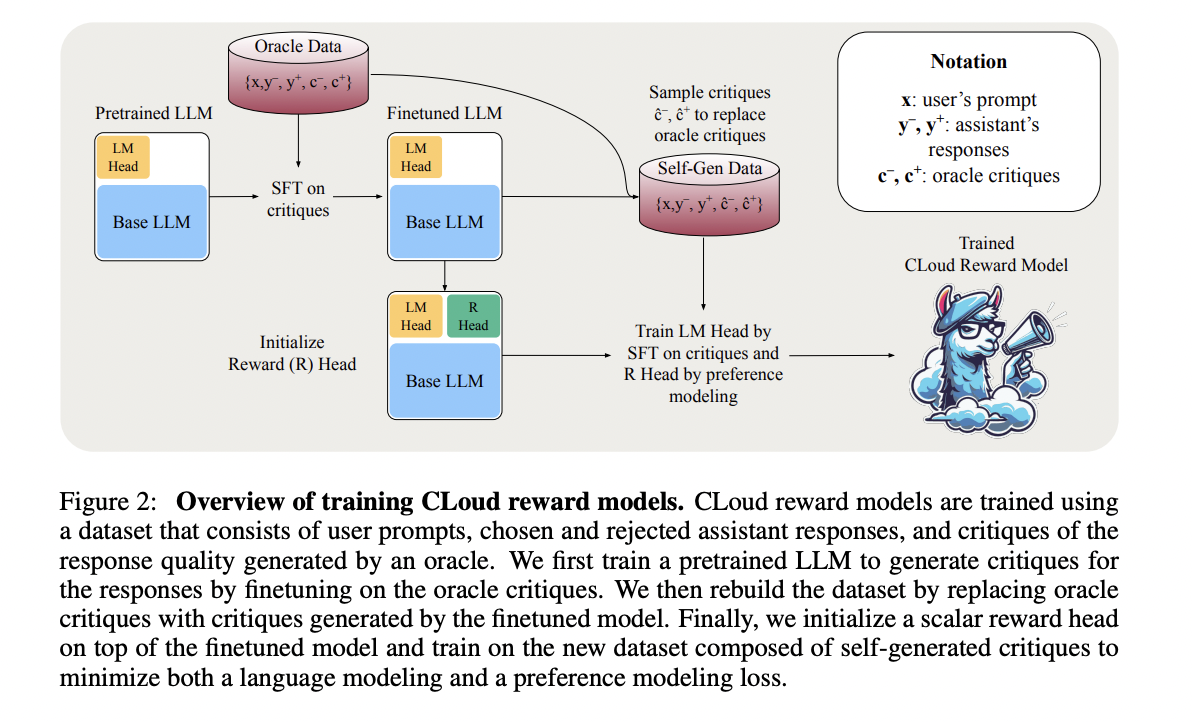
Researchers from Databricks, MIT, and the University of California, San Diego present Critique-out-Loud (CLoud) reward models, which represent a unique approach to improving language model performance in reinforcement learning from human feedback. These models generate a detailed critique of how well an assistant’s response answers a user’s query before producing a scalar reward for the response quality. This process combines the strengths of classic reward models and the LLM-as-a-Judge framework.
CLoud reward models are trained using a preference dataset containing prompts, responses, and oracle critiques. The training process involves supervised fine-tuning on oracle critiques for critique generation and the Bradley-Terry preference model for scalar reward production. To enhance performance, the researchers explore multi-sample inference techniques, particularly self-consistency, which involves sampling multiple critique-reward predictions and marginalizing across critiques for a more accurate reward estimate.
This innovative approach aims to unify reward models and LLM-as-a-Judge methods, potentially leading to significant improvements in pairwise preference classification accuracy and win rates in various benchmarks. The researchers also investigate key design choices, such as on-policy versus off-policy training, and the benefits of self-consistency over critiques to optimize reward modeling performance.
CLoud reward models extend classic reward models by incorporating a language modeling head alongside the base model and reward head. The training process involves supervised fine-tuning on oracle critiques, replacing these with self-generated critiques, and then training the reward head on the self-generated critiques. This approach minimizes the distribution shift between training and inference. The model uses modified loss functions, including a Bradley-Terry model loss and a critique-supervised fine-tuning loss. To enhance performance, CLoud models can employ self-consistency during inference, sampling multiple critiques for a prompt-response pair and averaging their predicted rewards for a final estimate.
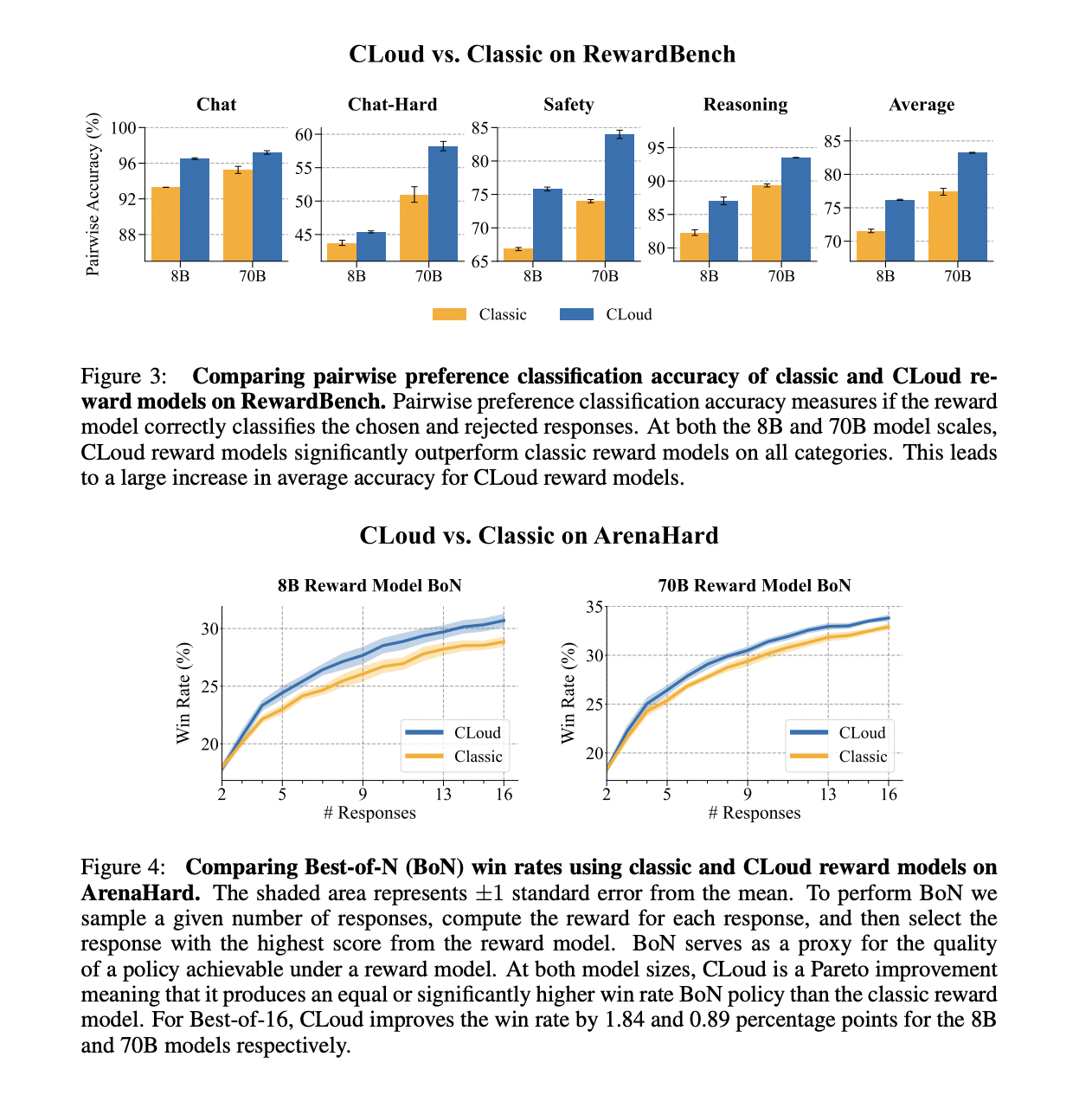
The researchers evaluated CLoud reward models against classic reward models using two key metrics: pairwise preference classification accuracy and Best-of-N (BoN) win rate. For pairwise preference classification, they used the RewardBench evaluation suite, which includes categories like Chat, Chat-Hard, Safety, and Reasoning. The BoN win rate was assessed using ArenaHard, an open-ended generation benchmark.
CLoud reward models significantly outperformed classic reward models in pairwise preference classification across all categories on RewardBench, for both 8B and 70B model scales. This led to a substantial increase in average accuracy for CLoud models.
In the BoN evaluation on ArenaHard, CLoud models demonstrated a Pareto improvement over classic models, producing equal or significantly higher win rates. For Best-of-16, CLoud improved the win rate by 1.84 and 0.89 percentage points for 8B and 70B models, respectively. These results suggest that CLoud reward models offer superior performance in guiding language model behavior compared to classic reward models.
This study introduces CLoud reward models, which represent a significant advancement in preference modeling for language models. By preserving language modeling capabilities alongside a scalar reward head, these models explicitly reason about response quality through critique generation. This approach demonstrates substantial improvements over classic reward models in pairwise preference modeling accuracy and Best-of-N decoding performance. Self-consistency decoding proved beneficial for reasoning tasks, particularly those with short reasoning horizons. By unifying language generation with preference modeling, CLoud reward models establish a new paradigm that opens avenues for improving reward models through variable inference computing, laying the groundwork for more sophisticated and effective preference modeling in language model development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.