
Retrieval-augmented generation (RAG) has emerged as a prominent application in the field of natural language processing. This innovative approach involves breaking down large documents into smaller, manageable text chunks, typically limited to around 512 tokens. These bite-sized pieces of information are then stored in a vector database, with each chunk represented by a unique vector generated using a text embedding model. This process forms the foundation for efficient information retrieval and processing.
The power of RAG becomes evident during runtime operations. When a user submits a query, the same embedding model that processed the stored chunks comes into play. It encodes the query into a vector representation, bridging the user’s input and the stored information. This vector is then used to identify and retrieve the most relevant text chunks from the database, ensuring that only the most pertinent information is accessed for further processing.
In October 2023, a significant milestone in natural language processing was reached with the release of jina-embeddings-v2-base-en, the world’s first open-source embedding model boasting an impressive 8K context length. This groundbreaking development sparked considerable discussion within the AI community about the practical applications and limitations of long-context embedding models. The innovation pushed the boundaries of what was possible in text representation, but it also raised important questions about its effectiveness in real-world scenarios.
Despite the initial excitement, many experts began to question the practicality of encoding extremely long documents into a single embedding representation. It became apparent that for numerous applications, this approach might not be ideal. The AI community recognized that many use cases require the retrieval of smaller, more focused portions of text rather than processing entire documents at once. This realization led to a deeper exploration of the trade-offs between context length and retrieval efficiency.
Also, research indicated that dense vector-based retrieval systems often perform more effectively when working with smaller text segments. The reasoning behind this is rooted in the concept of semantic compression. When dealing with shorter text chunks, the embedding vectors are less likely to suffer from “over-compression” of semantics. This means that the nuanced meanings and contexts within the text are better preserved, leading to more accurate and relevant retrieval results in various applications.
The debate surrounding long-context embedding models has led to a growing consensus that embedding smaller chunks of text is often more advantageous. This preference stems from two key factors: the limited input sizes of downstream Large Language Models (LLMs) and the concern that crucial contextual information may be diluted when compressing lengthy passages into a single vector representation. These limitations have caused many to question the practical value of training models with extensive context lengths, such as 8192 tokens.
However, dismissing long-context models entirely would be premature. While the industry may predominantly require embedding models with a 512-token context length, there are still compelling reasons to explore and develop models with greater capacity. This article aims to address this important, albeit uncomfortable, question by examining the limitations of the conventional chunking-embedding pipeline used in RAG systems. In doing so, the researchers introduce a unique approach called “Late Chunking.“
“The implementation of late chunking can be found in the Google Colab link”
The Late Chunking method represents a significant advancement in utilizing the rich contextual information provided by 8192-length embedding models. This innovative technique offers a more effective way to embed chunks, potentially bridging the gap between the capabilities of long-context models and the practical needs of various applications. By exploring this approach, researchers seek to demonstrate the untapped potential of extended context lengths in embedding models.
The conventional RAG pipeline, which involves chunking, embedding, retrieving, and generating, faces significant challenges. One of the most pressing issues is the destruction of long-distance contextual dependencies. This problem arises when relevant information is distributed across multiple chunks, causing text segments to lose their context and become ineffective when taken in isolation.
A prime example of this issue can be observed in the chunking of a Wikipedia article about Berlin. When split into sentence-length chunks, crucial references like “its” and “the city” become disconnected from their antecedent, “Berlin,” which appears only in the first sentence. This separation makes it difficult for the embedding model to create accurate vector representations that maintain these important connections.
The consequences of this contextual fragmentation become apparent when considering a query like “What is the population of Berlin?” In a RAG system using sentence-length chunks, answering this question becomes problematic. The city name and its population data may never appear together in a single chunk, and without broader document context, an LLM struggles to resolve anaphoric references such as “it” or “the city.”
While various heuristics have been developed to address this issue, including resampling with sliding windows, using multiple context window lengths, and performing multi-pass document scans, these solutions remain imperfect. Like all heuristics, their effectiveness is inconsistent and lacks theoretical guarantees. This limitation highlights the need for more robust approaches to maintain contextual integrity in RAG systems.
The naive encoding approach, commonly used in many RAG systems, employs a straightforward but potentially problematic method for processing long texts. This approach, illustrated on the left side of the referenced image, begins by splitting the text into smaller units before any encoding. These units are typically defined by sentences, paragraphs, or predetermined maximum length limits.
Once the text is divided into these chunks, an embedding model is applied repeatedly to each segment. This process generates token-level embeddings for every word or subword within each chunk. To create a single, representative embedding for the entire chunk, many embedding models utilize a technique called mean pooling. This method involves calculating the average of all token-level embeddings within the chunk, resulting in a single embedding vector.
While this approach is computationally efficient and easy to implement, it has significant drawbacks. By splitting the text before encoding, risks losing important contextual information that spans across chunk boundaries. Also, the mean pooling technique, while simple, may not always capture the nuanced relationships between different parts of the text effectively, potentially leading to the loss of semantic information.
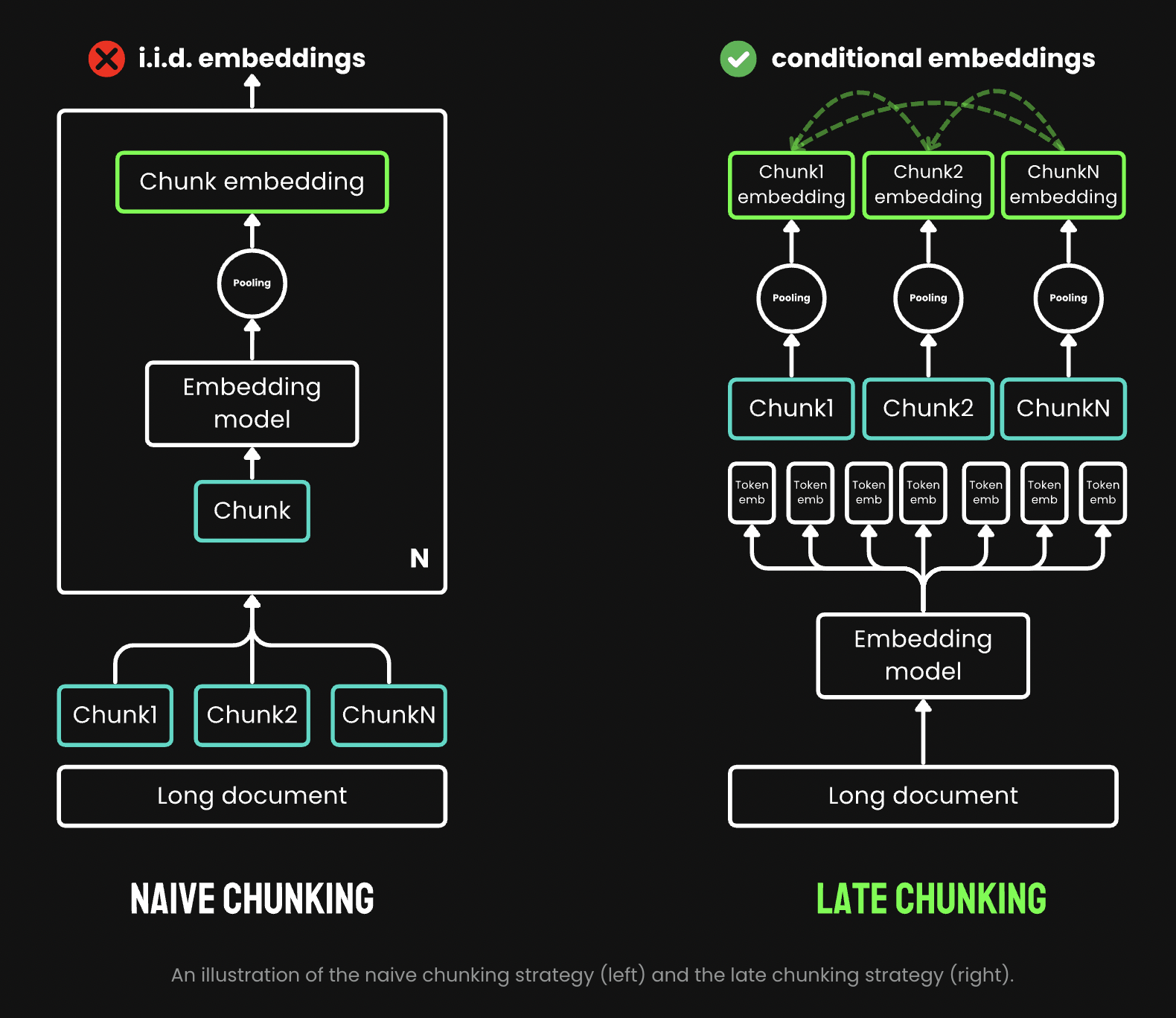
The “Late Chunking” approach represents a significant advancement in text processing for RAG systems. Unlike the naive method, it applies the transformer layer to the entire text first, generating token vectors that capture full contextual information. Mean pooling is then applied to chunks of these vectors, creating embeddings that consider the entire text’s context. This method produces chunk embeddings that are “conditioned on” previous ones, encoding more contextual information than the independent embeddings of the naive approach. Implementing late chunking requires long-context embedding models like jina-embeddings-v2-base-en, which can handle up to 8192 tokens. While boundary cues are still necessary, they are applied after obtaining token-level embeddings, preserving more contextual integrity.
To validate the effectiveness of late chunking, researchers conducted tests using retrieval benchmarks from BeIR. These tests involved query sets, text document corpora, and QRels files containing information about relevant documents for each query. The results consistently showed improved scores for late chunking compared to the naive approach. In some cases, late chunking even outperformed single-embedding encoding of entire documents. Also, a correlation emerged between document length and the performance improvement achieved through late chunking. As document length increased, the effectiveness of the late chunking strategy became more pronounced, demonstrating its particular value for processing longer texts in retrieval tasks.
This study introduced “late chunking,” an innovative approach that utilizes long-context embedding models to enhance text processing in RAG systems. By applying the transformer layer to entire texts before chunking, this method preserves crucial contextual information often lost in traditional i.i.d. chunk embedding. Late chunking’s effectiveness increases with document length, highlighting the importance of advanced models like jina-embeddings-v2-base-en that can handle extensive contexts. This research not only validates the significance of long-context embedding models but also opens avenues for further exploration in maintaining contextual integrity in text processing and retrieval tasks.
Check out the Details and Colab Notebook. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
