
Large Language Models (LLMs) have gained significant prominence in modern machine learning, largely due to the attention mechanism. This mechanism employs a sequence-to-sequence mapping to construct context-aware token representations. Traditionally, attention relies on the softmax function (SoftmaxAttn) to generate token representations as data-dependent convex combinations of values. However, despite its widespread adoption and effectiveness, SoftmaxAttn faces several challenges. One key issue is the tendency of the softmax function to concentrate attention on a limited number of features, potentially overlooking other informative aspects of the input data. Also, the application of SoftmaxAttn necessitates a row-wise reduction along the input sequence length, which can significantly slow down computations, particularly when using efficient attention kernels.
Recent research in machine learning has explored alternatives to the traditional softmax function in various domains. In supervised image classification and self-supervised learning, there’s a trend towards using richer pointwise Bernoulli conditionals parameterized by sigmoid functions, moving away from output conditional categorical distributions typically parameterized by softmax. Some studies have investigated replacing softmax with ReLU activation in both practical and theoretical contexts. Other explorations include the use of ReLU2 activation, purely linear attention, and cosine-similarity based attention mechanisms. A notable approach scaled various activation functions by n^(-α), where n is the sequence length and α is a hyper-parameter, to replace softmax. However, this method faced performance issues without proper initialization and the use of LayerScale. These diverse approaches aim to address the limitations of softmax-based attention, seeking more efficient and effective alternatives for context-aware token representation.
Apple researchers introduce a robust approach to attention mechanisms by replacing the row-wise softmax operation with an element-wise sigmoid nonlinearity. The researchers identify that the main challenge with naive sigmoid attention (SigmoidAttn) lies in the large initial attention norms. To address this, they propose several solutions and make significant contributions to the field. First, they demonstrate that SigmoidAttn is a universal function approximator for sequence-to-sequence tasks. Second, they provide an analysis of SigmoidAttn’s regularity and establish its worst-case Jacobian bound. Third, they enhance the FLASHATTENTION2 algorithm with a sigmoid kernel, resulting in substantial reductions in kernel inference wall-clock time and real-world inference time. Lastly, they show that SigmoidAttn performs comparably to SoftmaxAttn across various tasks and domains, highlighting its potential as a viable alternative in attention mechanisms.
SigmoidAttn, the proposed alternative to traditional softmax attention, is analyzed from two crucial perspectives. First, the researchers demonstrate that transformers using SigmoidAttn retain the Universal Approximation Property (UAP), ensuring their ability to approximate continuous sequence-to-sequence functions with arbitrary precision. This property is vital for maintaining the architecture’s generalizability and representation capability. The proof adapts the framework used for classical transformers, with key modifications to accommodate the sigmoid function. Notably, SigmoidAttn requires at least four attention heads and shifts in both query and key definitions to approximate the necessary selective shift operation, compared to softmax attention’s requirement of two heads and shifts only in the query definition.
Second, the study examines the regularity of SigmoidAttn by computing its Lipschitz constant. The analysis reveals that SigmoidAttn’s local Lipschitz constant is significantly lower than the worst-case scenario for softmax attention. This implies that SigmoidAttn exhibits better regularity, potentially leading to improved robustness and optimization ease in neural networks. The bound for SigmoidAttn depends on the average squared-norm of the input sequence rather than the largest value, allowing for application to unbounded distributions with bounded second moments.
The researchers conducted comprehensive evaluations of SigmoidAttn across various domains to validate its effectiveness. These evaluations encompassed supervised image classification using vision transformers, self-supervised image representation learning with methods like SimCLR, BYOL, and MAE, as well as automatic speech recognition (ASR) and auto-regressive language modeling (LM). Also, they tested sequence length generalization on TED-LIUM v3 for ASR and in small-scale synthetic experiments.
Results demonstrate that SigmoidAttn consistently matches the performance of SoftmaxAttn across all tested domains and algorithms. This performance parity is achieved while offering training and inference speed improvements, as detailed in earlier sections. Key observations from the empirical studies include:
1. For vision tasks, SigmoidAttn proves effective without requiring a bias term, except in the case of MAE. However, it relies on LayerScale to match SoftmaxAttn’s performance in a hyperparameter-free manner.
2. In language modeling and ASR tasks, performance is sensitive to the initial norm of the attention output. To address this, modulation is necessary through either relative positional embeddings like ALiBi, which shifts logit mass to the zero regime under SigmoidAttn, or appropriate initialization of the b parameter to achieve a similar effect.
These findings suggest that SigmoidAttn is a viable alternative to SoftmaxAttn, offering comparable performance across a wide range of applications while potentially providing computational advantages.
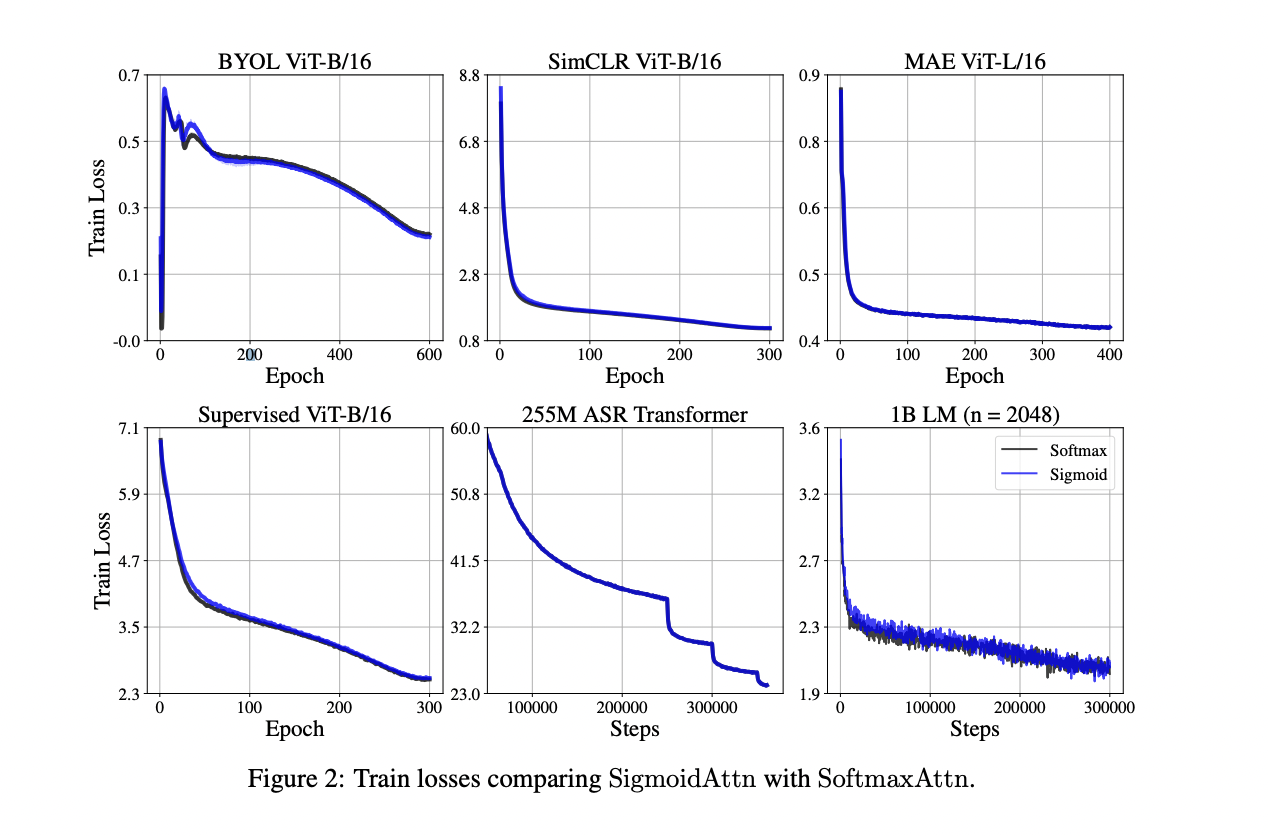
This study presents a comprehensive analysis of sigmoid attention as a potential replacement for softmax attention in transformer architectures. The researchers provide both theoretical foundations and empirical evidence to support the viability of this alternative approach. They demonstrate that transformers using sigmoid attention retain the crucial property of being universal function approximators while also exhibiting improved regularity compared to their softmax counterparts. The study identifies two key factors for the successful implementation of sigmoid attention: the use of LayerScale and the prevention of large initial attention norms. These insights contribute to establishing best practices for applying sigmoid attention in transformer models. Also, the researchers introduce FLASHSIGMOID, a memory-efficient variant of sigmoid attention that achieves a significant 17% speed-up in inference kernel performance. Extensive experiments conducted across various domains – including language processing, computer vision, and speech recognition – show that properly normalized sigmoid attention consistently matches the performance of softmax attention across diverse tasks and scales.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.