
Collaborative Multi-Agent Reinforcement Learning (MARL) has emerged as a powerful approach in various domains, including traffic signal control, swarm robotics, and sensor networks. However, MARL faces significant challenges due to the complex interactions between agents, which introduce non-stationarity in the environment. This non-stationarity complicates the learning process and makes it difficult for agents to adapt to changing conditions. In addition to that, as the number of agents increases, scalability becomes a critical issue, requiring efficient methods to handle large-scale multi-agent systems. Researchers are thus focused on developing techniques that can overcome these challenges while enabling effective collaboration among agents in dynamic and complex environments.
Prior attempts to overcome MARL challenges have predominantly focused on two main categories: policy-based and value-based methods. Policy gradient approaches like MADDPG, COMA, MAAC, MAPPO, FACMAC, and HAPPO have explored optimizing multi-agent policy gradients. Value-based methods like VDN and QMIX have concentrated on factorizing global value functions to improve scalability and performance.
In recent years, research on multi-agent communication methods has made significant strides. One category of approaches aims to limit message transmission within the network, using local gating mechanisms to dynamically trim communication links. Another category focuses on efficient learning to create meaningful messages or extract valuable information. These methods have employed various techniques, including attention mechanisms, graph neural networks, teammate modeling, and personalized message encoding and decoding schemes.
However, these approaches still face challenges balancing communication efficiency, scalability, and performance in complex multi-agent environments. Issues such as communication overhead, limited expressive power of discrete messages, and the need for more sophisticated message aggregation schemes remain areas of active research and improvement.
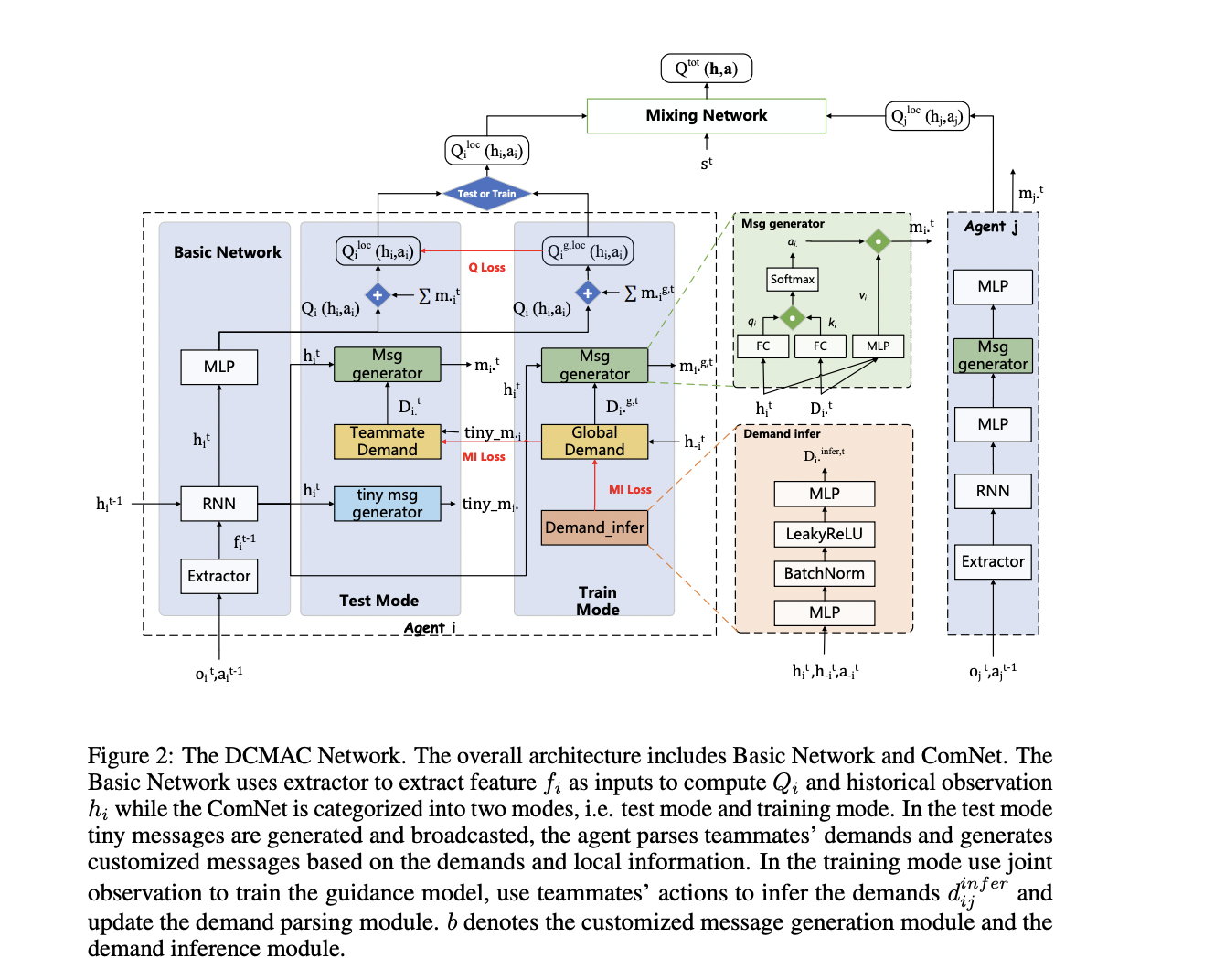
In this paper, researchers present DCMAC (Demand-aware Customized Multi-Agent Communication), a robust protocol designed to optimize the use of limited communication resources, reduce training uncertainty, and enhance agent collaboration in multi-agent reinforcement learning systems. This state-of-the-art method introduces a unique approach where agents initially broadcast concise messages using minimal communication resources. These messages are then parsed to understand teammate demands, allowing agents to generate customized messages that influence their teammates’ Q-values based on local information and perceived needs.
DCMAC incorporates an innovative training paradigm based on the upper bound of maximum return, alternating between Train Mode and Test Mode. In Train Mode, an ideal policy is trained using joint observations to serve as a guidance model, helping the target policy converge more efficiently. Test Mode employs a demand loss function and temporal difference error to update the demand parsing and customized message generation modules.
This approach aims to facilitate efficient communication within constrained resources, addressing key challenges in multi-agent systems. DCMAC’s effectiveness is demonstrated through experiments in various environments, showcasing its ability to achieve performance comparable to unrestricted communication algorithms while excelling in scenarios with communication limitations.
DCMAC’s architecture consists of three main modules: tiny message generation, teammate demand parsing, and customized message generation. The process begins with agents extracting features from observations using a self-attention mechanism to minimize redundant information. These features are then processed through a GRU module to obtain historical observations.
The tiny message generation module creates low-dimensional messages based on historical observations, which are periodically broadcast. The demand parsing module interprets these tiny messages to understand teammate demands. The customized message generation module then produces messages tailored to bias the Q-values of other agents, based on parsed demands and historical observations.
To optimize communication resources, DCMAC employs a link-pruning function that uses cross-attention to calculate correlations between agents. Messages are sent only to the most relevant agents based on communication constraints.
DCMAC introduces a maximum return upper bound training paradigm, which uses an ideal policy trained on joint observations as a guidance model. This approach includes a global demand module and a demand infer module to replicate the effects of global observation during training. The training process alternates between Train Mode and Test Mode, using mutual information and TD error to update various modules.
DCMAC’s performance was evaluated in three well-known multi-agent collaborative environments: Hallway, Level-Based Foraging (LBF), and StarCraft II Multi-Agent Challenge (SMAC). The results were compared with baseline algorithms such as MAIC, NDQ, QMIX, and QPLEX.

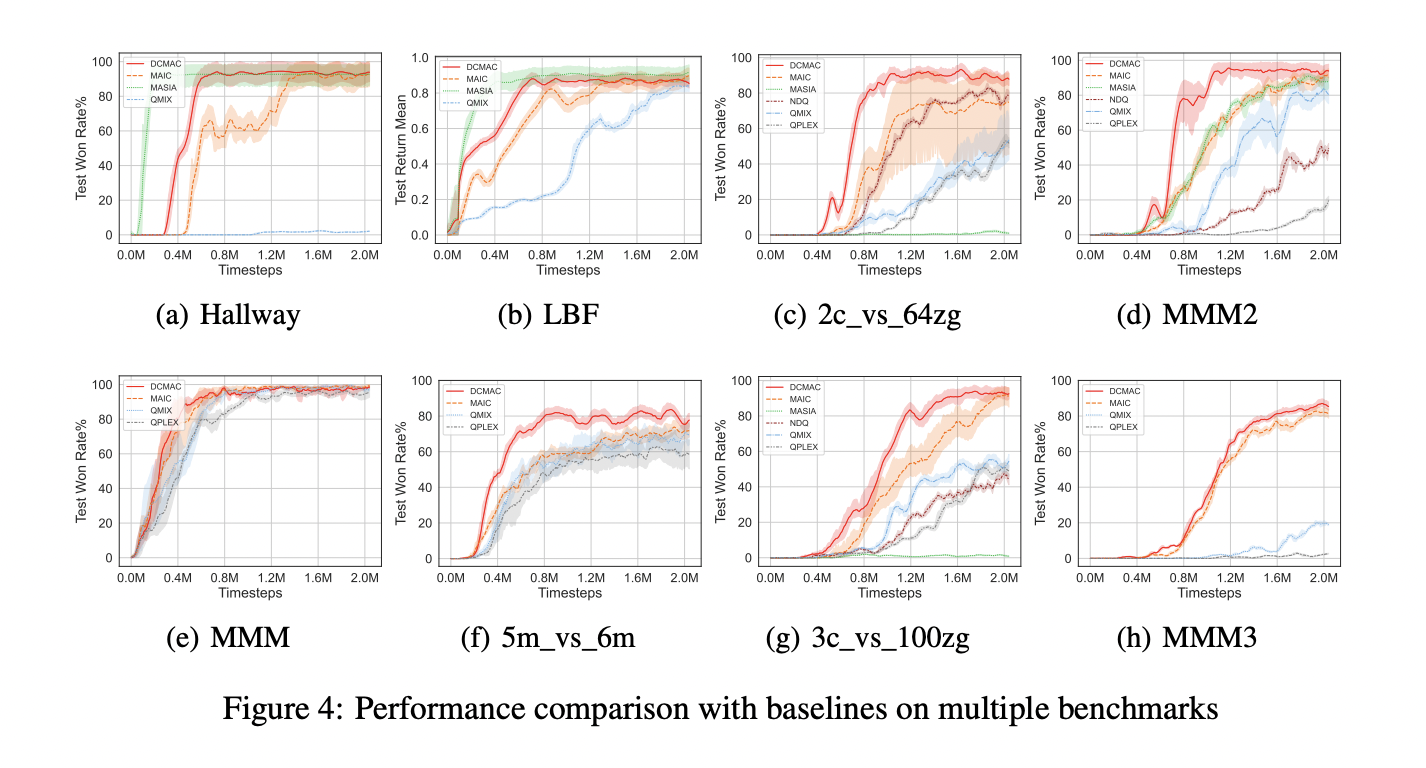
In communication performance tests, DCMAC showed superior results in scenarios with large observation spaces, such as SMAC. While it performed slightly behind MASIA in smaller observation space environments like Hallway and LBF, it still effectively improved agent collaboration. DCMAC outperformed other algorithms in hard and super hard SMAC maps, demonstrating its effectiveness in complex environments.
The guidance model of DCMAC, based on the maximum return upper bound training paradigm, showed excellent convergence and higher win rates in hard and super hard SMAC maps. This performance validated the effectiveness of training an ideal policy using joint observations and the assistance of the demand infer module.
In communication-constrained environments, DCMAC maintained high performance under 95% communication constraints and outperformed MAIC even under stricter limitations. At 85% communication constraint, DCMAC showed a significant decline but still achieved higher win rates in Train Mode.
This study presents DCMAC, which introduces a demand-aware customized multi-agent communication protocol to enhance collaborative multi-agent learning efficiency. It overcomes the limitations of previous approaches by enabling agents to broadcast tiny messages and parse teammate demands, improving communication effectiveness. DCMAC incorporates a guidance model trained on joint observations, inspired by knowledge distillation, to enhance the learning process. Extensive experiments across various benchmarks, including communication-constrained scenarios, demonstrate DCMAC’s superiority. The protocol shows particular strength in complex environments and under limited communication resources, outperforming existing methods and offering a robust solution for efficient collaboration in diverse and challenging multi-agent reinforcement learning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.