

Image by Editor | Midjourney
How LLMs are Changing the Recommendation Industry
Technology is rapidly evolving with the emergence of large language models (LLMs), notably transforming recommendation systems. Recommendation systems influence a variety of user experiences from the next song Spotify plays to the posts in your TikTok feed. By anticipating user preferences, recommendation systems enhance user satisfaction and increase engagement by keeping content relevant and engaging.
Recently, recommendation systems have been going through a step function advancement with the emergence of large language models (LLMs). These models are changing both user experiences and ranking. However, integrating LLMs directly into production environments poses challenges, primarily due to high latency issues. Because of this, rather than being used directly, LLMs are often employed to enhance other components of the system.
In this article, we’ll explore how LLMs are changing recommendation systems as we speak. Let’s first start with a brief overview.
A Brief Overview of Modern Recommendation Systems
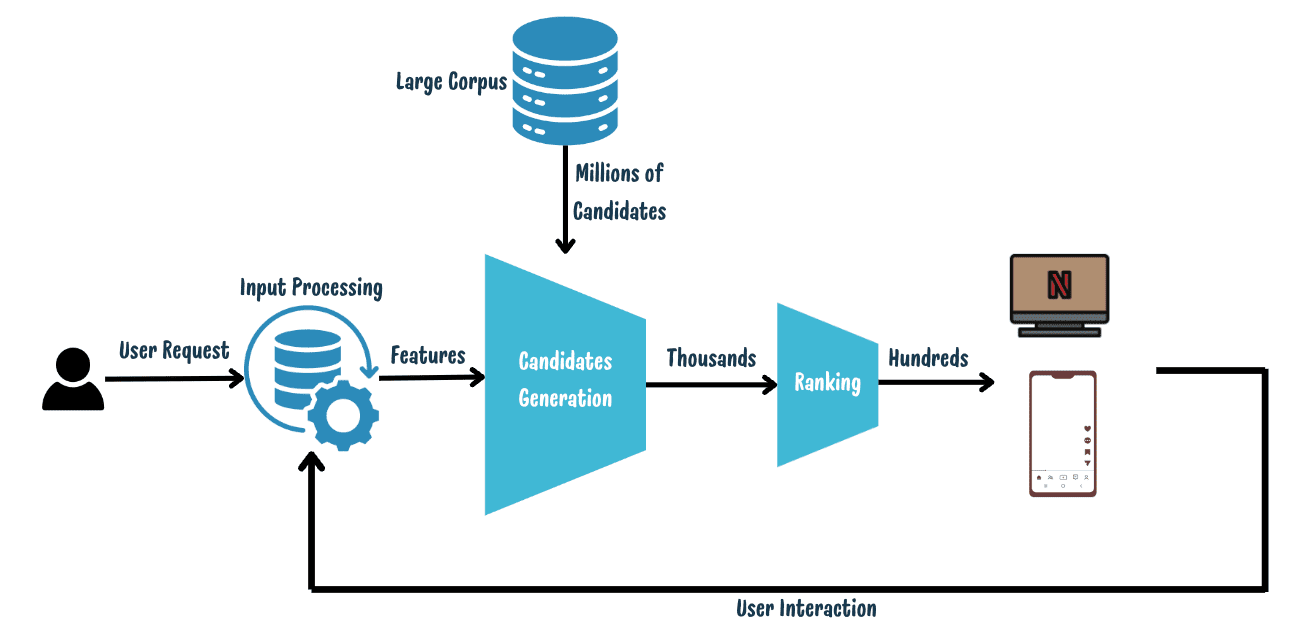
Image by Author | A typical modern recommendation system
Modern recommendation systems typically operate in a four-stage loop:
- Input Processing and Feature Generation: This stage processes data from user interactions — including explicit signals like reviews and ratings, and implicit signals such as clicks — turning them into relevant features for making recommendations.
- Candidate Generation: Upon receiving a user request, the system retrieves an initial list of potential recommendations, such as videos and music, from a vast corpus. While traditional systems might use keyword matching to find items that directly correspond to the user’s input or search terms, modern techniques often employ more sophisticated algorithms like Embedding-based retrieval.
- Ranking of Candidates: Each candidate is scored based on a relevance function. Predictive models, such as twin-tower neural networks, are used to transform both user and candidate data into embeddings. The relevance is then determined by computing the similarity between these embeddings.
- User Interaction and Data Collection: The ranked recommendations are presented to the user, who interacts by clicking or ignoring items. These interactions are then collected to refine and improve future models.
The application of large language models (LLMs) in recommendation systems can be divided into two main categories: discriminative and generative.
- Discriminative Cases: Traditional LLMs such as BERT are utilized for classifying or predicting specific outcomes, focusing on categorizing user inputs or predicting user behaviors based on predefined categories.
- Generative Cases: More recent developments concentrate on models like GPT, which are capable of generating new content or suggestions in human-readable text.
We will explore the generative applications where advanced models, such as GPT-4 and LLaMA 3.1, are being employed to enhance recommendation systems at every stage.
Where to Adapt LLMs in Recommendation Systems
As recommendation systems evolve, the strategic integration of large language models (LLMs) is becoming increasingly crucial. This section explores some of the latest research on how LLMs are being adapted at various stages of the recommendation pipeline.
1. Feature Generation
Feature Augmentation
LLMs can be employed to generate specific features for users or items. For instance, consider the approach used in a product categorization study (refer to the schema described in this paper). The model utilizes structured instruction, which includes components like task description, prompts, input text, candidate labels, output constraints, and the desired output. This structured approach helps in generating precise features tailored to specific recommendation tasks. Few-shot learning and fine-tuning strategies can be used to adapt large language models to specific tasks further.
- Few-shot Learning: This approach “trains” a LLM on a new task by providing it with only a few examples within the prompt, leveraging its pre-trained knowledge to quickly adapt.
- Fine-Tuning: This technique involves additional training of a pre-trained model on a larger, task-specific dataset to enhance its performance by adjusting for the new task
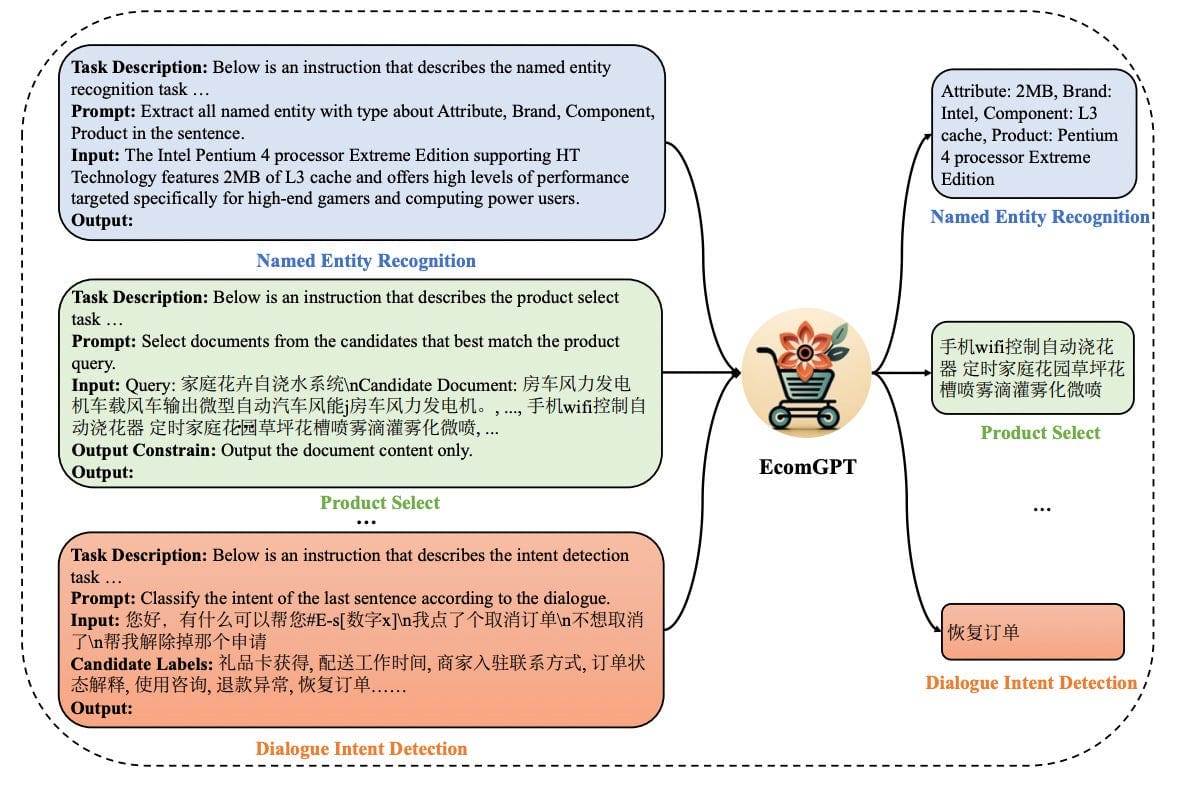
Li et al., 2023: An overview of relevant feature extractions from EcomGPT for diverse E-commerce tasks
Synthetic Label Generation
Synthetic data generation involves creating realistic, artificial data entries for training purposes, as demonstrated in this study The process involves two main steps:
- Context Setting: This initial step establishes a domain-specific context to guide the data generation. For example, using a prompt such as “Imagine you are a movie reviewer” helps set the scene for generating data relevant to movie reviews.
- Data Generation Prompt: After setting the context, the LLM is given specific instructions about the desired output. This includes details on the style of text (e.g., movie review), the sentiment (positive or negative), and any constraints like word count or specific terminology. This ensures the synthetic data aligns closely with the requirements of the recommendation system, making them useful for enhancing its accuracy and effectiveness.
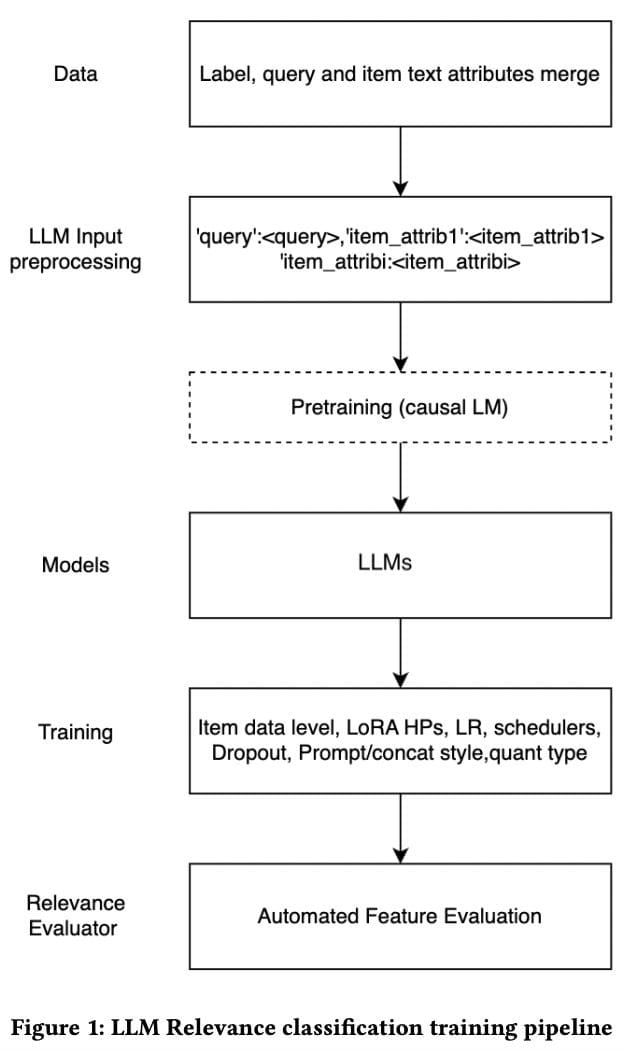
Mehrdad et al., 2024: LLM Relevance classification training pipeline
2. Candidates Generation
The retrieval is designed to select a set of potential candidates for the target user before they can be ranked from a large amount of corpus. There are essentially two types of retrieval mechanisms:
- Bag of Words Retrieval: Converts text into vectors of word frequencies and retrieves documents by measuring similarity (e.g., cosine similarity) between these frequency vectors and the user.
- Embedding-Based Retrieval: Transforms text into dense semantic embeddings and retrieves documents by comparing the semantic similarity (cosine similarity) between the user’s and documents’ embeddings.
LLM Augmented Retrieval
LLM enhances both bag of words and embedding-based retrieval by adding synthetic text (essentially augmenting user request) to better represent both the user side and the document side embeddings. This was presented in this study where each user request query is augmented with similar queries to improve retrieval.
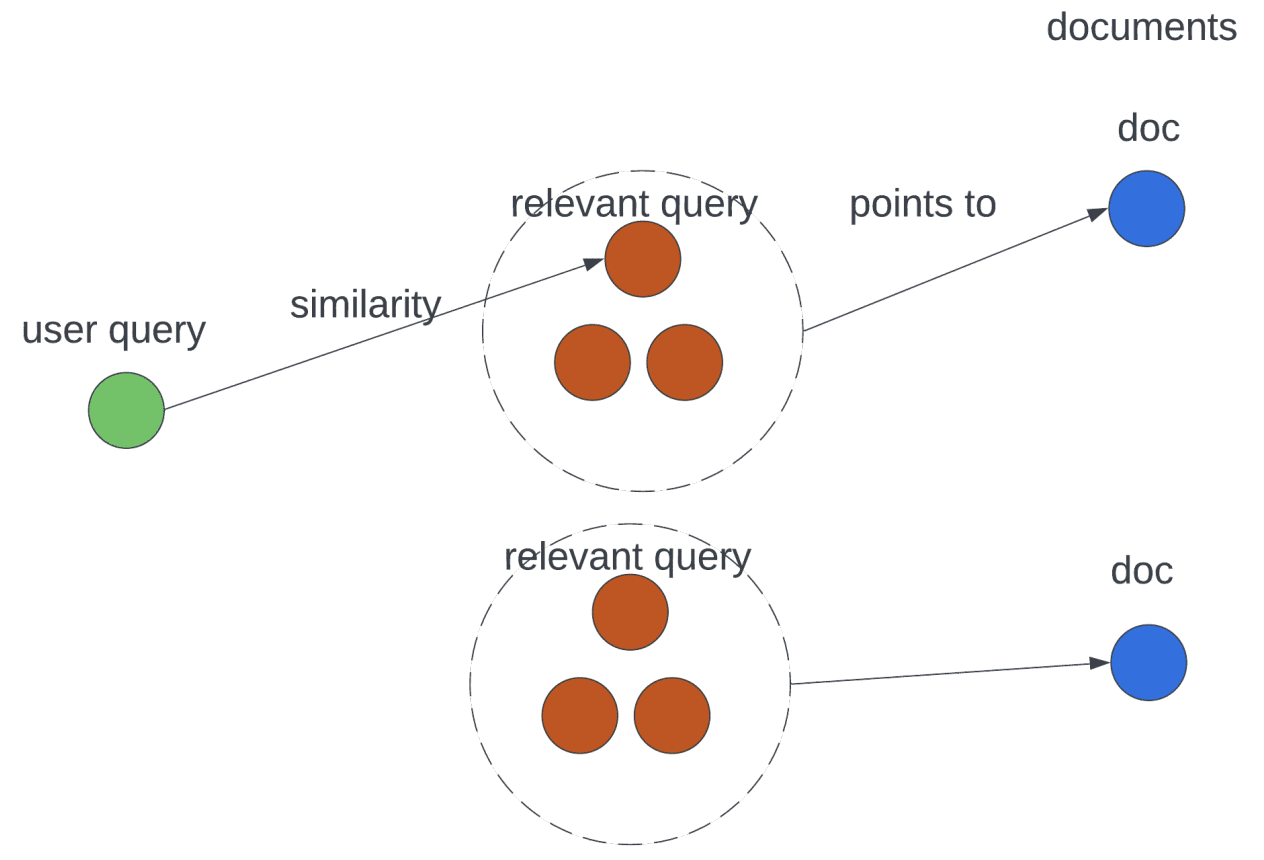
Wu et al., 2024: Through synthetic relevant queries, the relevance relationship is not solely expressed by the similarity now but also expressed by the augmentation steps of the large language models
3. Ranking
Candidate scoring task
The candidate scoring task involves utilizing a LLM as a pointwise function which assigns a score for every target user u and for every candidate c in the candidate set C. The final ranked list of items is generated by sorting these utility scores for each item in the candidate set.
where is a list of ranked candidates.
For candidate scoring tasks, three primary approaches are being used:
Approach 1: Knowledge Distillation
This method employs a dual-model strategy where a student model (typically a smaller language model) learns from a dataset generated by a more complex teacher model, such as an LLaMA 3.1, often enhanced by integrating user attributes. Again techniques such as few-shot learning and fine-tuning are used for adapting the LLM to specific domain cases, allowing the student model to effectively mimic the teacher’s performance while being more efficient. This approach not only improves model scalability but also retains high performance due to only smaller models used for inference, as detailed in the study available at this link.
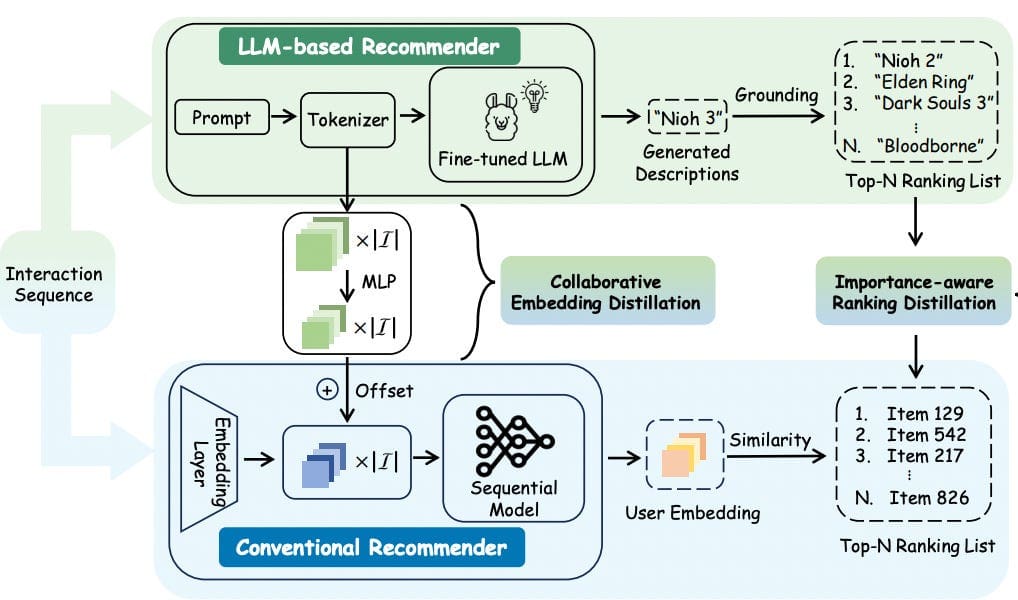
Cui et al., 2024: Illustration of DLLM2Rec that distills the knowledge from the LLM-based recommenders to the conventional recommenders
Approach 2: Score Generation
Score generation techniques, as discussed in this research, involve the LLM generating scores directly from the given prompts, which can then be used to rank items according to these scores by exposing them through caching mechanisms.

Zhiyuli et al., 2023: Prompt examples from BookGPT for generating rating
Approach 3: Score prediction from LLM
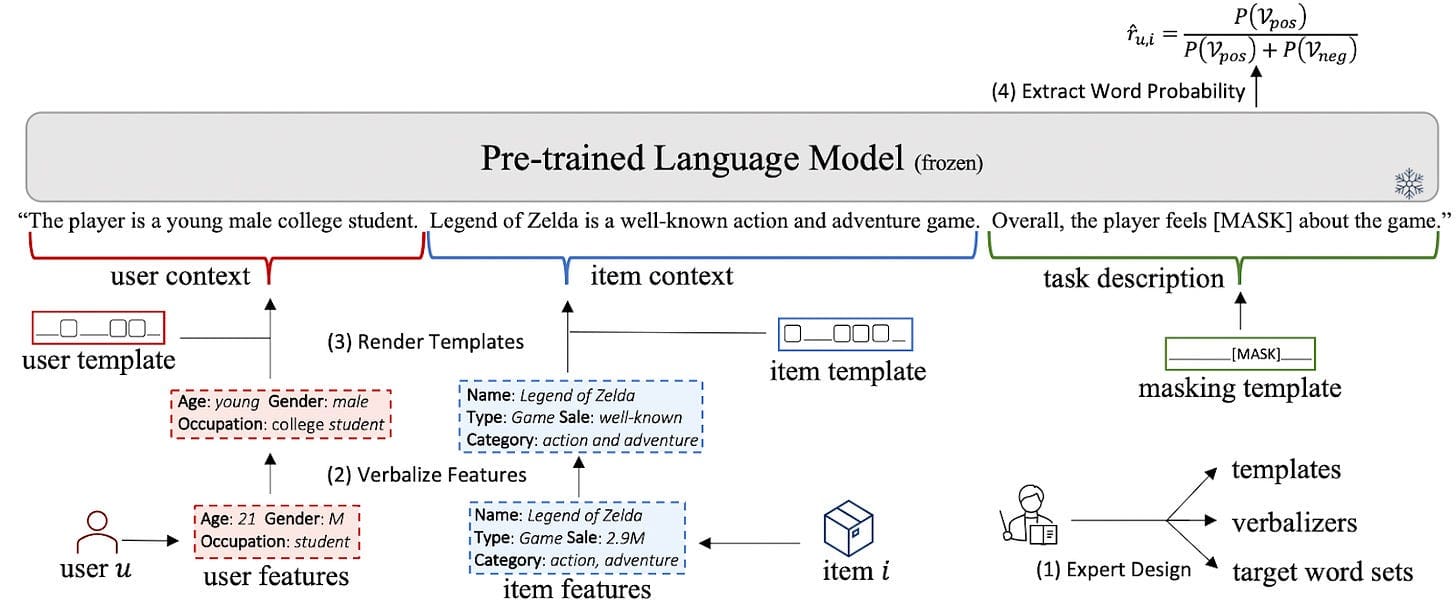
Wu et al., 2023: PromptRec: Prompting PLMs to make personalized recommendations
In this method, the candidate scoring task is transformed into a binary question-answering challenge. The process starts with a detailed textual description of the user profile, behaviors, and target item. The model then answers a question aimed at determining user preferences, generating an estimated score or probability. To refine this approach, modifications include replacing the decoder layer of the LLM with a Multi-Layer Perceptron (MLP) for predictions or using a bidimensional softmax function on the logits of binary answers like “Yes” or “No” to calculate scores (See this study). This simplifies the complex scoring task into a straightforward binary classification problem.
Candidate Generation Task
In item generation tasks, a large language model functions as a generative mechanism, delivering a final ranked list of items instead of sorting it based on scores. Therefore, for every target user u, and for every candidate c in candidate set C, the ranked list becomes:
This method primarily depends on the inherent reasoning skills of the LLM to assess user preferences and generate an appropriately ranked list of suggestions. This is what was proposed in this study.
This ranked list can then be used to cache the most frequently occurring users/requests and update it with batch processing.

Luo et al., 2024: Examples of instructions for top-k recommendation
4. User Interaction and Data Collection
LLMs are evolving the user experience in recommendation systems in several significant and noticeable ways. Perhaps the most transformative application is embedding the recommendation process directly into conversational interfaces like in the case of conversational search engines like perplexity. As discussed in this study, chatbots powered by LLMs that are fine-tuned on attribute-based conversations , where the bot asks users about their preferences before making suggestions, represent a major shift in how recommendations are delivered. This method leverages LLMs directly, moving beyond enhancing existing models.
It introduces a new paradigm where technologies like Retrieval Augmented Generation (RAG) play a crucial role. In the context of recommendation systems, particularly those integrated into conversational agents, RAG can help by pulling relevant and timely information to make more informed suggestions based on the user’s current context or query.
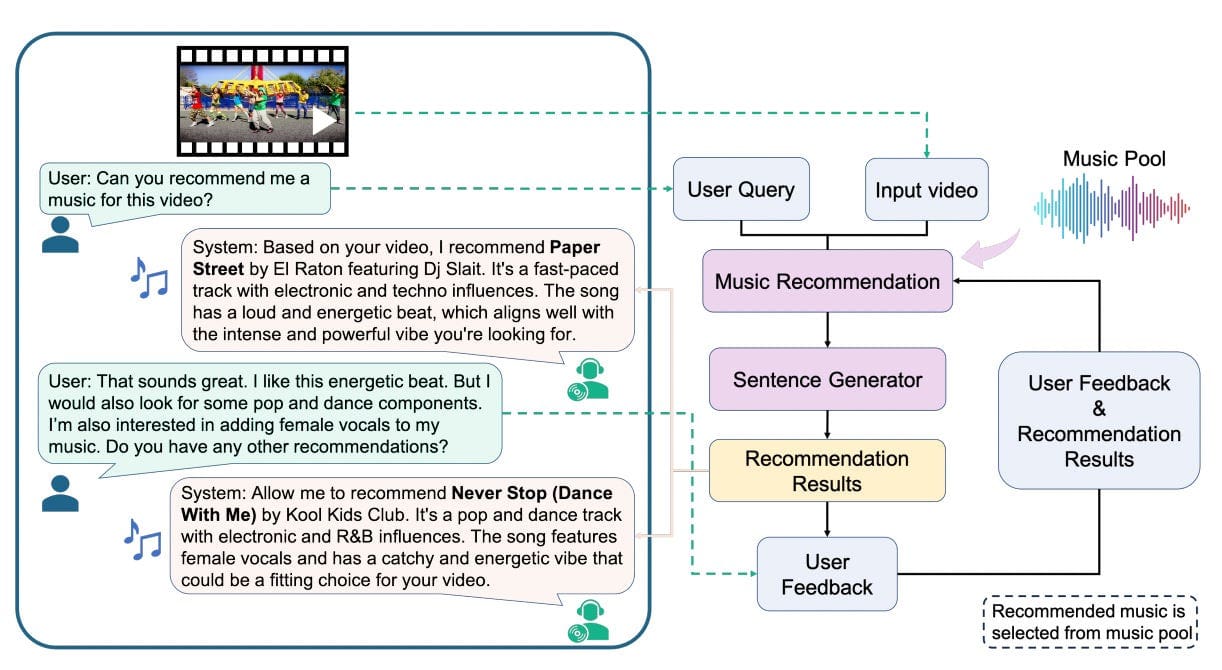
Dong et al., 2024: A conversational music recommendation system. It features two modules: the Music Recommendation Module, which processes either video input alone or in combination with user prompts and past music suggestions, and the Sentence Generator Module, which uses these inputs to create natural language music recommendations
Conclusion
Throughout the latest studies, we’ve seen how LLMs are reshaping recommendation systems despite challenges like high latency that prevent them from being the primary inference model. While LLMs currently empower backend improvements in feature generation and predictive accuracy, ongoing advancements like quantization in computational efficiency will eventually mitigate latency issues. This will enable the direct integration of LLMs, dramatically enhancing their responsiveness and deliver seamless, intuitive experiences that improve user experience.
Acknowledgement
I would like to extend my sincere gratitude to Kanwal Mehreen, who provided invaluable feedback and insights during the peer review process of this article. Her expertise greatly enhanced the quality of the content, and her suggestions were crucial in refining the final version.
References
[1] Wu, Likang, et al. “A survey on large language models for recommendation.” arXiv preprint arXiv:2305.19860 (2023)
[2] Li, Yangning, et al. “Ecomgpt: Instruction-tuning large language models with chain-of-task tasks for e-commerce.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 38. №17. 2024
[3] Mehrdad, Navid, et al. “Large Language Models for Relevance Judgment in Product Search.” arXiv preprint arXiv:2406.00247 (2024)
[4] Wu, Mingrui, and Sheng Cao. “LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding.” arXiv preprint arXiv:2404.05825 (2024)
[5] Cui, Yu, et al. “Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model.” arXiv preprint arXiv:2405.00338 (2024)
[6] Li, Zhiyu, et al. “Bookgpt: A general framework for book recommendation empowered by large language model.” Electronics 12.22 (2023): 4654
[7] Wu, Xuansheng, et al. “Towards personalized cold-start recommendation with prompts.” arXiv preprint arXiv:2306.17256 (2023)
[8] Luo, Sichun, et al. “Integrating large language models into recommendation via mutual augmentation and adaptive aggregation.” arXiv preprint arXiv:2401.13870 (2024)
[9] Dong, Zhikang, et al. “Musechat: A conversational music recommendation system for videos.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024
If this article was helpful to you and you want to learn more about real-world tips for Machine Learning, connect with me on LinkedIn.
Kartik Singhal is a Senior Machine Learning Engineer at Meta with over 6 years of experience with a focus on Search and Recommendations. He has previously worked at Amazon in Dynamic Pricing and forecasting. He is driven by his passion for applying the latest research in Machine Learning and has previously mentored many engineers and students who wanted to get into Machine Learning.