

Understanding RAG Part I: How Classic RAG Works
Image by Editor | Midjourney & Canva
In the first post in this series, we introduced retrieval augmented generation (RAG), explaining that it became necessary to expand the capabilities of conventional large language models (LLMs). We also briefly outlining what is the key idea underpinning RAG: retrieving contextually relevant information from external knowledge bases to ensure that LLMs produce accurate and up-to-date information, without suffering from hallucinations and without the need for constantly re-training the model.
The second article in this revealing series demystifies the mechanisms under which a conventional RAG system operates. While many enhanced and more sophisticated versions of RAG keep spawning almost daily as part of the frantic AI progress nowadays, the first step to understanding the latest state-of-the-art RAG approaches is to first comprehend the classic RAG workflow.
The Classic RAG Workflow
A typical RAG system (depicted in the diagram below) handles three key data-related components:
- An LLM that has acquired knowledge from the data it has been trained with, typically millions to billions of text documents.
- A vector database, also called knowledge base storing text documents. But why the name vector database? In RAG and natural language processing (NLP) systems as a whole, text information is transformed into numerical representations called vectors, capturing the semantic meaning of the text. Vectors represent words, sentences, or entire documents, maintaining key properties of the original text such that two similar vectors are associated with words, sentences, or pieces of text with similar semantics. Storing text as numerical vectors enhances the system’s efficiency, such that relevant documents are quickly found and retrieved.
- Queries or prompts formulated by the user in natural language.
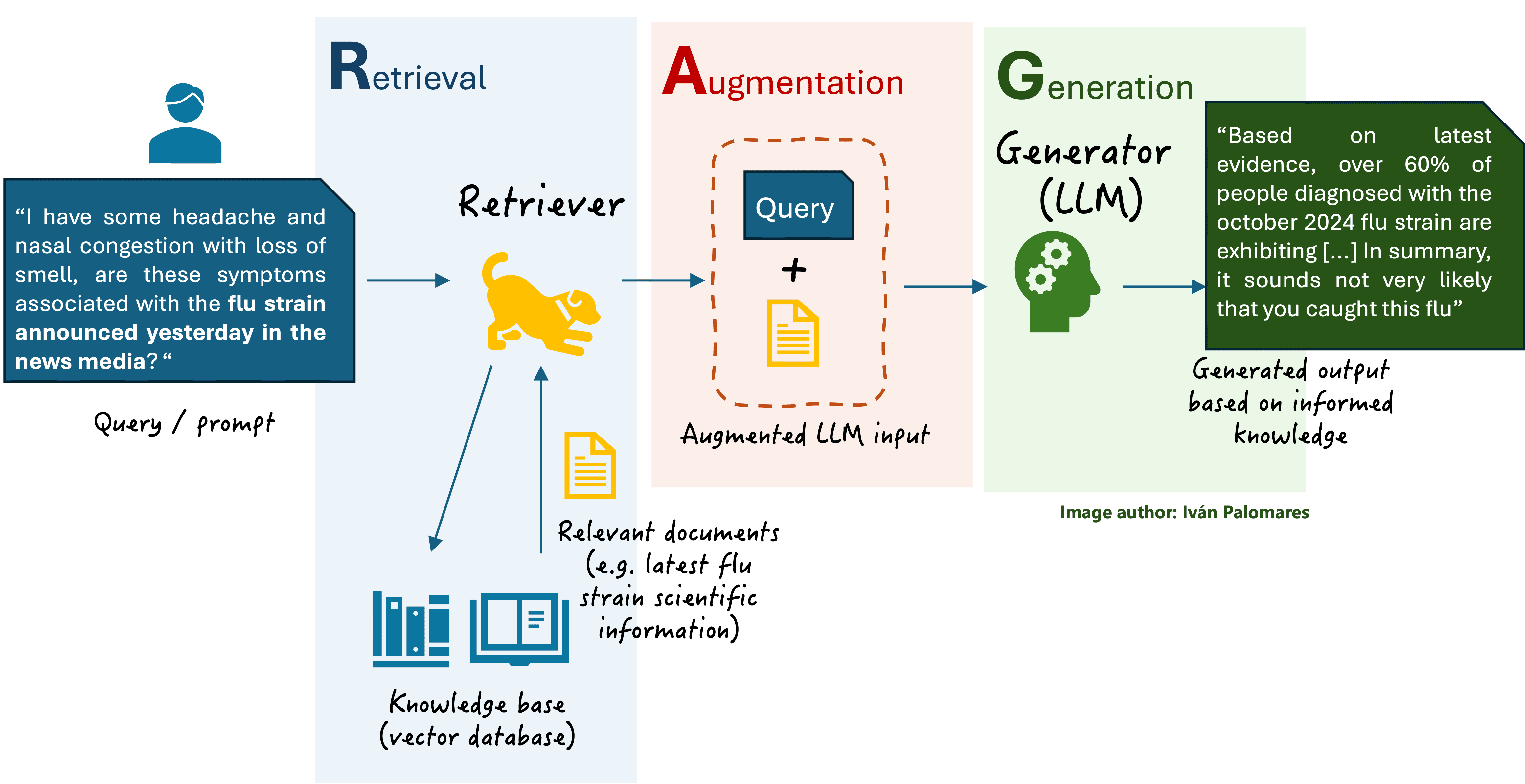
General scheme of a basic RAG system
In a nutshell, when the user asks a question in natural language to an LLM-based assistant endowed with an RAG engine, three stages take place between sending the question and receiving the answer:
- Retrieval: a component called retriever accesses the vector database to find and retrieve relevant documents to the user query.
- Augmentation: the original user query is augmented by incorporating contextual knowledge from the retrieved documents.
- Generation: the LLM -also commonly referred to as generator from an RAG viewpoint- receives the user query augmented with relevant contextual information and generates a more precise and truthful text response.
Inside the Retriever
The retriever is the component in an RAG system that finds relevant information to enhance the final output later generated by the LLM. You can picture it like an enhanced search engine that doesn’t just match keywords in the user query to stored documents but understands the meaning behind the query.
The retriever scans a vast body of domain knowledge related to the query, stored in vectorized format (numerical representations of text), and pulls out the most relevant pieces of text to build a context around them which is attached to the original user query. A common technique to identify relevant knowledge is similarity search, where the user query is encoded into a vector representation, and this vector is compared to stored vector data. This way, detecting the most relevant pieces of knowledge to the user query, boils down to iteratively performing some mathematical calculations to identify the closest (most similar) vectors to the vector representation of that query. And thus, the retriever manages to pull accurate, context-aware information not only efficiently, but also accurately.
Inside the Generator
The generator in RAG is typically a sophisticated language model, often an LLM based on transformer architecture, which takes the augmented input from the retriever and produces an accurate, context-aware, and usually truthful response. This outcome normally surpasses the quality of a standalone LLM by incorporating relevant external information.
Inside the model, the generation process involves both understanding and generating text, managed by components that encode the augmented input and generate output text word by word. Each word is predicted based on the preceding words: this task, performed as the last stage inside the LLM, is known as the next-word prediction problem: predicting the most likely next word to maintain coherence and relevance in the message being generated.
This post further elaborates on the language generation process led by the generator.
Looking Ahead
In the next post in this article series about understanding RAG, we will uncover fusion methods for RAG, characterized by using specialized approaches for combining information from multiple retrieved documents, thereby enhancing the context for generating a response.
One common example of fusion methods in RAG is reranking, which involves scoring and prioritizing multiple retrieved documents based on their user relevance before passing the most relevant ones to the generator. This helps further improve the quality of the augmented context, and the eventual responses produced by the language model.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.