

Image by Author
GPT-4o is good for general tasks, but it may struggle with specific use cases. To address this, we can work on refining the prompts for better output. If that doesn’t work, we can try function calling. If issues persist, we can use the RAG pipeline to gather additional context from documents.
In most cases, fine-tuning GPT-4o is considered the last resort due to the high cost, longer training time, and expertise required. However, if all the aforementioned solutions have been attempted and the goal is to modify style and tone and improve accuracy for a specific use case, then fine-tuning the GPT-4 model on a custom dataset is an option.
In this tutorial, we will learn how to set up the OpenAI Python API, load and process data, upload the processed dataset to the cloud, fine-tune the GPT-4o model using the dataset, and access the fine-tuned model.
Setting Up
We will be using the Legal Text Classification dataset from Kaggle to fine-tune the GPT-4o model. The first thing we need to do is download the CSV file and load it using Pandas. After that, we will drop the minor classes from the dataset, keeping only the top 5 legal text labels. It’s important to understand the data by performing data analysis before we begin the fine-tuning process.
import pandas as pd
df = pd.read_csv("legal_text_classification.csv", index_col=0)
# Data cleaning
df = df.drop(df[df.case_outcome == "discussed"].index)
df = df.drop(df[df.case_outcome == "distinguished"].index)
df = df.drop(df[df.case_outcome == "affirmed"].index)
df = df.drop(df[df.case_outcome == "approved"].index)
df = df.drop(df[df.case_outcome == "related"].index)
df.head()
The dataset contains columns for case_outcomes, case_title, and case_text. All of these columns will be used to create our prompt for model training.

Next, we will install the OpenAI Python package.
%%capture
%pip install openai
We will now load the OpenAI API key from an environment variable and use it to initialize the OpenAI client for the chat completion function.
To generate the response, we will create a custom prompt. It contains system instructions telling the model what to do. In our case, it tells it to classify legal text into known categories. Then, we create the user query using the case title, case text, and assistant role to generate only a single label.
from IPython.display import Markdown, display
from openai import OpenAI
import os
categories = df.case_outcome.unique().tolist()
openai_api_key = os.environ["OPENAI_API_KEY"]
client = OpenAI(api_key=openai_api_key)
response = client.chat.completions.create(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": f"Classify the following legal text based on the outcomes of the case. Please categorize it in to {categories}.",
},
{
"role": "user",
"content": f"Case Title: {df.case_title[0]} \n\nCase Text: {df.case_text[0]}",
},
{"role": "assistant", "content": "Case Outcome:"},
],
)
display(Markdown(response.choices[0].message.content))
The response is accurate, but it is lost in the test. We only want it to generate “cited” instead of generating the text.
The case "Alpine Hardwood (Aust) Pty Ltd v Hardys Pty Ltd (No 2) 2002 FCA 224; (2002) 190 ALR 121" is cited in the given text.
Creating the Dataset
We will shuffle the dataset and extract only 200 samples. We can train the model on the full dataset, but it will cost more, and the model training time will increase.
After that, the dataset will be split into training and validation sets.
Write the function that will use the prompt style and dataset to create the messages and then save the dataset as a JSONL file. The prompt style is similar to the one we used earlier.
We will convert the train and validation datasets into the JSONL file format and save them in the local directory.
import json
from sklearn.model_selection import train_test_split
# shuffle the dataset and select the top 200 rows
data_cleaned = df.sample(frac=1).reset_index(drop=True).head(200)
# Split the data into training and validation sets (80% train, 20% validation)
train_data, validation_data = train_test_split(
data_cleaned, test_size=0.2, random_state=42
)
def save_to_jsonl(data, output_file_path):
jsonl_data = []
for index, row in data.iterrows():
jsonl_data.append(
{
"messages": [
{
"role": "system",
"content": f"Classify the following legal text based on the outcomes of the case. Please categorize it in to {categories}.",
},
{
"role": "user",
"content": f"Case Title: {row['case_title']} \n\nCase Text: {row['case_text']}",
},
{
"role": "assistant",
"content": f"Case Outcome: {row['case_outcome']}",
},
]
}
)
# Save to JSONL format
with open(output_file_path, "w") as f:
for item in jsonl_data:
f.write(json.dumps(item) + "\n")
# Save the training and validation sets to separate JSONL files
train_output_file_path = "legal_text_classification_train.jsonl"
validation_output_file_path = "legal_text_classification_validation.jsonl"
save_to_jsonl(train_data, train_output_file_path)
save_to_jsonl(validation_data, validation_output_file_path)
print(f"Training dataset save to {train_output_file_path}")
print(f"Validation dataset save to {validation_output_file_path}")
Output:
Training dataset save to legal_text_classification_train.jsonl
Validation dataset save to legal_text_classification_validation.jsonl
Uploading the Processed Dataset
We will use the’ files’ function to upload training and validation files into the OpenAI cloud. Why are we uploading these files? The fine-tuning process occurs in the OpenAI cloud, and uploading these files is essential so the cloud can easily access them for training purposes.
train_file = client.files.create(
file=open(train_output_file_path, "rb"),
purpose="fine-tune"
)
valid_file = client.files.create(
file=open(validation_output_file_path, "rb"),
purpose="fine-tune"
)
print(f"Training File Info: {train_file}")
print(f"Validation File Info: {valid_file}")
Output:
Training File Info: FileObject(id='file-fw39Ok3Uqq5nSnEFBO581lS4', bytes=535847, created_at=1728514772, filename="legal_text_classification_train.jsonl", object="file", purpose="fine-tune", status="processed", status_details=None)
Validation File Info: FileObject(id='file-WUvwsCYXBOXE3a7I5VGxaoTs', bytes=104550, created_at=1728514773, filename="legal_text_classification_validation.jsonl", object="file", purpose="fine-tune", status="processed", status_details=None)
If you go to your OpenAI dashboard and storage menu, you will see that your files have been uploaded securely and are ready to use.
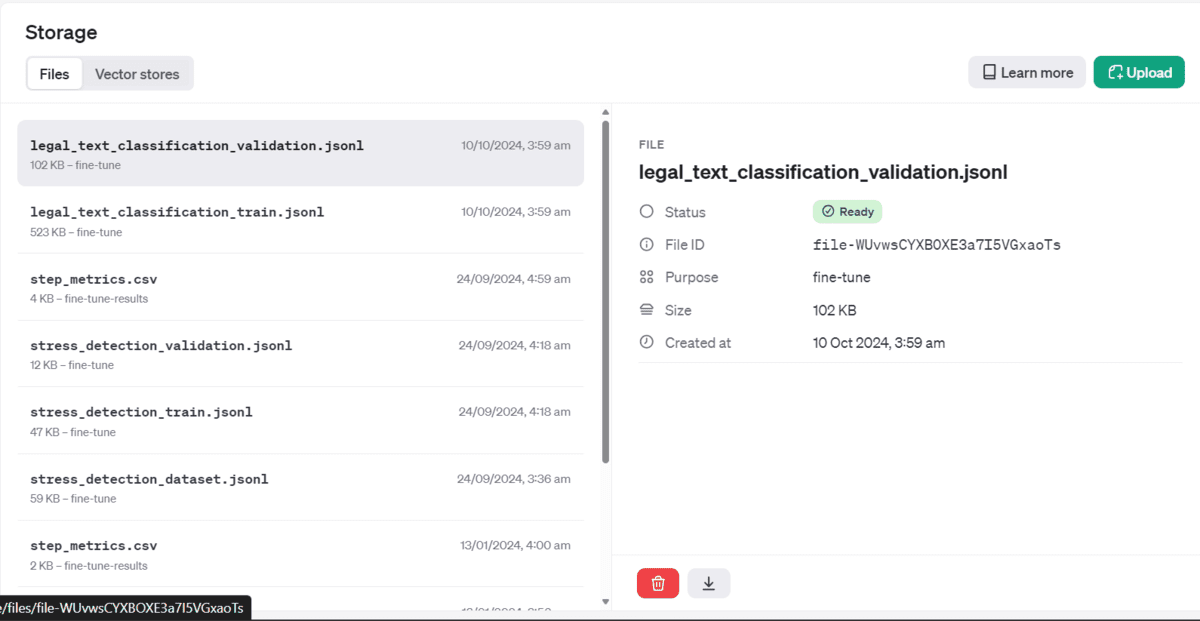
Starting the Fine-tuning Job
We will now create the fine-tuning job by providing the function with training and validation file id, model name, and hyperparameters.
model = client.fine_tuning.jobs.create(
training_file=train_file.id,
validation_file=valid_file.id,
model="gpt-4o-2024-08-06",
hyperparameters={
"n_epochs": 3,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = model.id
status = model.status
print(f'Fine-tuning model with jobID: {job_id}.')
print(f"Training Response: {model}")
print(f"Training Status: {status}")
As soon as we run this function, the training job will be initiated, and we can view the job status, job ID, and other metadata.
Fine-tuning model with jobID: ftjob-9eDrKudkFJps0DqG66zeeDEP.
Training Response: FineTuningJob(id='ftjob-9eDrKudkFJps0DqG66zeeDEP', created_at=1728514787, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=3, batch_size=3, learning_rate_multiplier=0.3), model="gpt-4o-2024-08-06", object="fine_tuning.job", organization_id='org-jLXWbL5JssIxj9KNgoFBK7Qi', result_files=[], seed=1026890728, status="validating_files", trained_tokens=None, training_file="file-fw39Ok3Uqq5nSnEFBO581lS4", validation_file="file-WUvwsCYXBOXE3a7I5VGxaoTs", estimated_finish=None, integrations=[], user_provided_suffix=None)
Training Status: validating_files
You can even view the job status on the OpenAI dashboard too.
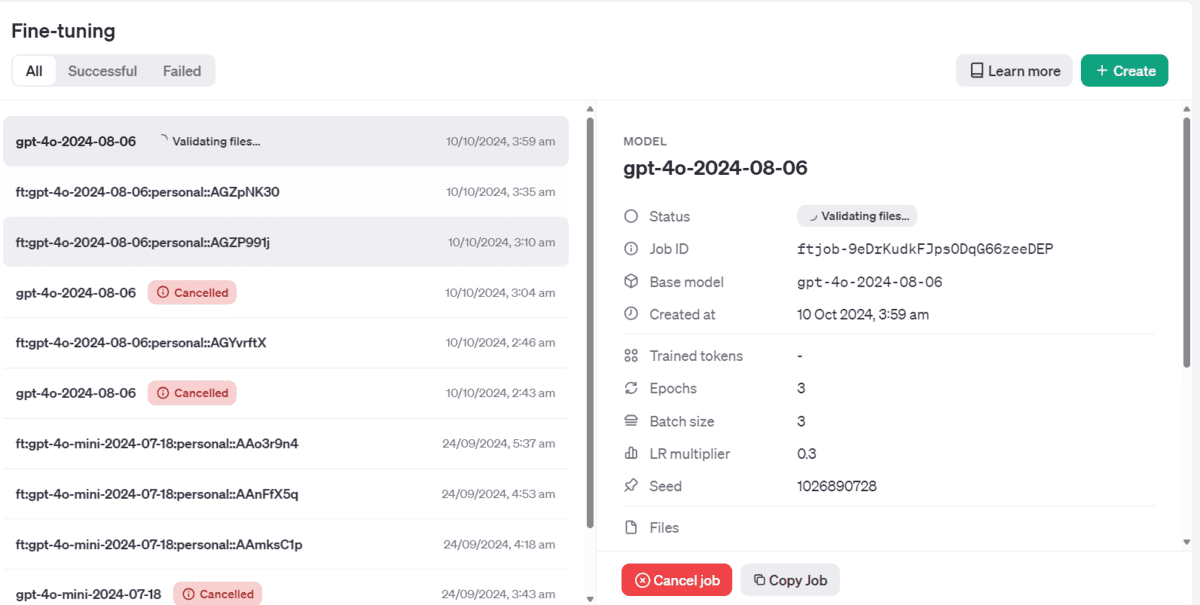
When the fine-tuning job is finished, we will receive an email containing all the information on how to use the fine-tuned model.

Accessing the Fine-tuned Model
To access the fine-tuned model, we first need to access the model name. We can do that by retrieving the fine-tuning job information, selecting the latest job, and then choosing the fine-tuned model name.
result = client.fine_tuning.jobs.list()
# Retrieve the fine-tuned model
fine_tuned_model = result.data[0].fine_tuned_model
print(fine_tuned_model)
This is our fine-tuned model name. We can start using it by directly typing it in the chat completion function.
ft:gpt-4o-2024-08-06:personal::AGaF9lqH
To generate a response, we will use the chat completion function with the fine-tuned model name and messages in a style similar to the dataset.
completion = client.chat.completions.create(
model=fine_tuned_model,
messages=[
{
"role": "system",
"content": f"Classify the following legal text based on the outcomes of the case. Please categorize it in to {categories}.",
},
{
"role": "user",
"content": f"Case Title: {df['case_title'][10]} \n\nCase Text: {df['case_text'][10]}",
},
{"role": "assistant", "content": "Case Outcome:"},
],
)
print(f"predicated: {completion.choices[0].message.content}")
print(f"actual: {df['case_outcome'][10]}")
As we can see, instead of providing the whole sentence it has just returned the label and the correct label.
predicated: cited
actual: cited
Let’s try to classify the 101th sample in the dataset.
completion = client.chat.completions.create(
model=fine_tuned_model,
messages=[
{
"role": "system",
"content": f"Classify the following legal text based on the outcomes of the case. Please categorize it in to {categories}.",
},
{
"role": "user",
"content": f"Case Title: {df['case_title'][100]} \n\nCase Text: {df['case_text'][100]}",
},
{"role": "assistant", "content": "Case Outcome:"},
],
)
print(f"predicated: {completion.choices[0].message.content}")
print(f"actual: {df['case_outcome'][100]}")
This is good. We have successfully fine-tuned our model. To further improve the performance, I suggest fine-tuning the model on the full dataset and training it for at least 5 epochs.
predicated: considered
actual: considered
Final thoughts
Fine-tuning GPT-4o is simple and requires minimal effort and hardware. All you need to do is add a credit card to your OpenAI account and start using it. If you are not a Python programmer, you can always use the OpenAI dashboard to upload the dataset, start the fine-tuning job, and use it in the playground. OpenAI provides a low/no-code solution, and all you need is a credit card.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in technology management and a bachelor’s degree in telecommunication engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.