
A Practical Guide to Choosing the Right Algorithm for Your Problem: From Regression to Neural Networks
Image by Editor | Ideogram
This article explains, through clear guidelines, how to choose the right machine learning (ML) algorithm or model for different types of real-world and business problems. Knowing to decide on the right ML algorithm is crucial because the success of any ML project depends on the correctness of this choice.
The article starts by presenting a question-based template and finalizes with a tabular set of example use cases and justifications behind the selection of the best algorithm for each one. Examples span from simple to more advanced problems requiring modern AI capabilities like language models.
Note: For simplicity, the article will make a generalized use of the term ML algorithm to refer to all kinds of ML algorithms, models, and techniques. Most ML techniques are model-based, with a model used for inference built as a result of applying an algorithm, hence in a more deeply technical context, these terms should be differentiated.
A Question-Based Template
The following key questions are designed to guide AI, ML, and data analysis project leaders to the right choice of ML algorithm to use for addressing their specific problem.
Key Question 1: What type of problem do you need to solve?
- 1.A. Do you need to predict something?
- 1.B. If so, is it a numerical value, or classification into categories?
- 1.C. If you want to predict a numerical value, is it based on other variables or features? Or are you predicting future values based on past historical ones?
The three questions above are related to predictive or supervised learning approaches. Replying yes to question 1.A means you are looking for a supervised learning algorithm because you need to predict something unknown about your new or future data. Depending on what you want to predict, and how, you may be facing a classification, regression, or time series forecasting task. Which one? That’s what questions 1.B and 1.C will help you determine.
If you want to predict or assign categories, you are facing a classification task. If you want to predict a numerical variable, such as house price, based on other features like house characteristics, that’s a regression task. Finally, if you want to predict a future numerical value based on past ones, e.g. predict a business seat price of a flight based on a daily history of its average past prices, then you are against a time series forecasting task.
Back to 1.A, if you replied no to this question, and instead you want to get a better understanding of your data or discover hidden patterns in them, chances are an unsupervised learning algorithm is what you are looking for. For instance, if you want to discover hidden groups in your data (think of finding segments of customers), your target task is clustering, and if you wish to identify abnormal transactions or unusual attempts to log in to a high-security system, anomaly detection algorithms are your go-to approach.
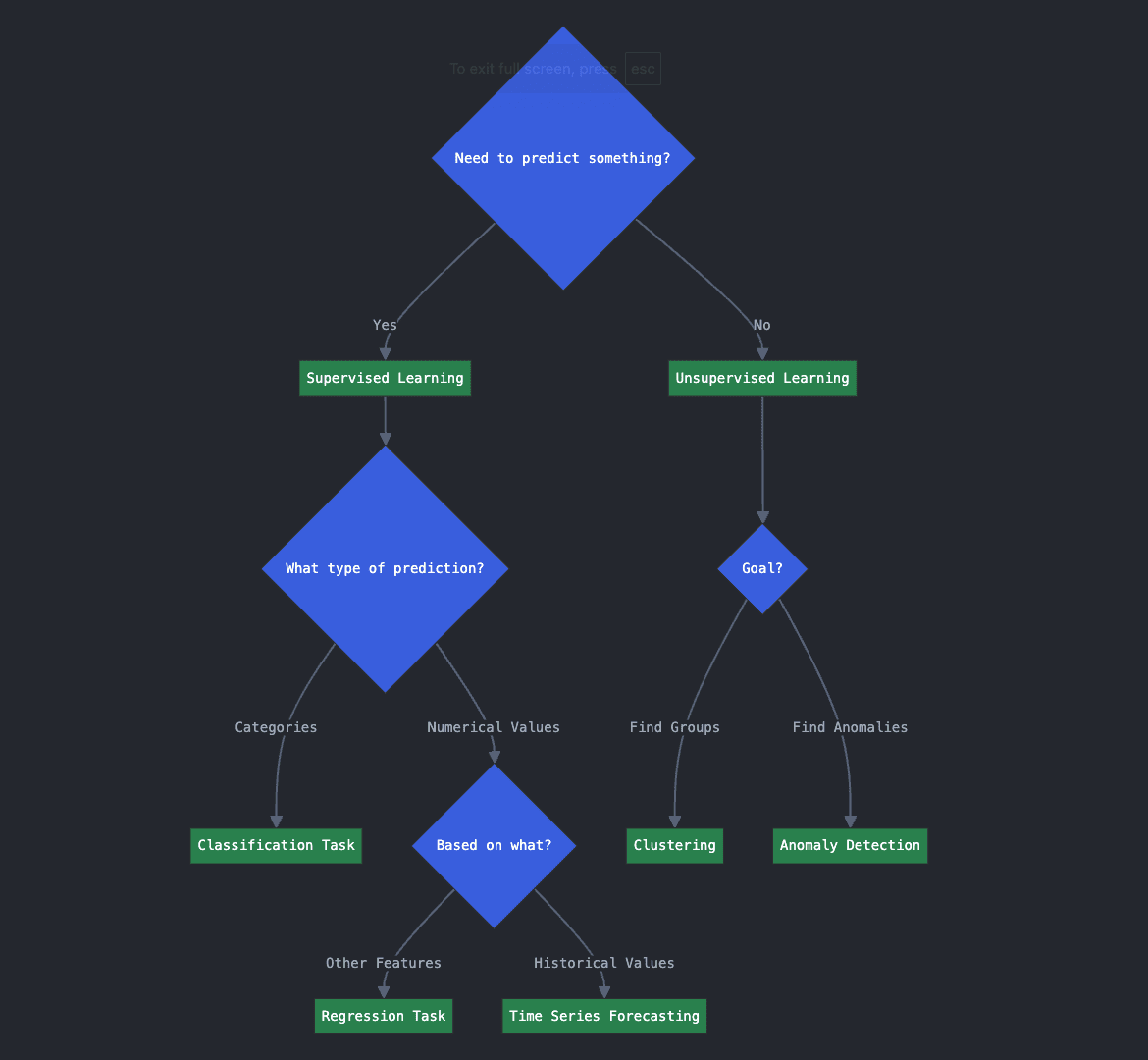
Decision flowchart for Key Question 1 (click to enlarge)
Image by Editor
Key Question 2: What type of data do you have?
Even if your answer to the previous question group was obvious and you have a clear target task in mind, some ML tasks have a variety of available algorithms to use. Which one would you choose? Part of that answer lies in your data, its volume, and its complexity.
2.A. Structured and simpler data arranged in tables with few attributes, can be leveraged with simple ML algorithms like linear regression, decision tree classifiers, k-means clustering, etc.
2.B. Data with intermediate complexity, e.g. still structured but having dozens of attributes, or low-resolution images, might be addressed with ensemble methods for classification and regression, which combine multiple ML model instances into one to attain better predictive results. Examples of ensemble methods are random forests, gradient boosting, and XGBoost. For other tasks like clustering, try algorithms like DBSCAN or spectral clustering.
2.C. Last, highly complex data like images, text, and audio usually require more advanced architectures like deep neural networks: harder to train, but more effective in solving challenging problems when they have been exposed to considerable volumes of data examples for learning. For very advanced use cases like understanding and generating high volumes of language (text) data, you may even need to consider powerful transformer-based architectures like large language models (LLMs).
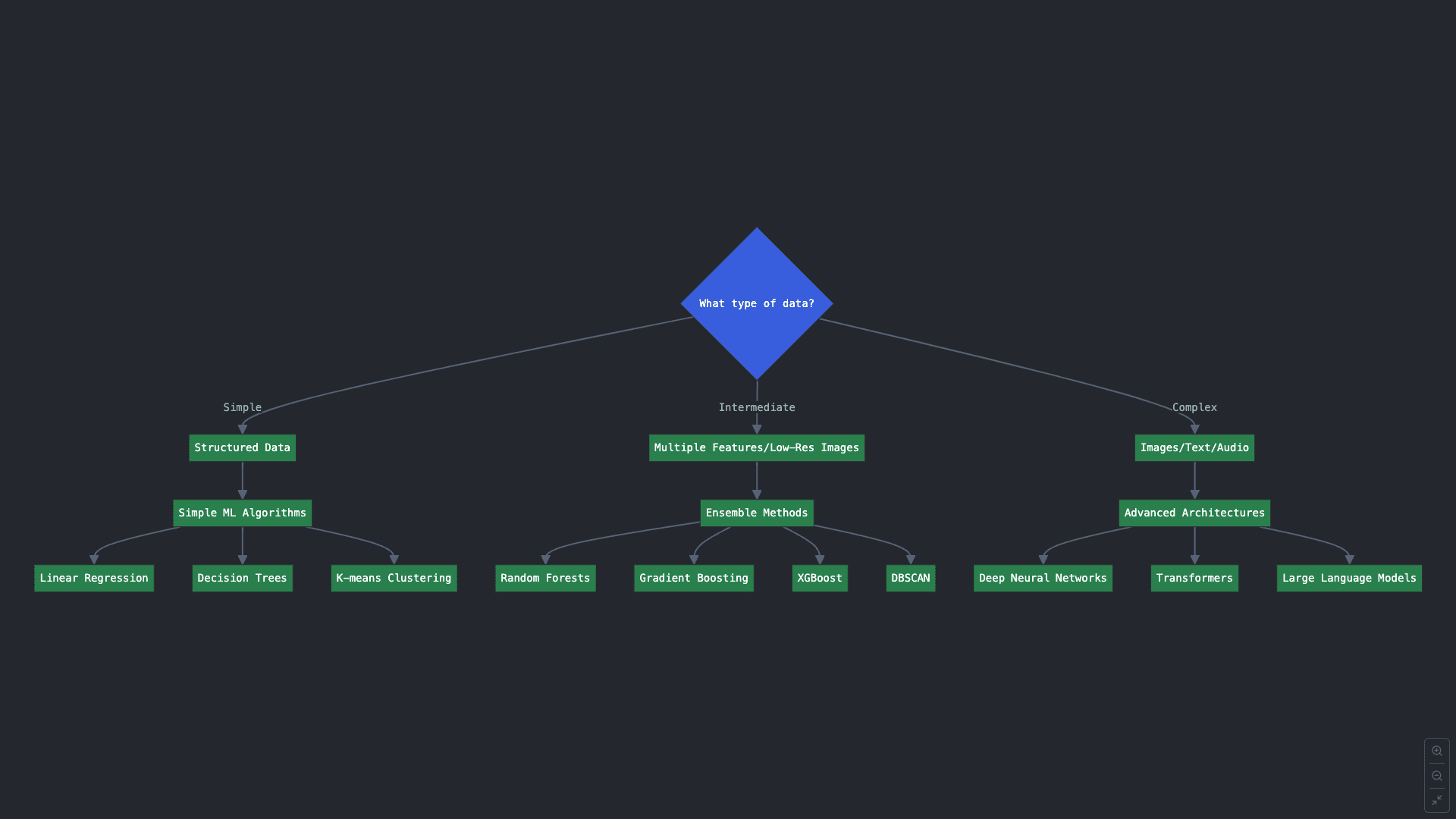
Decision flowchart for Key Question 2 (click to enlarge)
Image by Editor
Key Question 3: What level of interpretability do you need?
In certain contexts where it is important to understand how an ML algorithm makes decisions like predictions, which input factors influence the decision, and how, interpretability is another important aspect that may influence your algorithm choice. As a rule of thumb, the simpler the algorithm, the more interpretable. Thus, linear regression and small decision trees are among the most interpretable solutions, whereas deep neural networks with sophisticated inner architectures are typically referred to as black-box models due to the difficulty of interpreting decisions and understanding their behavior. If a balance between interpretability and high effectiveness against complex data is needed, decision tree-based ensemble methods like random forests are often a good trade-off solution.
Key Question 4: What volume of data do you handle?
This one is closely related to key question 2. Some ML algorithms are more efficient than others, depending on the volume of data used for training them. On the other hand, complex options like neural networks normally require larger amounts of data to learn to perform the task they are built for, even at the cost of sacrificing efficient training. A good rule here is that data volume is in most cases tightly related to data complexity when it comes to choosing the right type of algorithm.
Application Examples
To wrap up and supplement this guide, here is a table with some real-world use cases, where the decision factors considered in this article are outlined:
| Use Case | Problem Type | Recommended Algorithm | Data | Key Considerations |
|---|---|---|---|---|
| Predict monthly sales | Regression | Linear Regression | Structured data | Interpretable, fast, effective for small data |
| Fraud detection in transactions | Binary Classification | Logistic Regression, SVM | Structured data | Balance between precision and speed |
| Product classification in images | Image Classification | Convolutional Neural Networks (CNN) | Images (unstructured data) | High precision, high computational cost |
| Sentiment analysis in product reviews | Text Classification (NLP) | Transformer models (BERT, GPT) | Text (unstructured data) | Requires advanced resources, highly accurate |
| Churn prediction with large datasets | Classification or Regression | Random Forest, Gradient Boosting | Structured and large datasets | Less interpretable, highly effective for Big Data |
| Automatic text generation or answering queries | Advanced NLP | Large Language Models (GPT, BERT) | Large text volumes | High computational cost, precise results |
Discover How Machine Learning Algorithms Work!

See How Algorithms Work in Minutes
…with just arithmetic and simple examples
Discover how in my new Ebook:
Master Machine Learning Algorithms
It covers explanations and examples of 10 top algorithms, like:
Linear Regression, k-Nearest Neighbors, Support Vector Machines and much more…
Finally, Pull Back the Curtain on
Machine Learning Algorithms
Skip the Academics. Just Results.
See What’s Inside