
Image by Editor | Ideogram & Canva
Retrieval augmented generation (RAG) has expanded the limits of conventional large language models (LLMs) by integrating external information retrieval mechanisms in the LLM’s prompt-to-response workflow. Issues like model hallucinations, knowledge obsolescence and the need for periodically retraining the LLM at a high cost, can be to some degree alleviated thanks to RAG.
A detailed introduction and motivation for RAG can be found in this article, and a basic RAG scheme is depicted in the below diagram.
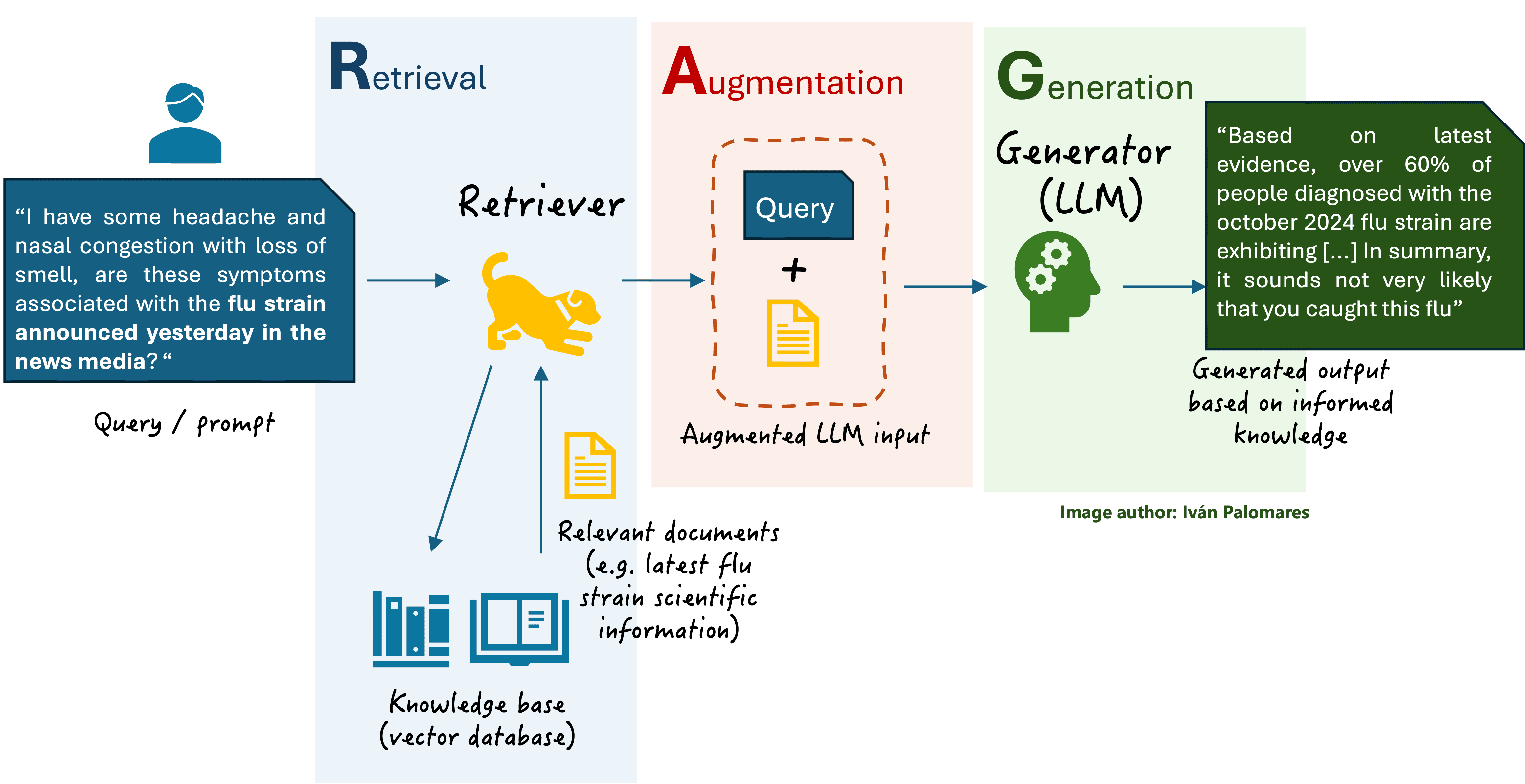
Classical RAG scheme
Image by Author
This post introduces graph RAG, a step forward concerning classical RAG that uses graph structures to retrieve pieces of information and capture relationships between them. This improved retrieval scheme further enhances the LLM’s ability to generate contextually relevant responses built upon interconnected facts, making it more effective for challenging user queries.
What is a Graph?
In simple words, a graph is a data structure that represents a set of entities and relationships between them. Entities are represented by nodes, and relationships are given by edges connecting nodes. In a knowledge base, i.e. a set of documents used by an information retrieval mechanism like those in RAG, graphs can be used for modeling interconnected documents. Consider the example graph below, consisting of scientific documents about the biological phenomenon of photosynthesis. If nodes depict individual documents, edges could indicate citations between documents, links to them in the case of web documents, and so on. In short, graph structures are suitable for efficiently navigating and analyzing sets of interrelated data objects such as documents.

Example graph of biology documents
Image by Author | Claude
Graph RAG Demystified
Compared to vanilla RAG, graph RAG provides more comprehensive and contextually relevant responses based on interconnected “sub-responses” or facts. Let’s learn how graph RAG works through an example.
Consider the following user prompt: “How do light-dependent reactions and the Calvin cycle work together in photosynthesis?“
A classical RAG system (see diagram above) would first use the prompt as a query to search and retrieve relevant, similar content from an external knowledge base. After retrieving the K most relevant documents and enriching the user prompt with context extracted from them, the LLM would process the augmented input and generate a response, for instance:
"Light-dependent reactions and the Calvin cycle are two main stages of
photosynthesis. Light-dependent reactions occur in thylakoid membranes
and produce ATP and NADPH. The Calvin cycle, also known as the light-independent
reactions, uses these products to fix carbon dioxide into glucose. This cycle
occurs in the stroma of chloroplasts."
A biologist specialized in photosynthesis would probably say that this is a factually correct response, but it lacks important details and aspects to answer the question. For example, it doesn’t explain how the two processes mentioned — light-dependent reactions and the carbon fixation lifecycle — work together.
Now, let’s see what happens when the same prompt is supplied to a graph RAG system:
- After tokenizing and converting the query to a numerical vector representation (embedding), the retriever identifies relevant nodes in the knowledge graph, such as: “photosynthesis overview”, “light-dependent reactions”, and “carbon fixation lifecycle”.
- Apply a graph traversal algorithm to traverse the graph and find connected nodes and their relationships. This is like finding “relatives” of the identified documents up to a certain level of “kinship”. This process is the key step of graph RAG whereby relevant documents are found, beyond just looking at similarity with the user query.
- Retrieve and rank relevant documents based on vector similarity and graph structure criteria.
- Augment the user prompt with retrieved information and pass it to the LLM to generate a response.
Example response:
"Light-dependent reactions and the Calvin cycle (also known
as the carbon fixation cycle) are interconnected processes
in photosynthesis. The light-dependent reactions, occurring
in the thylakoid membranes of chloroplasts, capture light
energy to produce ATP and NADPH. These energy-rich molecules
are then utilized by the Calvin cycle, which takes place in
the stroma of the chloroplast.
The Calvin cycle uses the ATP and NADPH from the light-dependent
reactions to power the fixation of carbon dioxide into organic
compounds, ultimately producing glucose. This interdependence is
crucial: the light-dependent reactions provide the necessary energy
and reducing power, while the Calvin cycle uses these products to
create the carbohydrates that plants need for growth and energy storage.
The chloroplast's structure facilitates this cooperation, with its
thylakoid membranes housing the light-dependent reactions and its
stroma providing the space for the Calvin cycle. This spatial organization
allows for efficient transfer of ATP and NADPH between the two
processes, highlighting the elegant design of photosynthesis in
utilizing light energy to produce organic compounds."
This is certainly a much more comprehensive response that meaningfully addressed how the two central processes queried work together, clearly explaining their interdependence and demonstrating a deeper understanding of the relationships between different concepts and processes surrounding photosynthesis.
Wrapping Up
To conclude, we summarize the main advantages of graph RAG:
- Contextual relevance: by identifying and leveraging relationships between documents or topics, gaining a more holistic view of the knowledge needed to provide a good response.
- Coherent response: guided by a logical information flow that captures connections in the knowledge graph as well as a structural understanding of interrelated entities.
- Detailed response: by retrieving deep yet relevant information upon traversing related nodes to the initially identified ones based on query similarity.
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.