
The evaluation of legal knowledge in large language models (LLMs) has primarily focused on English-language contexts, with benchmarks like MMLU and LegalBench providing foundational methodologies. However, the assessment of Arabic legal knowledge remained a significant gap. Previous efforts involved translating English legal datasets and utilizing limited Arabic legal documents, highlighting the need for dedicated Arabic legal AI resources.
ArabLegalEval emerges as a crucial benchmark to address these limitations. This new tool sources tasks from Saudi legal documents, providing a more relevant context for Arabic-speaking users. It aims to expand the evaluation criteria, incorporate a broader array of Arabic legal documents, and assess a wider range of models. ArabLegalEval represents a significant advancement in evaluating LLMs’ capabilities in Arabic legal contexts.
Rapid advancements in LLMs have improved various natural language processing tasks, but their evaluation in legal contexts, especially for non-English languages like Arabic, remains under-explored. ArabLegalEval addresses this gap by introducing a multitask benchmark dataset to assess LLMs’ proficiency in understanding and processing Arabic legal texts. Inspired by datasets like MMLU and LegalBench, it comprises tasks derived from Saudi legal documents and synthesized questions.
The complexity of Arabic legal language necessitates specialized benchmarks to accurately evaluate LLMs’ capabilities in this domain. While existing benchmarks like ArabicMMLU test general reasoning, ArabLegalEval focuses specifically on legal tasks developed in consultation with legal professionals. This benchmark aims to evaluate a wide range of LLMs, including proprietary multilingual and open-source Arabic-centric models, to identify strengths and weaknesses in their legal reasoning capabilities.
The methodology involves a systematic approach to create and validate a benchmark dataset for assessing Arabic legal knowledge in LLMs. Data preparation begins with sourcing legal documents from official entities and web scraping to capture relevant regulations. The process then focuses on generating synthetic multiple-choice questions (MCQs) using three methods: QA to MCQ, Chain of Thought, and Retrieval-based In-Context Learning. These techniques address the challenges of formulating questions and generating plausible answer options.
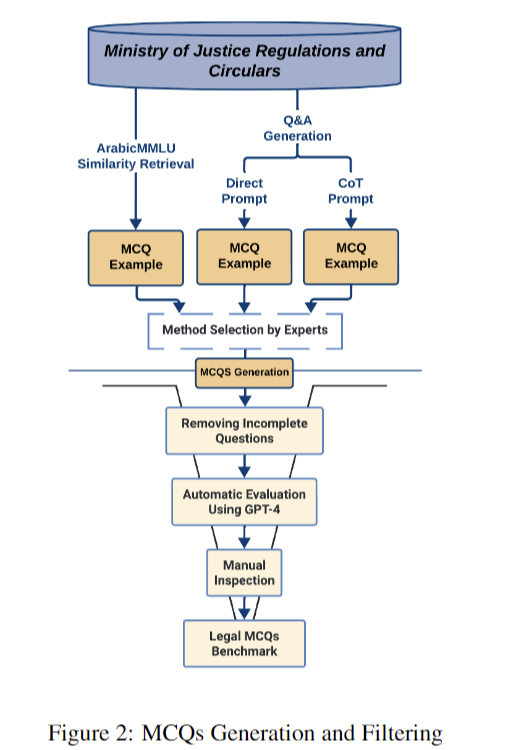
Following question generation, a rigorous filtering process employs cosine similarity to identify relevant text for each question, crucial for evaluating models’ reasoning capabilities. The final dataset, comprising 10,583 MCQs, undergoes manual inspection and expert validation to ensure quality. Evaluation metrics include Rouge metrics for translation quality and assessment of reasoning capabilities. This comprehensive methodology, involving collaboration with legal experts, aims to create a robust benchmark for evaluating Arabic legal knowledge in LLMs, addressing the unique challenges of legal language.
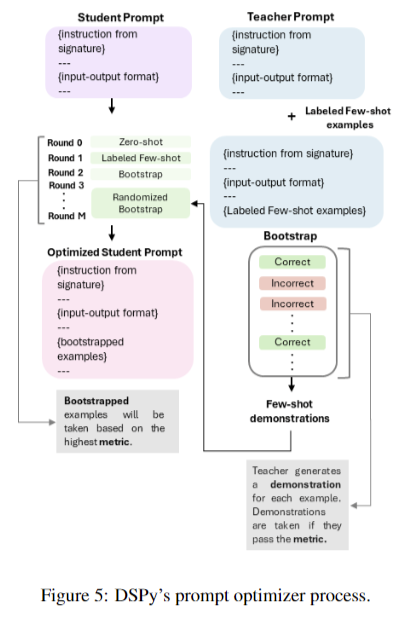
The ArabLegalEval benchmark reveals significant insights into LLMs’ performance on Arabic legal tasks. Human expert baselines provide crucial comparisons, while comprehensive analyses across various tasks highlight the effectiveness of optimized few-shot prompts and Chain of Thought reasoning. Smaller LMs demonstrate improved performance with self-cloned teacher models in few-shot scenarios. Traditional evaluation metrics show limitations in capturing semantic similarities, emphasizing the need for more nuanced assessment methods. Language considerations underscore the importance of matching response and reference languages. These findings highlight the critical role of prompt optimization, few-shot learning, and refined evaluation techniques in accurately assessing Arabic legal knowledge in LLMs.
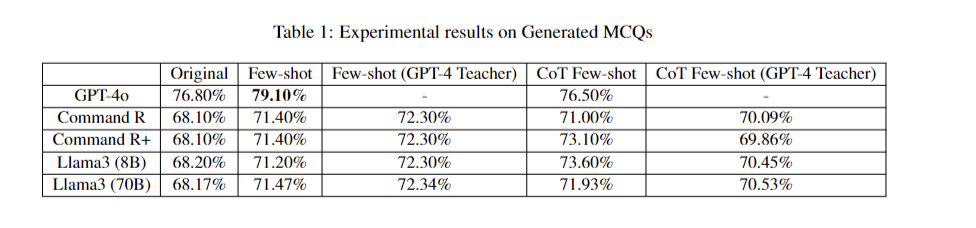
In conclusion, the researchers establish a specialized benchmark for evaluating LLMs’ Arabic legal reasoning capabilities, focusing on Saudi regulations and translated LegalBench problems. Future enhancements aim to incorporate additional Saudi legal documents, expanding the benchmark’s scope. Optimized few-shot prompts significantly improve LLM performance on MCQs, with specific examples heavily influencing outcomes. Chain-of-thought reasoning combined with few-shot examples enhances model capabilities, particularly for smaller LLMs using self-cloned teacher models. This research underscores the importance of robust evaluation frameworks for Arabic legal knowledge in LLMs and highlights the need for optimized training methodologies to advance model performance in this domain.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI
