
Custom Fine-Tuning for Domain-Specific LLMs.
Image by Author | Ideogram
Introduction to Custom LLM Fine-Tuning
Fine-tuning a large language model (LLM) is the process of taking a pre-trained model — usually a vast one like GPT or Llama models, with millions to billions of weights — and continuing to train it, exposing it to new data so that the model weights (or typically parts of them) get updated. This can be done for several reasons, such as keeping the LLM up-to-date with the newest data, or adjusting it to specialize in a narrower, more domain-specific task or application.
This article discusses and illustrates the latter reason for fine-tuning an LLM, demystifying custom LLM fine-tuning for making your model domain-specific.
It is important to clarify that by “custom fine-tuning” we do not refer to a particular or different method for fine-tuning an LLM. Generally speaking, the fine-tuning process is pretty much the same regardless of whether the purpose is adapting it to a specific domain or not: the key difference is the data used for training, which in the case of custom fine-tuning is data specifically curated so that its scope exclusively spans the target domain, style, or application needs. Custom fine-tuning with domain-specific datasets helps your model better understand specialized terminology and domain-related requirements and nuances.
The following image illustrates the very essence of custom LLM fine-tuning for domain-specific LLMs:
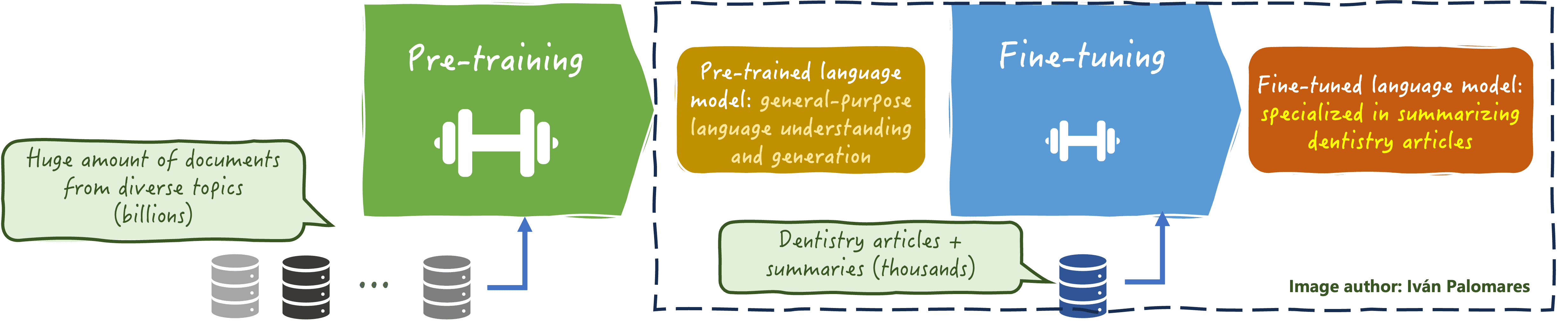
Custom LLM fine-tuning
Image by Author
Some important elements and aspects to have on the radar in custom LLM fine-tuning are:
- The data used to fine-tune your LLM must have high quality and be relevant, encompassing representative language patterns, terms, and expressions (jargon) that might be unique to your target domain, be it dentistry, principles of Zen Buddhism, or cryptocurrencies, to name some.
- Some domain-specific data requires deep factual knowledge for an LLM to effectively learn from it. A successful fine-tuning process should be able to distill this deep knowledge from the data and inject it into the “model’s DNA” to minimize the risks of generating imprecise information about the domain once fine-tuned.
- Compliance, liability, and licensing are also critical aspects to consider. Custom LLM fine-tuning processes should ensure the model’s alignment with ethical and industry standards and regulations to mitigate possible risks. Sometimes, models with less restrictive licenses, like Apache licenses, facilitate greater customization and control over your resulting fine-tuned model.
- Continuous monitoring and evaluation after fine-tuning are indispensable to ensure the fine-tuning process on domain-specific data went successfully and the renewed LLM is now more effective at the new scope it is intended for.
Illustrative Custom Fine-Tuning Example in Python
Let’s see a practical example of custom fine-tuning a relatively manageable LLM like falcon-rw-1b (about 1.3 billion parameters) available via Hugging Face’s Transformers library. The objective is not to take an exhaustive tour through the code, but rather to overview what are the main practical steps involved in custom LLM fine-tuning:
1. Setting Up and Getting Started
When working with Hugging Face models, fine-tuning typically requires identifying the type of LLM and target task it was pre-trained on (for instance, text generation), and loading the appropriate auto class for managing that type of model (in this example, AutoModelForCausalLM). The Trainer and TrainingArguments must also be imported, as they will play a fundamental role in fine-tuning the model.
And, of course, every loaded pre-trained model must come together with an associated tokenizer to manage data inputs appropriately.
|
pip install transformers datasets peft bitsandbytes accelerate |
|
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments from datasets import Dataset from peft import LoraConfig, get_peft_model
model_name = “tiiuae/falcon-rw-1b” tokenizer = AutoTokenizer.from_pretrained(model_name)
if tokenizer.pad_token is None: tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(model_name, load_in_8bit=True, device_map=“auto”) |
2. Getting and Preparing Domain-Specific Data
We are considering a tiny dataset — in a real fine-tuning process, it would be a much larger one — including question-answer pairs related to chronic diseases. This is perfectly fine for a text generation-focused LLM like the one we loaded, as one of the tasks it can seamlessly perform is generative question-answering (as opposed to extractive question-answering, in which the model attempts to extract the answer from an existing piece of information called context).
|
domain_data = [ “text”: “Q: What are the symptoms of diabetes? A: Increased thirst, frequent urination, fatigue.”, “text”: “Q: How is hypertension treated? A: Through lifestyle changes and medications.”, “text”: “Q: What causes anemia? A: Low levels of iron or vitamin B12 in the body.” ] dataset = Dataset.from_list(domain_data)
def tokenize_function(examples): return tokenizer(examples[“text”], padding=“max_length”, truncation=True)
tokenized_dataset = dataset.map(tokenize_function, batched=True) |
The dataset is tokenized before proceeding to fine-tune the model.
3. Fine-Tuning the Model
This process involves instantiating a TrainingArguments and Training instances, where we set configuration aspects like the number of training rounds and learning rate, calling the train() method, and saving the fine-tuned model. Optionally, techniques like LoRA (Low-Rank Adaptation) to make the fine-tuning process more lightweight by intelligently freezing significant parts of the model weights.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
lora_config = LoraConfig( r=8, lora_alpha=16, target_modules=[“query_key_value”], lora_dropout=0.05, bias=“none”, task_type=“CAUSAL_LM” ) model = get_peft_model(model, lora_config)
training_args = TrainingArguments( output_dir=“./results”, per_device_train_batch_size=2, num_train_epochs=2, logging_steps=10, save_steps=20, save_total_limit=2, optim=“paged_adamw_8bit”, learning_rate=2e–4, )
trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_dataset, )
trainer.train()
model.save_pretrained(“./custom-finetuned-llm”) tokenizer.save_pretrained(“./custom-finetuned-llm”) |
Wrapping Up
In this article, we provided a balanced overview — both theoretical and practical — of the process of custom fine-tuning large language models to adapt them to a more specific domain. This is a computationally intensive process that requires high-quality, representative data to be successful.