
Identifying gene deletion strategies for growth-coupled production in genome-scale metabolic models presents significant computational challenges. Growth-coupled production, which links cell growth to the synthesis of target metabolites, is essential for metabolic engineering applications. However, deriving gene deletion strategies for large-scale models places high computational demand since there is a massive search space combined with the need for repeated calculations across different target metabolites. These challenges limit methods’ scalability and efficiency and their application in industrial biotechnology and metabolic research.
Widely used approaches, such as the elementary flux vector-based method, gDel minRN, GDLS, and optGene, are effective but often computationally expensive. Most of these approaches do not share information between targets, because most of them depend on de novo calculations for every metabolite involved. The redundancy increases the computational cost, meaning that most of these approaches have low scalability. The success rate of the GDLS is very low, while for the required computation time to be applied at the genome-scale, it is too high for optGene.
To address this inefficiency, researchers from Kyoto University developed the DBgDel, a database-driven framework to compute strategies for gene deletion. This accommodates knowledge from the MetNetComp database in the computation. It works in two major steps. First, it fetches “remaining genes” derived from maximal deletion strategies archived in the database for the sake of having a focused initial gene pool, and then it applies an improved version of the gDel minRN algorithm for efficient computation of gene deletion strategies. It reduces redundant computation and speeds up the calculation by narrowing the space of search; hence, it offers a very scalable and practical solution for genome-scale metabolic engineering.
The research team used three metabolic models with varying levels of complexity- E. coli core, iMM904, and iML1515-using the MetNetComp database, which contains more than 85,000 deletion strategies for genes. This workflow generates a reduced set of remaining genes from database information and uses a MILP-based algorithm to refine deletion strategies. The performance was measured using a combination of success rates and computation time as compared to DBgDel against the existing tools, such as gDel minRN, GDLS, and optGene.
DBgDel demonstrated considerable performance improvements on the computational as well as retained good performance on all tested models. It demonstrated an average of 6.1 fold acceleration compared to the traditional approaches. It can identify deletion strategies for 507 out of 991 target metabolites of large-scale models, such as iML1515 in minimum computation time. The inclusion of the database-driven initial gene pools enabled better handling of scalability and precision by providing evidence for its effectiveness in genome-scale metabolic engineering applications.
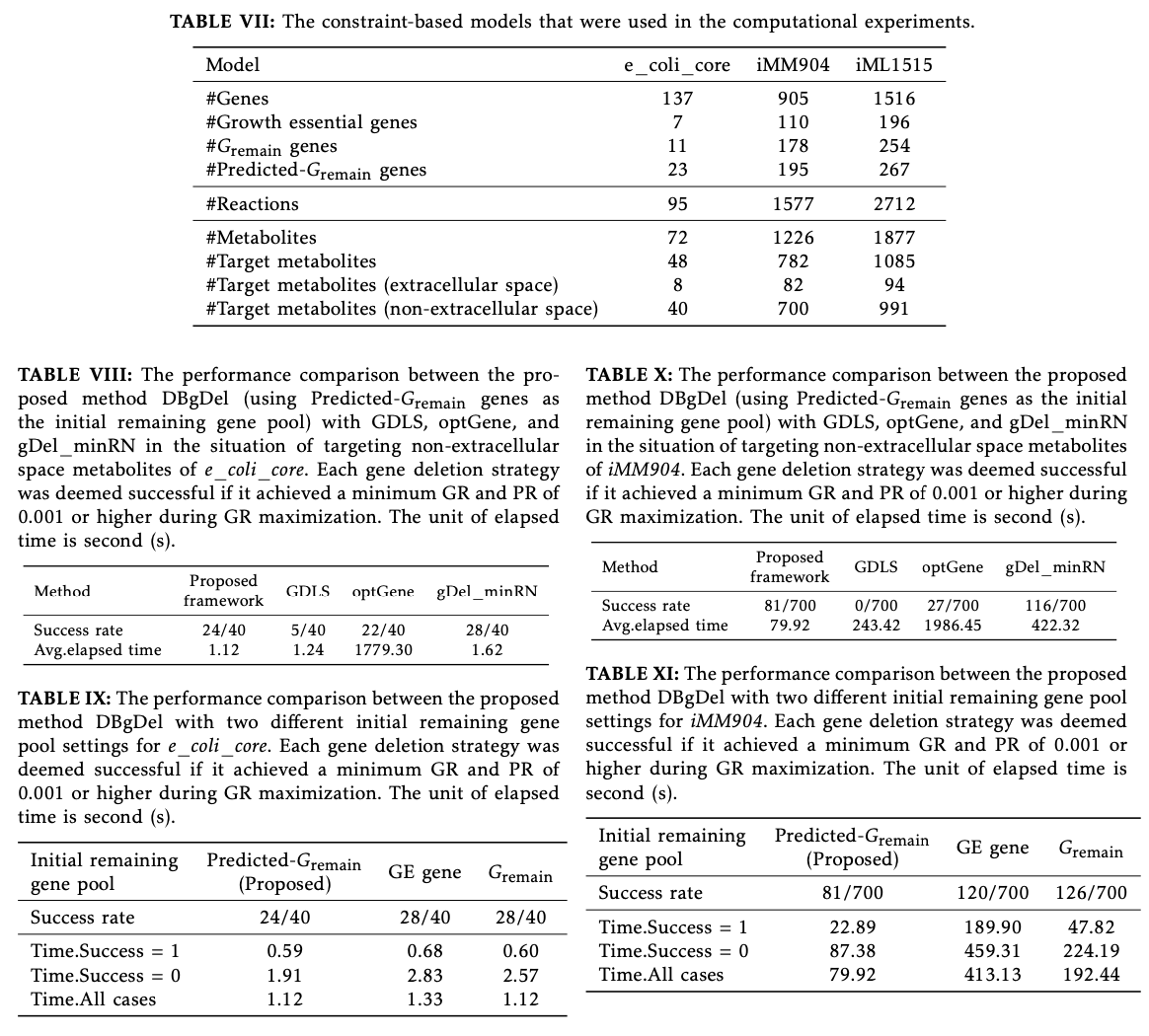
DBgDel offers a transformative solution for identifying gene deletion strategies in genome-scale metabolic models, addressing longstanding challenges in computational efficiency and scalability. The knowledge extracted from the databases results in faster, more accurate outputs with comparable success rates. This advance opens a wide avenue for more practical uses of genome-scale metabolic engineering in industrial biotechnology. To realize improvements in database extraction methods, these will need to be made more versatile to be expanded towards a more general application area.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.