

Image by Author
For many of us, exploring the possibilities of LLMs has felt out of reach. Whether it’s downloading complicated software, figuring out coding, or needing powerful machines – getting started with LLMs can seem daunting. But just imagine, if we could interact with these powerful language models as easily as starting any other program on our computers. No installation, no coding, just click and talk. This accessibility is key for both developers and end-users. llamaFile emerges as a novel solution, merging the llama.cpp with Cosmopolitan Libc into a single framework. This framework reduces the complexity of LLMs by offering a one-file executable called “llama file”, which runs on local machines without the need for installation.
So, how does it work? llamaFile offers two convenient methods for running LLMs:
- The first method involves downloading the latest release of llamafile along with the corresponding model weights from Hugging Face. Once you have those files, you’re good to go!
- The second method is even simpler – you can access pre-existing example llamafiles that have weights built-in.
In this tutorial, you will work with the llamafile of the LLaVa model using the second method. It’s a 7 Billion Parameter model that is quantized to 4 bits that you can interact with via chat, upload images, and ask questions. The example llamafiles of other models are also available, but we will be working with the LLaVa model as its llamafile size is 3.97 GB, while Windows has a maximum executable file size of 4 GB. The process is simple enough, and you can run LLMs by following the steps mentioned below.
First, you need to download the llava-v1.5-7b-q4.llamafile (3.97 GB) executable from the source provided here.
Open your computer’s terminal and navigate to the directory where the file is located. Then run the following command to grant permission for your computer to execute this file.
chmod +x llava-v1.5-7b-q4.llamafile
If you are on Windows, add “.exe” to the llamafile’s name on the end. You can run the following command on the terminal for this purpose.
rename llava-v1.5-7b-q4.llamafile llava-v1.5-7b-q4.llamafile.exe
Execute the llama file by the following command.
./llava-v1.5-7b-q4.llamafile -ngl 9999
⚠️ Since MacOS uses zsh as its default shell and if you run across zsh: exec format error: ./llava-v1.5-7b-q4.llamafile error then you need to execute this:
bash -c ./llava-v1.5-7b-q4.llamafile -ngl 9999
For Windows, your command may look like this:
llava-v1.5-7b-q4.llamafile.exe -ngl 9999
After running the llamafile, it should automatically open your default browser and display the user interface as shown below. If it doesn’t, open the browser and navigate to http://localhost:8080 manually.
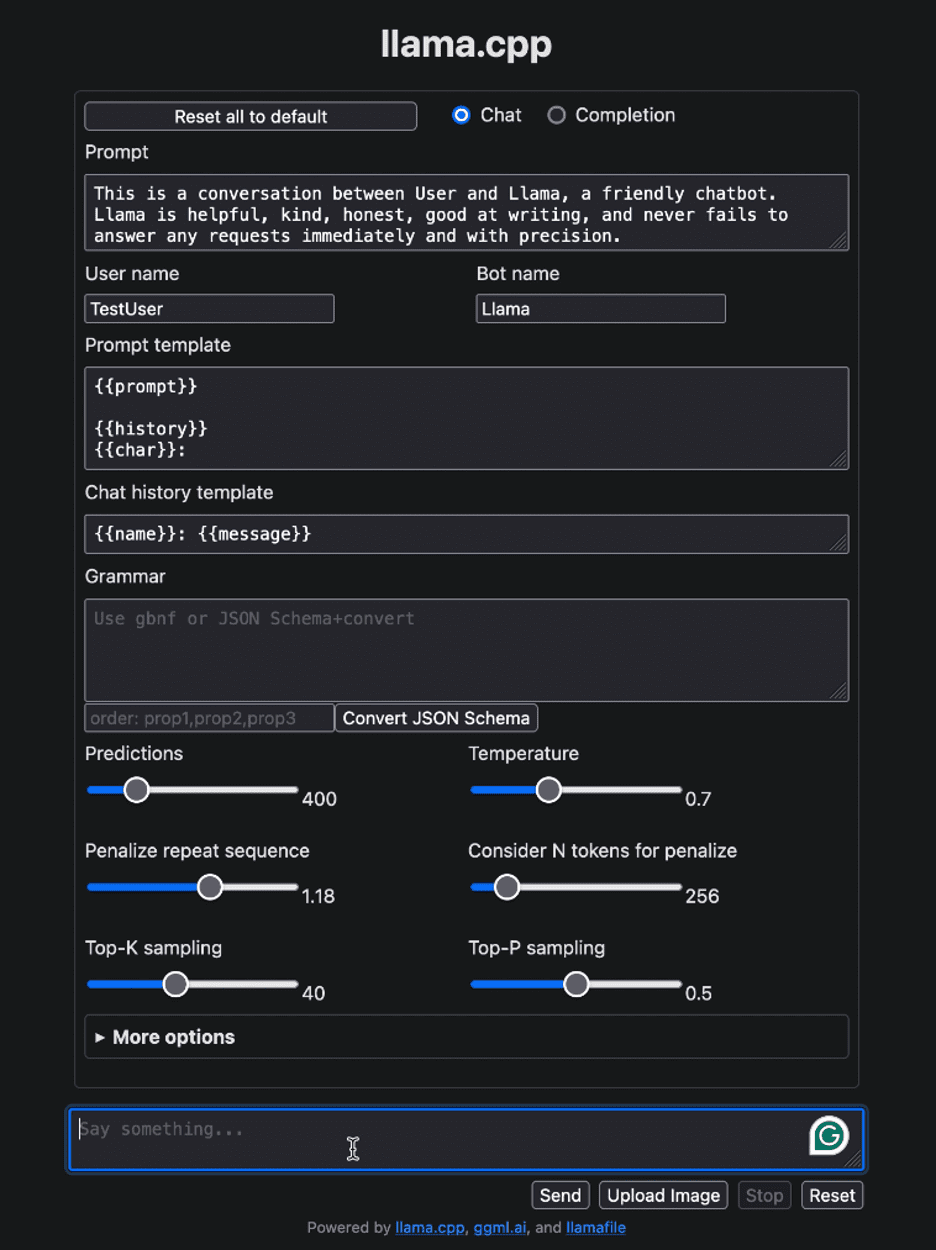
Image by Author
Let’s start by interacting with the interface with a simple question to provide some information related to the LLaVa model. Below is the response generated by the model:
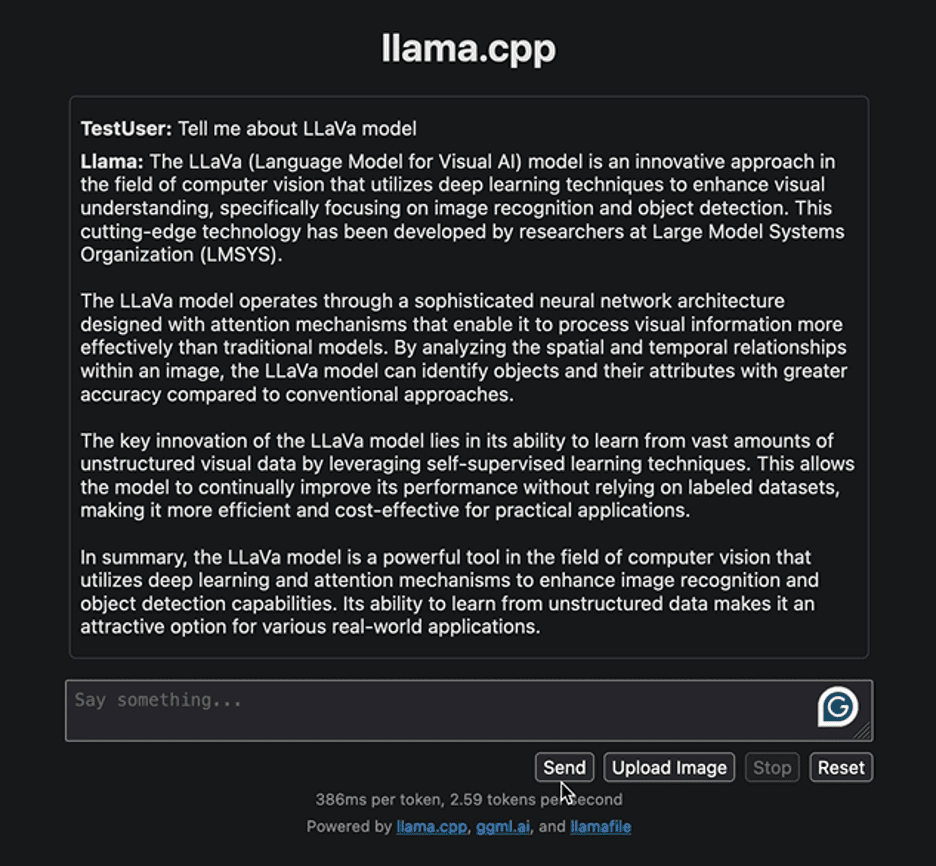
Image by Author
The response highlights the approach to developing the LLaVa model and its applications. The response generated was reasonably fast. Let’s try to implement another task. We will upload the following sample image of a bank card with details on it and extract the required information from it.

Image by Ruby Thompson
Here’s the response:

Image by Author
Again, the response is pretty reasonable. The authors of LLaVa claim that it attains top-tier performance across various tasks. Feel free to explore diverse tasks, observe their successes and limitations, and experience the outstanding performance of LLaVa yourself.
Once your interaction with the LLM is complete, you can shut down the llama file by returning to the terminal and pressing “Control – C”.
Distributing and running LLMs has never been more straightforward. In this tutorial, we explained how easily you can run and experiment with different models with just a single executable llamafile. This not only saves time and resources but also expands the accessibility and real-world utility of LLMs. We hope you found this tutorial helpful and would love to hear your thoughts on it. Additionally, if you have any questions or feedback, please don’t hesitate to reach out to us. We’re always happy to help and value your input.
Thank you for reading!
Kanwal Mehreen Kanwal is a machine learning engineer and a technical writer with a profound passion for data science and the intersection of AI with medicine. She co-authored the ebook “Maximizing Productivity with ChatGPT”. As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She’s also recognized as a Teradata Diversity in Tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having founded FEMCodes to empower women in STEM fields.