
Large language models (LLMs) have significantly advanced various natural language processing tasks, but they still face substantial challenges in complex mathematical reasoning. The primary problem researchers are trying to solve is how to enable open-source LLMs to effectively handle complex mathematical tasks. Current methodologies struggle with task decomposition for complex problems and fail to provide LLMs with sufficient feedback from tools to support comprehensive analysis. While existing approaches have shown promise in simpler math problems, they fall short when confronted with more advanced mathematical reasoning challenges, highlighting the need for a more sophisticated approach.
Existing attempts to enhance mathematical reasoning in LLMs have evolved from basic computational expressions to more sophisticated approaches. Chain-of-Thought (COT) and Program-of-Thought (POT) methods introduced intermediate steps and code tools to improve problem-solving capabilities. Collaborative paradigms combining COT and coding have shown significant accuracy improvements. Data augmentation techniques have also been explored, with researchers curating diverse mathematical datasets and generating synthetic question-answer pairs using advanced LLMs to create Supervised Fine-Tuning (SFT) datasets. However, these methods still face limitations in handling complex mathematical tasks and providing comprehensive analysis, indicating the need for a more advanced approach that can effectively decompose problems and utilize feedback from tools.
Researchers from the University of Science and Technology of China and Alibaba Group present DotaMath, an efficient approach to enhance LLMs’ mathematical reasoning capabilities, addressing the challenges of complex mathematical tasks through three key innovations. First, it employs a decomposition of thought strategy, breaking down complex problems into more manageable subtasks that can be solved using code assistance. Second, it implements an intermediate process display, allowing the model to receive more detailed feedback from code interpreters, enabling comprehensive analysis and improving the human readability of responses. Lastly, DotaMath incorporates a self-correction mechanism, allowing the model to reflect on and rectify its solutions when initial attempts fail. These design elements collectively aim to overcome existing methods’ limitations and significantly improve LLMs’ performance on complex mathematical reasoning tasks.
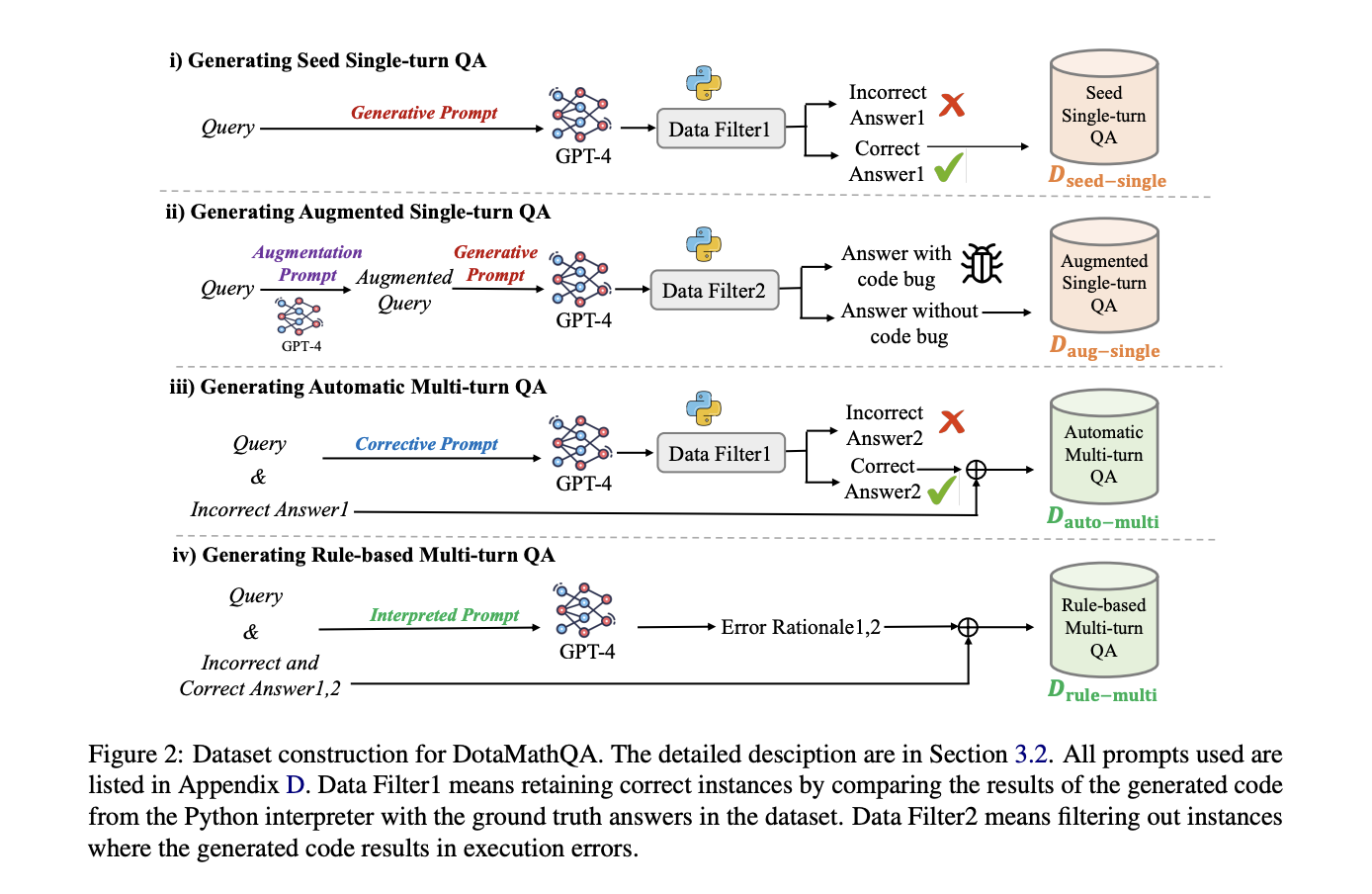
DotaMath enhances LLMs’ mathematical reasoning through three key innovations: decomposition of thought, intermediate process display, and self-correction. The model breaks complex problems into subtasks, uses code to solve them, and provides detailed feedback from code interpreters. The DotaMathQA dataset, constructed using GPT-4, includes single-turn and multi-turn QA data from existing datasets and augmented queries. This dataset enables the model to learn task decomposition, code generation, and error correction. Various base models are fine-tuned on DotaMathQA, optimizing for the log-likelihood of reasoning trajectories. This approach allows DotaMath to handle complex mathematical tasks more effectively than previous methods, addressing limitations in existing LLMs’ mathematical reasoning capabilities.
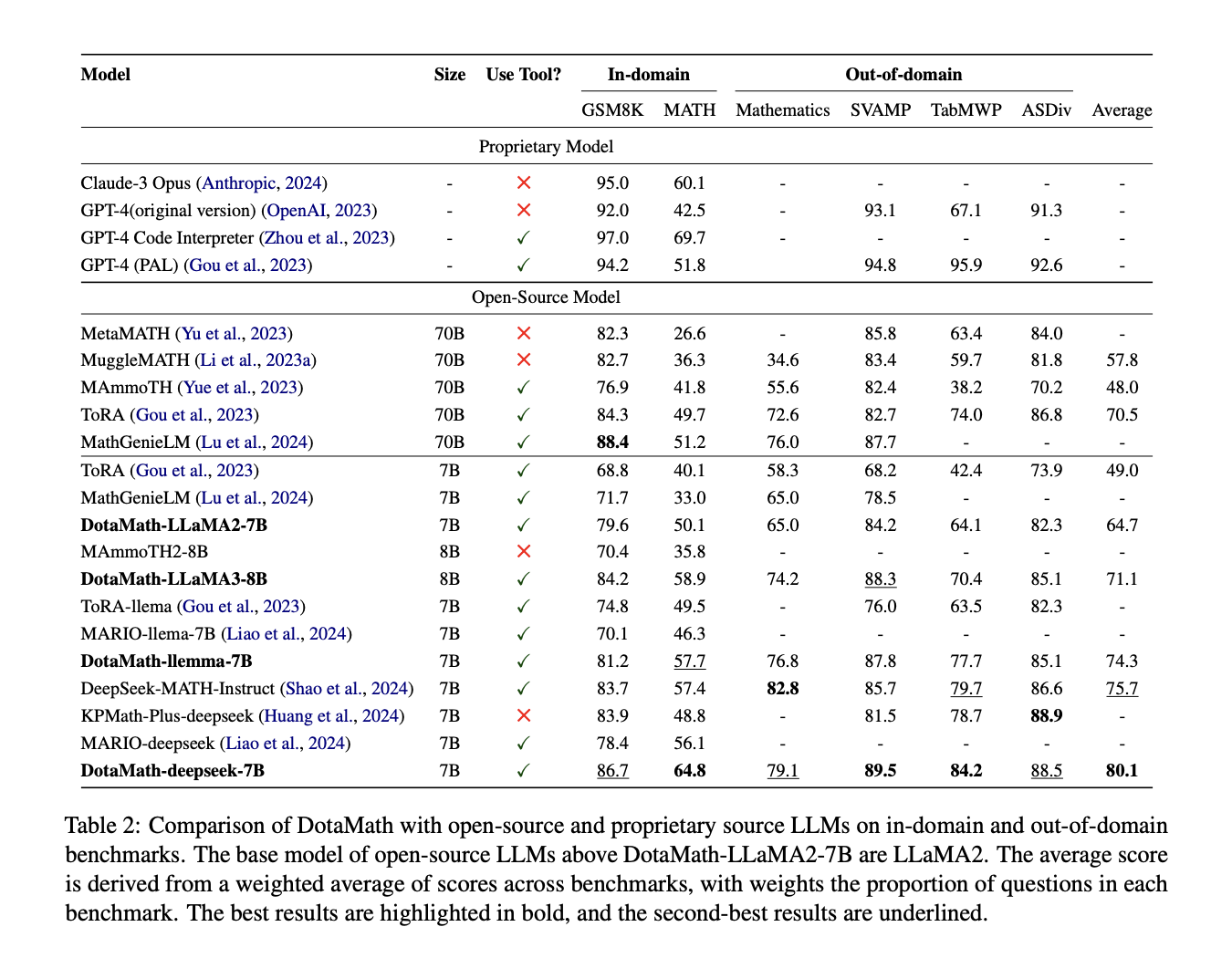
DotaMath demonstrates exceptional performance across various mathematical reasoning benchmarks. Its 7B model outperforms most 70B open-source models on elementary tasks like GSM8K. For complex tasks such as MATH, DotaMath surpasses both open-source and proprietary models, highlighting the effectiveness of its tool-based approach. The model shows strong generalization capabilities on untrained out-of-domain datasets. Different DotaMath variations exhibit incremental improvements, likely due to pre-training data differences. Overall, DotaMath’s performance across diverse benchmarks underscores its comprehensive mathematical reasoning abilities and the effectiveness of its innovative approach, combining task decomposition, code assistance, and self-correction mechanisms.
DotaMath represents a significant advancement in mathematical reasoning for LLMs, introducing innovative techniques like thought decomposition, code assistance, and self-correction. Trained on the extensive DotaMathQA dataset, it achieves outstanding performance across various mathematical benchmarks, particularly excelling in complex tasks. The model’s success validates its approach to tackling difficult problems and demonstrates enhanced program simulation abilities. By pushing the boundaries of open-source LLMs’ mathematical capabilities, DotaMath not only sets a new standard for performance but also opens up exciting avenues for future research in AI-driven mathematical reasoning and problem-solving.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.