
Small language models (SLMs) are compact versions of large language models (LLMs). They typically contain fewer parameters than their large siblings: around 3 billion or less. This makes them comparatively lightweight and faster in inference time.
An interesting subject of research into SLMs is their integration into retrieval augmented generation (RAG) systems to enhance their performance. This article explores this recent trend, outlining the benefits and limitations of integrating SLMs in RAG systems.
A Brief Portrait of SLMs
To better characterize SLMs, it is important to pinpoint their differences with LLMs.
- Size and complexity: While LLMs can have up to trillions of parameters, SLMs are significantly smaller, often having a few million to a few billion parameters. Well … that’s still pretty huge, but everything in life is relative, especially when compared to LLMs.
- Required resources: In line with the decreased size, SLMs’ computational resources for training and inference are not as substantial as those in LLMs. This higher resource efficiency is one of the main advantages of SLMs.
- Model performance: On the other side of the coin, LLMs tend to perform better in terms of accuracy and are capable of coping with more complex tasks than SLMs, due to their significant training process and large number of parameters: they are just like a bigger brain! Meanwhile, SLMs may have limitations in understanding and generating text with intricate patterns.
Besides resource and cost-efficiency, other pros of SLM include a higher flexibility for being deployed, due to being lightweight models (again, take the term lightweight “with a pinch of salt”, in relative terms). Another advantage is their faster fine-tuning of domain-specific datasets.
Regarding the cons of SLMs, besides being more limited for very challenging language tasks, they are less generalizable and struggle more to handle language outside the domain data they have been trained on.
SLMs Integration with RAG Systems
Integration of SLMs in RAG systems can be done with several aims, such as improving system performance in domain-specific applications. As outlined above, fine-tuning an SLMs on specialized datasets is significantly less costly than fine-tuning an LLM on the same datasets, and a fine-tuned model in an RAG system can provide more accurate and contextually relevant responses than, say, a foundation model trained on general-purpose text. In sum, SLM-RAG integration ensures that the generated content by a fine-tuned generator (the SLM) aligns closely with the retrieved information, enhancing the overall system accuracy.
Let’s recall at this point what a basic RAG architecture looks like (our discussion in this article involves replacing the ‘LLM’ inside the generator with an ‘SLM’):
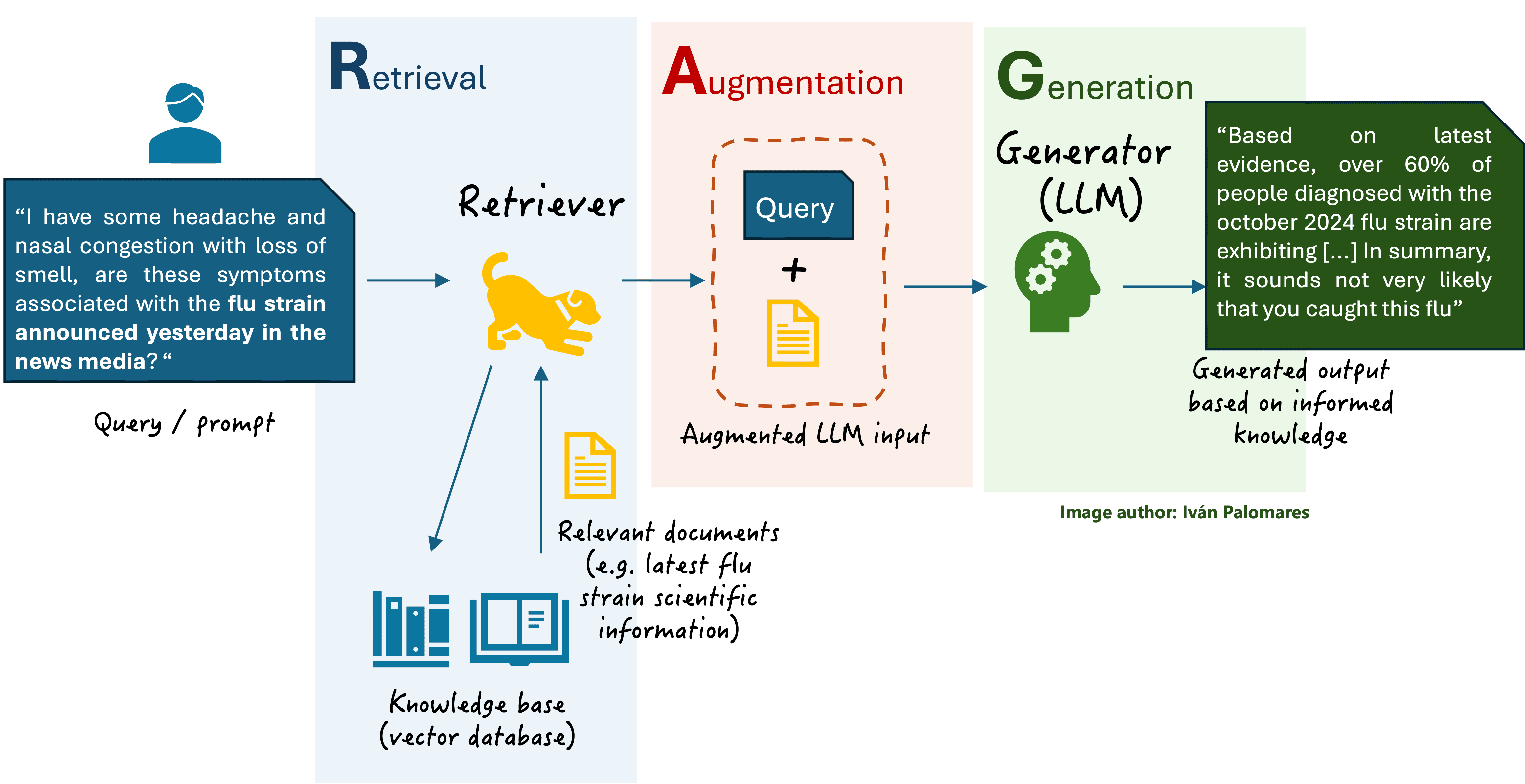 RAG architecture
RAG architectureThe role discussed above for SLMs in RAG systems is essentially becoming the system’s generator. However, there are more approaches to integrating SLMs in a RAG system. One is by becoming an additional retriever component to enhance its performance, by ranking or re-ranking retrieved documents based on query relevance, which ensures higher-quality input to the generator, which may in turn be another SLM or an LLM. SLMs may also be used in RAG systems to pre-process or filter the retrieved context and ensure only the most relevant or high-quality information is passed to the generator: this approach is called pre-generation filtering or augmentation. Finally, there are hybrid RAG architectures where both an LLM and an SLM can coexist as generators: via a query routing mechanism, there is an SLM that handles straightforward or domain-specific queries and an LLM that handles complex, general-purpose tasks requiring more contextual understanding.
Using SLMs in RAG is not the go-to approach in every situation, and some challenges and limitations of this binomial are:
- Data scarcity: high-quality, domain-specific datasets are crucial for training SLMs and are not always easy to find. Failing to count on sufficient data may lead to suboptimal model performance.
- Vocabulary limitations: fine-tuned SLMs lack comprehensive vocabularies, which impacts their ability to understand and generate diverse responses with different linguistic patterns.
- Deployment constraints: even though the lightweight nature of SLMs makes them suitable for edge devices, it remains the challenge to ensure compatibility and optimal performance across various hardware.
This leads us to conclude that SLMs are not universally better than LLMs for every RAG application. Choosing between SLMs and LLMs for your RAG system should depend on several criteria: SLMs are better in systems that focus on domain-specific tasks, under resource-constrained scenarios, and where data privacy is crucial, making them easier to use for inference outside of the cloud than LLMs. On the contrary, LLMs are the go-to approach for general-purpose RAG applications, when complex query understanding is vital, and when longer context windows (larger amounts of text information) need to be retrieved and processed.
Wrapping Up
SLMs provide a cost-effective and flexible alternative to LLMs, particularly for easing the development of domain-specific RAG applications. By discussing the advantages and limitations of leveraging SLMs in RAG systems, this article provided a view on the role of smaller language models in these innovative retrieval-generation solutions that are an active subject of AI research nowadays.
A couple of success stories related to this integration of SLMs can be read in these articles:
- Artificial intelligence companies seek big profits from ‘small’ language models
- These AI Models Are Pretty Mid. That’s Why Companies Love Them
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.