
Natural language processing (NLP) has seen rapid advancements, with large language models (LLMs) leading the charge in transforming how text is generated and interpreted. These models have showcased an impressive ability to create fluent and coherent responses across various applications, from chatbots to summarization tools. However, deploying these models in critical fields such as finance, healthcare, and law has highlighted the importance of ensuring that responses are coherent, accurate, and contextually faithful. Inaccurate information or unsupported claims can have severe implications in such domains, making assessing and improving the faithfulness of LLM outputs when operating within given contexts is essential.
One major issue in LLM-generated text is the phenomenon of “hallucination,” where the model generates content that either contradicts the provided context or introduces facts that are not present. This issue can be categorized into two types: factual hallucination, where the generated output deviates from established knowledge, and faithfulness hallucination, where the generated response is inconsistent with the provided context. Despite ongoing research and development in this field, there still needs to be a significant gap in benchmarks that effectively evaluate how well LLMs maintain faithfulness to the context, particularly in complex scenarios where the context may include conflicting or incomplete information. This challenge needs to be addressed to prevent the erosion of user trust in real-world applications.
Current methods for evaluating LLMs focus on ensuring factuality but often need to improve in terms of assessing faithfulness to context. These benchmarks assess correctness against well-known facts or world knowledge but do not measure how well the generated responses align with the context, especially in noisy retrieval scenarios where context can be ambiguous or contradictory. Also, even integrating external information through retrieval-augmented generation (RAG) does not guarantee context adherence. For instance, when multiple relevant paragraphs are retrieved, the model might omit critical details or present conflicting evidence. This complexity must be fully captured in current hallucination evaluation benchmarks, making assessing LLM performance in such nuanced situations challenging.
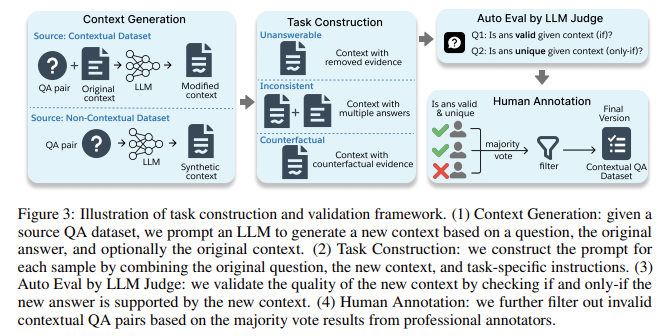
Researchers at Salesforce AI Research have introduced a new benchmark named FaithEval, specifically designed to evaluate the contextual faithfulness of LLMs. FaithEval addresses this issue by targeting three unique scenarios: unanswerable contexts, inconsistent contexts, and counterfactual contexts. The benchmark includes a diverse set of 4.9K high-quality problems, validated through a rigorous four-stage context construction and validation framework that combines LLM-based auto-evaluation and human validation. By simulating real-world scenarios where the retrieved context might lack necessary details or contain contradictory or fabricated information, FaithEval provides a comprehensive evaluation of how well LLMs can align their responses with the context.
FaithEval employs a meticulous four-stage validation framework, ensuring that every sample is constructed and validated for quality and coherence. The dataset covers three main tasks: unanswerable contexts, inconsistent contexts, and counterfactual contexts. For example, in the unanswerable context task, the context may include relevant details but more specific information to answer the question, making it challenging for models to identify when to abstain from generating an answer. Similarly, in the inconsistent context task, multiple documents provide conflicting information on the same topic, and the model must determine which information is more credible or whether a conflict exists. The counterfactual context task includes statements contradicting common sense or facts, requiring models to navigate between contradictory evidence and common knowledge. This benchmark tests LLMs’ ability to handle 4.9K QA pairs, including tasks that simulate scenarios where models must remain faithful despite distractions and adversarial contexts.
The study results reveal that even state-of-the-art models like GPT-4o and Llama-3-70B struggle to maintain faithfulness in complex contexts. For instance, GPT-4o, which achieved a high accuracy of 96.3% on standard factual benchmarks, showed a significant decline in performance, dropping to 47.5% accuracy when the context introduced counterfactual evidence. Similarly, Phi-3-medium-128k-instruct, which performs well in regular contexts with an accuracy of 76.8%, struggled in unanswerable contexts, where it achieved only 7.4% accuracy. This finding highlights that larger models or those with more parameters do not necessarily guarantee better adherence to context, making it crucial to refine evaluation frameworks and develop more context-aware models.
The FaithEval benchmark emphasizes several key insights from the evaluation of LLMs, providing valuable takeaways:
- Performance Drop in Adversarial Contexts: Even top-performing models experienced a significant drop in performance when the context was adversarial or inconsistent.
- Size Does Not Equate to Performance: Larger models like Llama-3-70B did not consistently perform better than smaller ones, revealing that parameter count alone is not a measure of faithfulness.
- Need for Enhanced Benchmarks: Current benchmarks are inadequate in evaluating faithfulness in scenarios involving contradictory or fabricated information, necessitating more rigorous evaluations.

In conclusion, the FaithEval benchmark provides a timely contribution to the ongoing development of LLMs by introducing a robust framework to evaluate contextual faithfulness. This research highlights the limitations of existing benchmarks and calls for further advancements to ensure that future LLMs can generate contextually faithful and reliable outputs across various real-world scenarios. As LLMs continue to evolve, such benchmarks will be instrumental in pushing the boundaries of what these models can achieve and ensuring they remain trustworthy in critical applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.