
Image by Author
We have all learned to fine-tune LLMs (Large Language Models) using the Hugging Face ecosystem, but what if I told you there is a better Python framework? Introducing Unsloth, a new player in the market that fine-tunes LLMs with lower GPU memory usage, provides faster inference and training, and easy model merging and saving options. You can use Unsloth to fine-tune LLMs on your laptop with an older GPU and achieve results similar to ChatGPT. It is fast and integrates seamlessly with various tools.
In this tutorial, we will use a Kaggle notebook to fine-tune a 4-bit Llama 3.2 model on a mental health conversation dataset. Afterward, we will merge the LoRA with the base model and convert it into the GGUF format for local use with chat applications like Jan and GPT4ALL.
Our Top 3 Partner Recommendations
![]()
![]() 1. Best VPN for Engineers – 3 Months Free – Stay secure online with a free trial
1. Best VPN for Engineers – 3 Months Free – Stay secure online with a free trial
![]()
![]() 2. Best Project Management Tool for Tech Teams – Boost team efficiency today
2. Best Project Management Tool for Tech Teams – Boost team efficiency today
![]()
![]() 4. Best Password Management for Tech Teams – zero-trust and zero-knowledge security
4. Best Password Management for Tech Teams – zero-trust and zero-knowledge security
Setting Up
Install the Unsloth Python package using the PIP command.
%%capture
%pip install unsloth
Set up Hugging face Token as an environment variable in Kaggle using the Secrets.
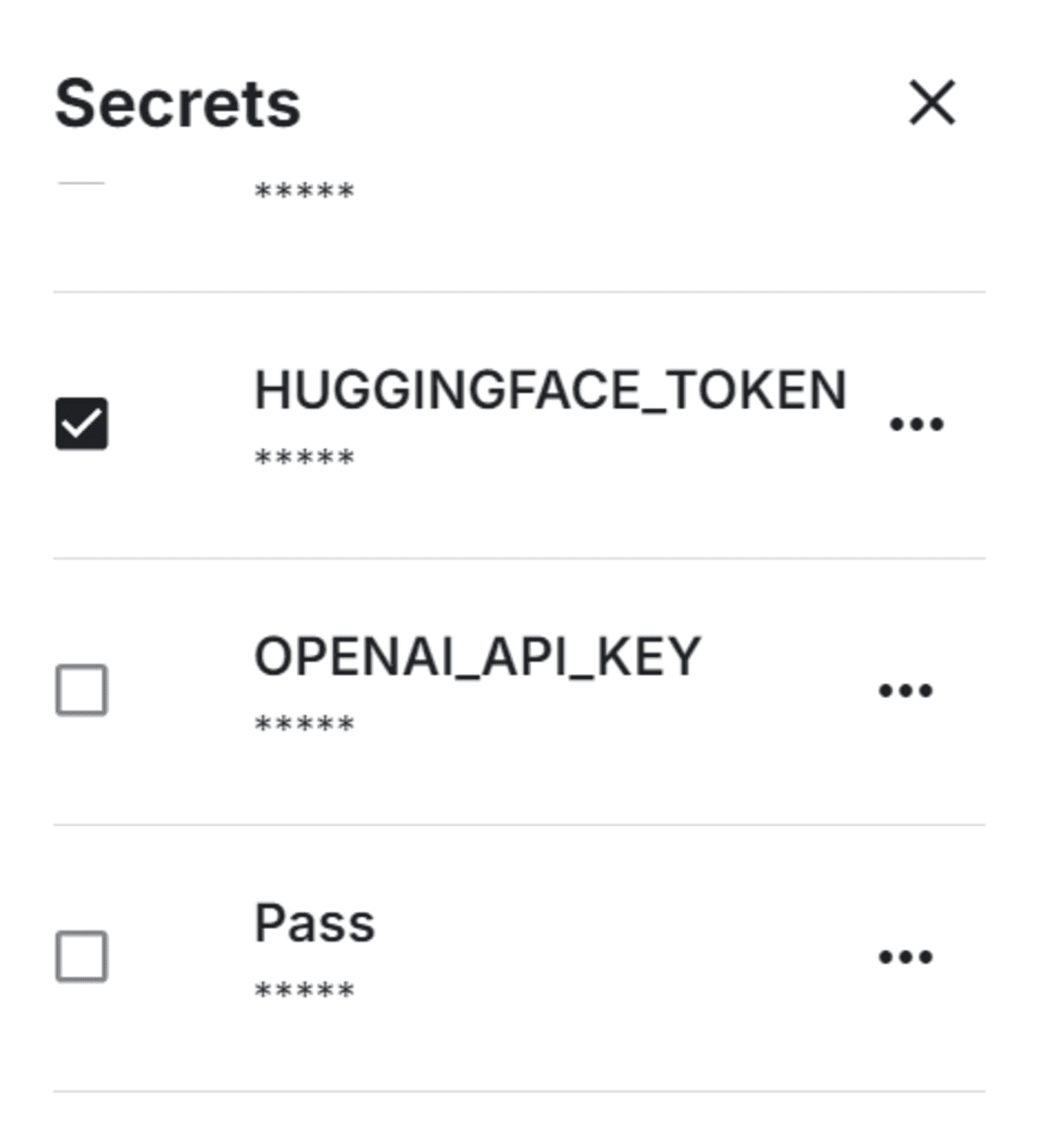
Securely load the Hugging Face token and use it to log in to the Hugging Face CLI.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)
Loading the Model and Tokenizer
Load tokenizer and the Llama-3.2-3B-Instruct model in 4-bit quantization with one line of code.
from unsloth import FastLanguageModel
import torch
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Llama-3.2-3B-Instruct",
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)

Loading and Processing the Dataset
Add the NLP Mental Health Conversations dataset into your Kaggle notebook.

Load the CSV file and view the first sample.
from datasets import load_dataset
#Importing the dataset
dataset = load_dataset('csv', data_files="/kaggle/input/nlp-mental-health-conversations/train.csv")
dataset["train"][0]
We have two columns: Context and Response. We will use them to create the text column in the next part.

To create the ‘text’ column, which will be used to find the model, we have to create the chat template. The template contains system prompt, patien query, and doctor response.
instruction = """You are an experienced psychologist named Amelia.
Be polite to the patient and answer all mental health-related queries.
"""
def format_chat_template(row):
row_json = ["role": "system", "content": instruction ,
"role": "user", "content": row["Context"],
"role": "assistant", "content": row["Response"]]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset["train"].map(
format_chat_template,
num_proc= 4,
)
dataset["text"][2]
We have successfully created the ‘text’ column with the instruction, user query, and assistant response.

Split the dataset into train and validation dataset.
dataset = dataset.train_test_split(test_size=0.1)
Setting Up the Model
Add the adopter to that model by providing it with the target model names and other hyperparameters.
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
Initiate the trainer, which includes all of the hyperparameters used to fine-tune the model.
from trl import SFTTrainer
from transformers import TrainingArguments, DataCollatorForSeq2Seq
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
dataset_text_field = "text",
max_seq_length = 2048,
data_collator = DataCollatorForSeq2Seq(tokenizer = tokenizer),
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
eval_strategy="steps",
eval_steps=0.2,
warmup_steps = 5,
# num_train_epochs = 1, # Set this for 1 full training run.
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "model_traning_outputs",
report_to = "none",
),
)
Model Training
The function `train_on_responses_only` configures the trainer to focus on training the model using only the response parts of the data, which is useful for tasks like dialogue generation, where the model needs to learn how to respond appropriately to given prompts.
from unsloth.chat_templates import train_on_responses_only
trainer = train_on_responses_only(
trainer,
instruction_part = "<|start_header_id|>user<|end_header_id|>\n\n",
response_part = "<|start_header_id|>assistant<|end_header_id|>\n\n",
)
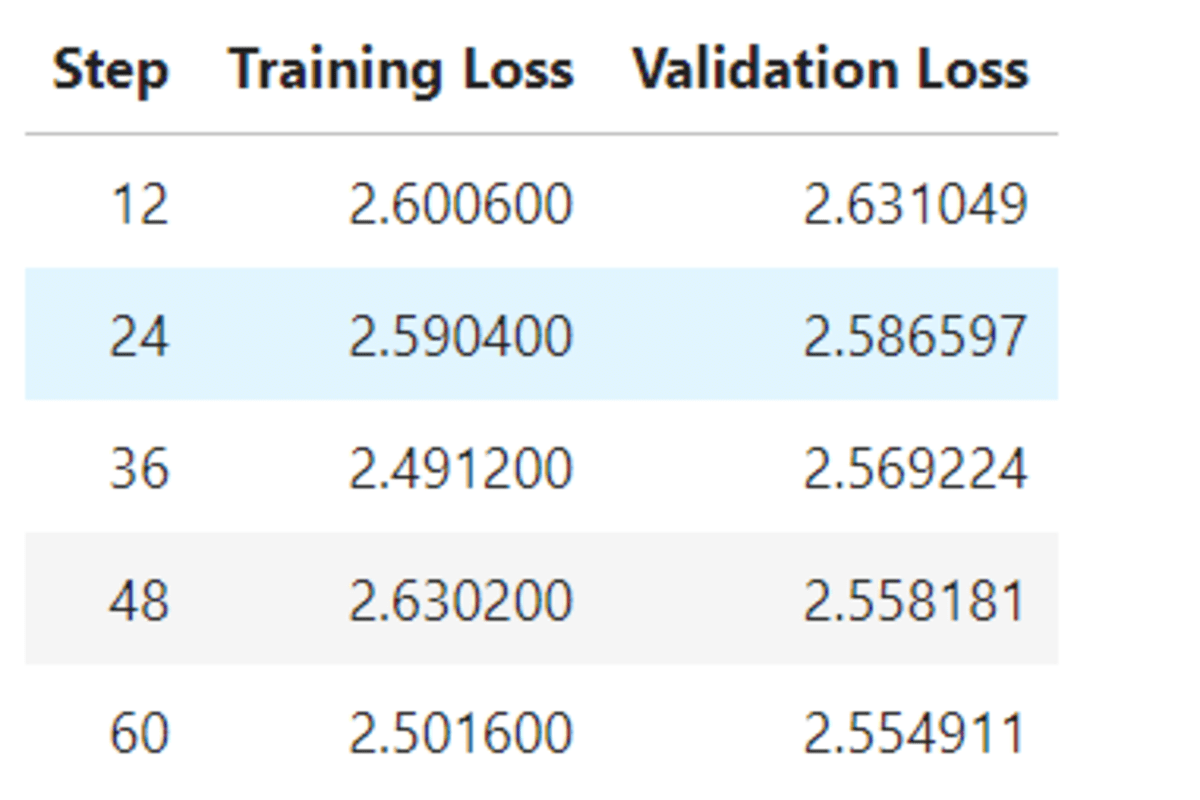
trainer_stats = trainer.train()
The training and validation losses gradually reduce. It is highly recommended that the model be trained on 3 epochs and at least 400 steps.
Accessing the Fine-tuned Model
The model should be trained for a minimum of 3 epochs and at least 400 steps, during which the training and validation losses should gradually decrease.
FastLanguageModel.for_inference(model)
messages = ["role": "system", "content": instruction,
"role": "user", "content": "I don't have the will to live anymore. I don't feel happiness in anything. "]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=150, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])
The response is quite similar to the dataset. We have successfully fine-tuned the model.

Saving the Tokenizer and Model
We will now save the LoRA and tokenizer locally.
new_model = "Llama-3.2-3b-it-mental-health"
model.save_pretrained(new_model)
tokenizer.save_pretrained(new_model)
We can also push the LoRa and tokenizer to the Hugging Face Hub. It will create the new model repository using the new model name.
model.push_to_hub(new_model)
tokenizer.push_to_hub(new_model)

Image from kingabzpro/Llama-3.2-3b-it-mental-health
Merging and Exporting Fine-tuned Llama 3.2
This one line of code is powerful. It will first load the full base model and then merge the fine-tuned LoRA with the base model. After that, the full model will be converted to the GGUF format and then quantized using the “q4_k_m” method. In the end, it will push the full GGUF and quantized model to the Hugging Face repository.
%%capture
model.push_to_hub_gguf(new_model, tokenizer, quantization_method = "q4_k_m")
As we can see, both full model and qunatize model have been pushed to the repository.
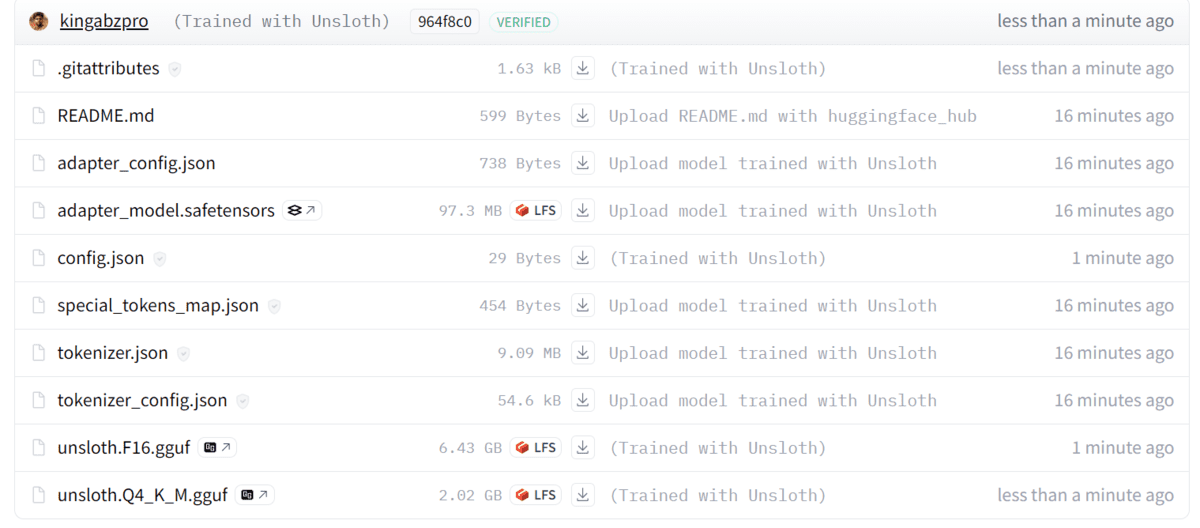
Image from kingabzpro/Llama-3.2-3b-it-mental-health
If you are facing issues running the above code, please refer to the Fine-tuning Llama 3.2 on Mental Health Dataset kaggle notebook for self-assistance.
Conclusion
I believe Unsloth is definitely user-friendly, and you will rarely encounter issues while using it. In this tutorial, we have learned how to load the dataset, preprocess it, build the model, train the model on the processed dataset, access the fine-tuned model, save the LoRA, merge the LoRA with the base model, and then convert it into the GGUF format so that we can use it later on our laptop using our favorite desktop chatbot application.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in technology management and a bachelor’s degree in telecommunication engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.