
Image by Editor | Midjourney & Canva
Introduction
Generative AI is everywhere; however, a common criticism is that LLMs sometimes fail to accurately respond to user inputs, a phenomenon known as hallucination. This is where Retrieval augmented generation (RAG) can be helpful.
RAG has become the universally go-to technique for improving LLM model outputs. It enhances output by integrating external knowledge that the model might not have in its training data. RAG is handy in use cases requiring specific domain knowledge and data privacy.
To learn more about RAG, let’s implement a RAG recipe, one that you can implement on your local computer. During this exercise, you will learn how to implement RAG systems in a way you can later adapt and use in your own projects and even in production.
Our RAG Recipe
There are many ways to implement a RAG system; from scratch vs. with a framework; local vs. hosted LLM; hosted vector database vs. local implementation. You can use any of the common RAG approaches that suit your needs, so long as is the result is stable, sufficiently accurate, and does not cause high technical debts.
For our implementation, we will use a standard RAG setup with query enhancement in order to improve results. We will implement our system using a local vector database along with a hosted language model. Our recipe can be seen in the image below.
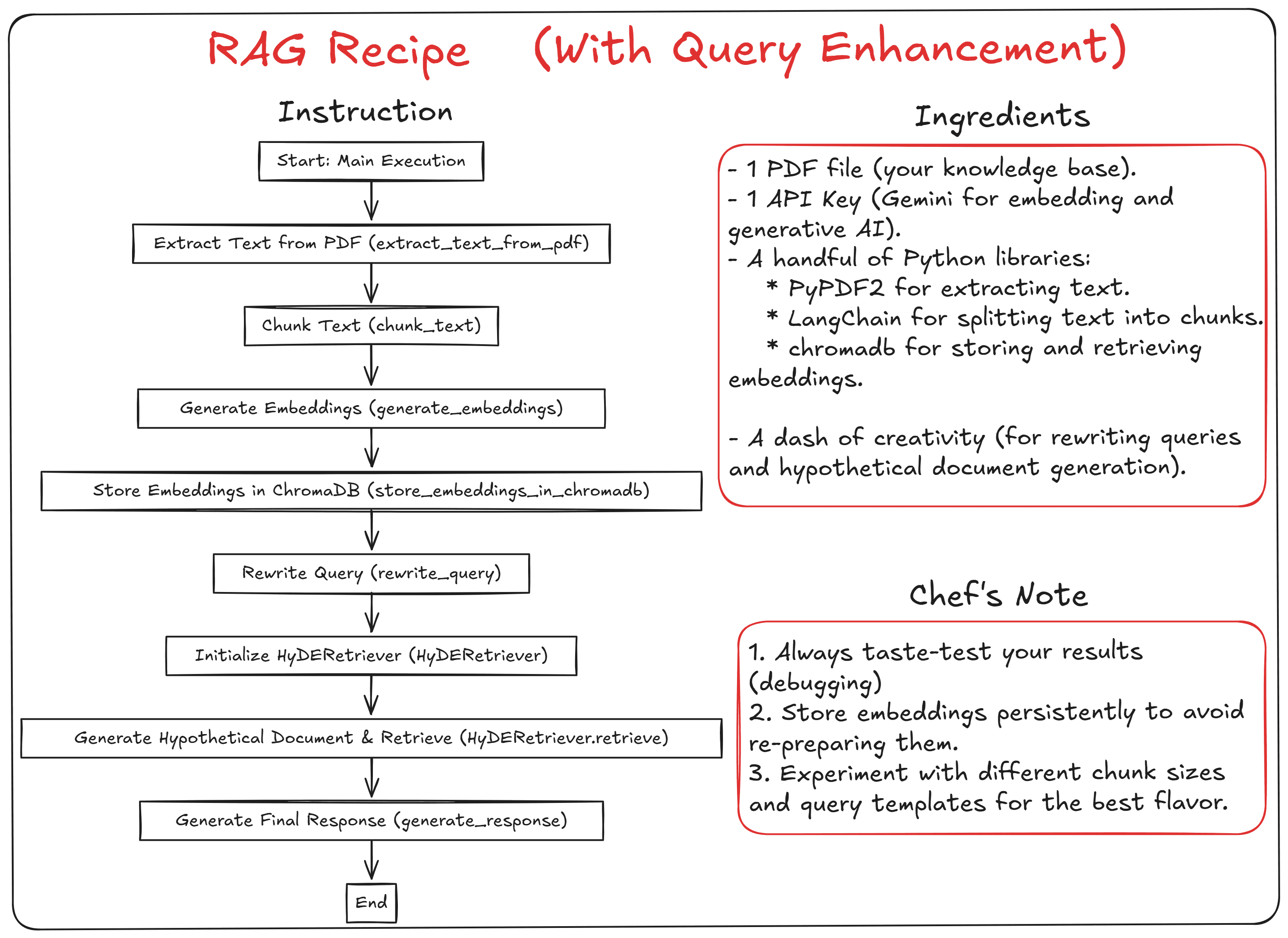
We will use the contents of a PDF file as our knowledge base, and store it in the ChromaDB vector database. For embedding and generative AI, we will use the Gemini family products; for that reason, you should get a Google API key. Additionally, we will use query rewriting and hypothetical document embedding to improve our generated results.
Query rewriting is a technique for improving the query passed for retrieval by making it more specific and detailed. Using an LLM, we pass the query and reformulate it into a better one.
Hypothetical document embedding (HyDE), on the other hand, is a technique for improving queries by transforming them into hypothetical documents containing potential answers. It’s intended to bridge the semantic gap between queries and documents in vector space by enhancing the query into hypothetical documents using an LLM, which we use for document retrieval. For simplicity, we will also use Jupyter Notebook instead of a classic IDE, but feel free to follow along as you see fit.
Cooking Up the Recipe
Let’s set up everything you need to implement our RAG recipe.
Let’s first set up a virtual environment:
python -m venv your-virtual-env-name
Activate the virtual environment by using the .\Scripts\activate command. Then, install all the packages required for our implementation to work correctly:
pip install PyPDF2 langchain google-generativeai chromadb
In your local directory, create a Python file called main.py and download the PDF we will use as a knowledge database. I will use this insurance handbook, but you can try another PDF file if you like.
With everything in place, we will start preparing the code for setting up the RAG system with query enhancement. We will import all the packages we use and set up the logger to log all our processes.
import PyPDF2
from langchain.text_splitter import RecursiveCharacterTextSplitter
import google.generativeai as genai
import chromadb
import logging
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)
Then, we will prepare all the functions used in our RAG system. For starters, we prepare a function to extract all the text from our PDF file:
def extract_text_from_pdf(pdf_path):
logger.info(f"Extracting text from PDF: pdf_path")
with open(pdf_path, "rb") as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
text += page.extract_text()
logger.info("Text extraction complete.")
return text
Passing the whole raw PDF file text into the generative AI will diminish the values of using the RAG. Instead, we want the most relevant result to pass into the LLM, which is located in the documents. For that reason, we will split our raw text data into chunks using the following function:
def chunk_text(text):
logger.info("Splitting text into chunks...")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", " ", ""]
)
chunks = text_splitter.split_text(text)
logger.info(f"Text split into len(chunks) chunks.")
return chunks
We have set it as 500 tokens per document with 50 tokens overlap, but you can change it with experimentation. There are no exact parameters for splitting the documents, so you will only know which parameters are the best by experimentation.
With the documents ready, we will process them into embeddings using Gemini:
genai.configure(api_key="YOUR-API-KEY")
def generate_embeddings(texts):
logger.info("Generating embeddings for text chunks...")
embeddings = []
for i, text in enumerate(texts):
logger.info(f"Generating embedding for chunk i + 1/len(texts)...")
result = genai.embed_content(
model="models/text-embedding-004",
content=text
)
embeddings.append(result['embedding'])
logger.info("Embeddings generated.")
return embeddings
All the chunk embeddings need to be stored somewhere. We will use ChromaDB as our vector database. If we are using ChromaDB, the data will be stored locally within our directory by default.
To set this up, we will set the function to store both the chunk documents and the embeddings.
def store_embeddings_in_chromadb(chunks, chunk_embeddings):
logger.info("Storing embeddings in ChromaDB...")
client = chromadb.Client()
# Change the collection name to your preferred name
collection = client.get_or_create_collection(name="insurance_chunks")
ids = [f"chunk_i" for i in range(len(chunks))]
metadatas = ["source": "pdf"] * len(chunks) # Add metadata if needed
collection.add(
documents=chunks,
embeddings=chunk_embeddings,
metadatas=metadatas,
ids=ids #Unique ID for each documents
)
logger.info("Embeddings stored in ChromaDB.")
return collection
We will prepare the RAG system using the documents stored in the vector database, starting with the query rewriting function.
def rewrite_query(original_query):
logger.info("Rewriting query...")
query_rewrite_template = """You are an AI assistant tasked with reformulating user queries to improve retrieval in a RAG system.
Given the original query, rewrite it to be more specific, detailed, and likely to retrieve relevant information.
Original query: original_query
Rewritten query:"""
# Use Gemini to rewrite the query
model = genai.GenerativeModel("gemini-1.5-flash")
# Generate and return our response
response = model.generate_content(query_rewrite_template.format(original_query=original_query))
logger.info("Query rewritten.")
return response.text
In the code above, we prepare a prompt template in which the model acts as an AI assistant that reformulates user queries.
Next, we will prepare the HyDE class that is able to generate the hypothetical documents and retrieve similar documents from our vector database.
class HyDERetriever:
def __init__(self, collection, chunk_size=500):
self.collection = collection
self.chunk_size = chunk_size
def generate_hypothetical_document(self, query):
logger.info("Generating hypothetical document...")
hyde_prompt = """Given the question 'query', generate a hypothetical document that directly answers this question. The document should be detailed and in-depth.
The document size should be approximately chunk_size characters."""
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content(hyde_prompt.format(query=query, chunk_size=self.chunk_size))
logger.info("Hypothetical document generated.")
return response.text
def retrieve(self, query, k=3):
logger.info("Retrieving relevant documents using HyDE...")
hypothetical_doc = self.generate_hypothetical_document(query)
hypothetical_embedding = generate_embeddings([hypothetical_doc])[0]
results = self.collection.query(
query_embeddings=[hypothetical_embedding],
n_results=k
)
similar_docs = results["documents"][0]
logger.info(f"Retrieved len(similar_docs) relevant documents.")
return similar_docs, hypothetical_doc
Using both query rewriting and HyDE, we should be able to improve our RAG results. It’s easy to setup, but you need to ensure the query result is still able to follow the original query intention.
Lastly, we will set the generation functions from our query:
def generate_response(query, context):
logger.info("Generating response...")
prompt = f"Context: context\n\nQuestion: query\n\nAnswer:"
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content(prompt)
logger.info("Response generated.")
return response.text
Taking It Out of the Oven
With everything in place, we set up the RAG system to run with the following code:
if __name__ == "__main__":
try:
# Step 1: Extract and chunk text
pdf_path = "Insurance_Handbook_20103.pdf"
logger.info(f"Starting process for PDF: pdf_path")
text = extract_text_from_pdf(pdf_path)
chunks = chunk_text(text)
# Step 2: Generate embeddings
chunk_embeddings = generate_embeddings(chunks)
# Step 3: Store embeddings in ChromaDB
collection = store_embeddings_in_chromadb(chunks, chunk_embeddings)
# Step 4: Rewrite the query
original_query = "What is residual markets in insurance?"
rewritten_query = rewrite_query(original_query)
logger.info(f"Rewritten Query: rewritten_query")
# Step 5: Retrieve relevant documents using HyDE
hyde_retriever = HyDERetriever(collection)
similar_docs, hypothetical_doc = hyde_retriever.retrieve(rewritten_query)
logger.info(f"Hypothetical Document: hypothetical_doc")
logger.info(f"Similar Documents: similar_docs")
# Step 6: Generate a response
context = " ".join(similar_docs)
response = generate_response(original_query, context)
logger.info(f"Generated Response: response")
except Exception as e:
logger.error(f"An error occurred: e", exc_info=True)
Replace the PDF path and the original query with what you intend to use in our example. Run it by using the following command:
The logging process will inform you of all the processes in the RAG system. For example, this is how the rewritten query result is from the simple query “What is residual markets in insurance?”
Rewritten Query: Explain the concept of residual markets in the insurance
industry, including the types of risks typically covered, how they operate,
and the regulatory frameworks governing their function in the United States
and/or [Specify a relevant country/region, if known]. Provide examples of
specific residual market mechanisms, such as state-sponsored insurance pools
or assigned risk plans.
From the rewritten query, it can evolve into hypothetical documents like the one below:
Hypothetical Document: Residual markets in insurance address risks deemed
too hazardous or unprofitable for the private sector. These markets, often
government-backed or mandated, provide coverage of last resort. In the US,
they include state-sponsored pools (e.g., for high-risk auto insurance) and
assigned risk plans, where insurers share responsibility for covering
high-risk individuals. Coverage typically encompasses auto insurance,
workers' compensation, and occasionally property insurance in high-risk
areas. Operation involves assessing risk, setting premiums (often higher
than private market rates), and distributing costs among participating
insurers. State regulations govern participation, rate setting, and solvency.
Strict oversight aims to prevent market distortions while ensuring access to
essential insurance. The system balances the need for widespread coverage
with the avoidance of excessive burdens on insurers and taxpayers
Using the hypothetical document above, our system will find the most related documents from our vector database and pass them into our LLM. The result that was generated to answer our questions is shown below.
Generated Response: In insurance, residual markets refer to the business that
insurers do not voluntarily assume. This is because the risks involved are
considered high, and insurers would typically avoid them in a competitive market.
These markets are also sometimes called "shared" markets because profits and
losses are shared among all insurers in a state offering that type of insurance,
or "involuntary" markets because participation isn't a choice for insurers.
Residual market programs often require some form of government intervention
or support because they are rarely self-sufficient.
That’s all for this Gemini RAG recipe, from which you can easily adapt and develop your own system with additional query enhancements to improve the results.
Wrapping Up
RAG is a technique for improving LLM model generated output by integrating external knowledge into the LLM’s existing knowledge. RAG is handy in use cases requiring specific domain knowledge and data privacy.
This article taught us how to cook up a RAG implementation recipe using the Gemini language model, ChromaDB vector database, and query enhancement techniques.
I hope this has helped!
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and data tips via social media and writing media. Cornellius writes on a variety of AI and machine learning topics.