
Spatial-temporal data handling involves the analysis of information gathered over time and space, often through sensors. Such data is crucial in pattern discovery and prediction. However, missing values pose a problem and make it challenging to analyze. Such gaps may often create inconsistencies with the dataset, causing harder analysis. The relationships between features, like environmental or physical factors, can be complex and influenced by a geographic context. Accurately capturing these relationships is critical but remains challenging due to varying feature correlations and limitations in existing methods, which struggle to address these complexities effectively.
Current methods for addressing missing values in spatial-temporal data rely on fixed spatial graphs and graph neural networks (GNNs) to capture spatial dependencies. These approaches assume that the spatial relationships between features are uniform across different locations. These approaches do not consider that features recorded by sensors often bear different relationships relative to their respective places and contexts. Therefore, these approaches do not properly manage and represent the different complex spatial relations of various characteristics, resulting in incorrect estimations about information-missing problems and the integration of detailed temporal and spatial interconnections.
To address spatial-temporal imputation challenges, researchers from Nankai University and Harbin Institute of Technology, Shenzhen, China, proposed the multi-scale Graph Structure Learning framework (GSLI). This framework adapts to spatial correlations by combining two approaches: node-scale learning and feature-scale learning. Node-scale learning focuses on global spatial dependencies for individual features, while feature-scale learning uncovers spatial relations among features within a node. Unlike conventional methods relying on static structures, this framework targets feature heterogeneity and integrates spatial-temporal correlations.
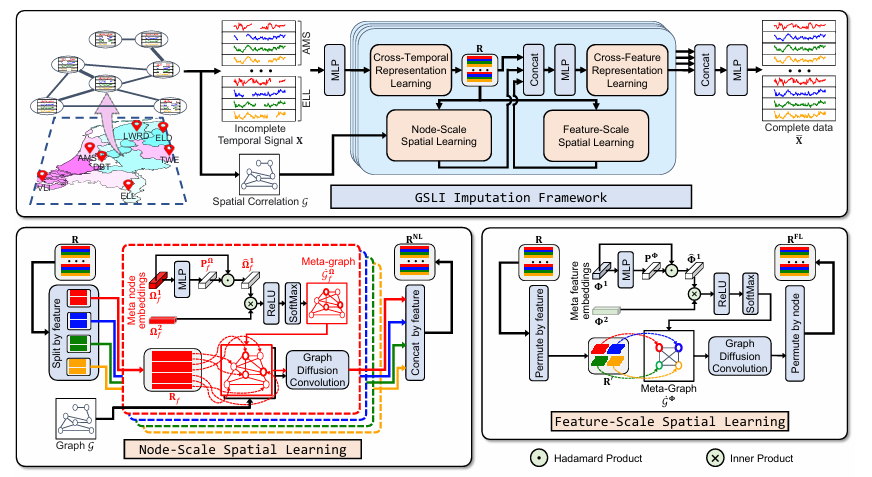
The framework used static graphs to represent spatial data and temporal signals for time-based information, with missing data indicated by masks. Node-scale learning refines embeddings using meta-nodes to highlight influential nodes, forming meta-graphs for feature-specific spatial dependencies. Feature-scale learning produces meta-graphs that capture spatial relations between features over nodes. This design tries to capture both cross-feature and cross-temporal dependencies but at the cost of computational complexity.
Researchers evaluated the performance of GSLI using an Intel Xeon Silver 4314 CPU and NVIDIA RTX 4090 GPU on six real-world spatial-temporal datasets with missing values. Adjacency matrices were constructed when not provided, and missing values lacking ground truth were excluded. Imputation accuracy was assessed using RMSE and MAE metrics under various missing rates, including MCAR, MAR, and MNAR. GSLI outperformed state-of-the-art methods across all datasets by effectively capturing spatial dependencies through graph structures. Its ability to model cross-temporal and cross-feature dependencies enabled superior adaptability to diverse scenarios, with results averaged over five trials demonstrating consistent accuracy even with increasing missing rates or mechanisms.
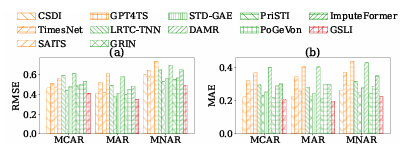
In conclusion, the proposed framework advances spatial-temporal imputation by addressing feature heterogeneity and leveraging multi-scale graph structure learning to improve accuracy. This work has thus shown, across six real-world datasets, that it performs better than more heuristic static spatial graph-based techniques and is robust to variations. This framework can act as a baseline for future research, inspiring advancements that reduce computational complexity, handle larger datasets, and enable real-time imputation for dynamic systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.