
Retrieval-Augmented Generation (RAG) is emerging as a pivotal technology in large language models (LLMs). It aims to enhance accuracy by integrating externally retrieved information with pre-existing model knowledge. This technology is particularly important in addressing the limitations of LLMs confined to their training datasets. It needs to be equipped to handle queries about recent or nuanced information not present in their training data.
The primary challenge in dynamic digital interactions involves integrating a model’s internal knowledge with accurate, timely external data. Effective RAG systems must seamlessly incorporate these elements to deliver precise responses, navigating the often conflicting data without compromising the reliability of the output.
Existing work includes the RAG model, which enhances generative models with real-time data retrieval to improve response accuracy and relevance. The Generation-Augmented Retrieval framework integrates dynamic retrieval with generative capabilities, significantly improving factual accuracy in responses. Commercially, models like ChatGPT and Gemini utilize retrieval-augmented approaches to enrich user interactions with current search results. Efforts to assess the performance of these systems include rigorous benchmarks and automated evaluation frameworks, focusing on the operational characteristics and reliability of RAG systems in practical applications.
Stanford researchers have introduced a systematic approach to analyzing how LLMs, specifically GPT-4, integrate and prioritize external information retrieved through RAG systems. What sets this method apart is its focus on the interplay between a model’s pre-trained knowledge and the accuracy of external data, using variable perturbations to simulate real-world inaccuracies. This analysis provides an understanding of the model’s adaptability, a crucial factor in practical applications where data reliability can vary significantly.
The methodology involved posing questions to GPT-4, both with and without perturbed external documents as context. Datasets utilized included drug dosages, sports statistics, and current news events, allowing a comprehensive evaluation across various knowledge domains. Each dataset was manipulated to include variations in data accuracy, assessing the model’s responses based on how well it could discern and prioritize information depending on its fidelity to known facts. The researchers employed both “strict” and “loose” prompting strategies to explore how different types of RAG deployment impact the model’s reliance on its pre-trained knowledge versus the altered external information. This process highlighted the model’s reliance on its internal expertise versus retrieved content, offering insights into the strengths and limitations of current RAG implementations.
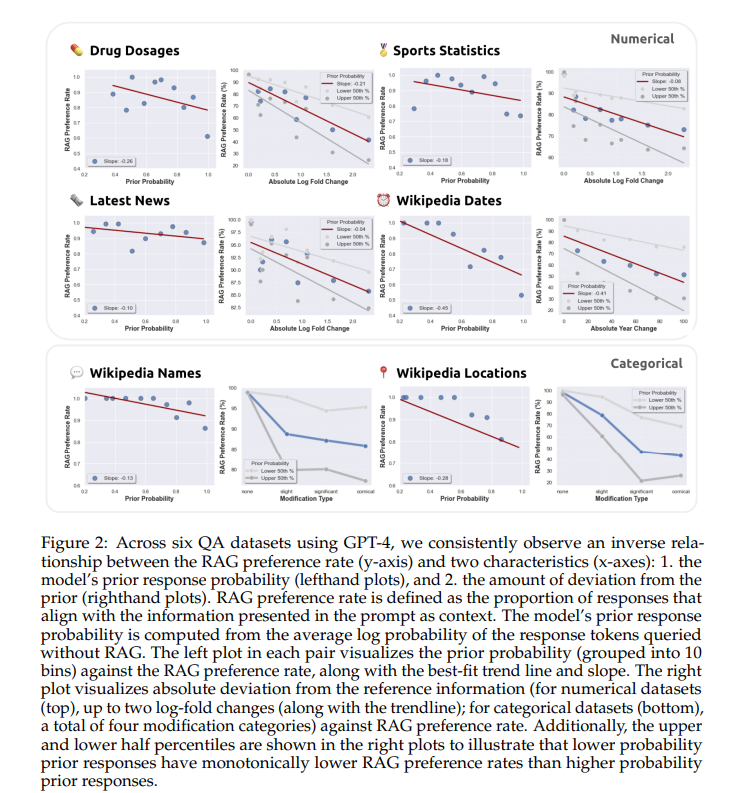
The study found that when correct information was provided, GPT-4 corrected its initial errors in 94% of cases, significantly enhancing response accuracy. However, when external documents were perturbed with inaccuracies, the model’s reliance on flawed data increased, especially when its internal knowledge was less robust. For example, with growing deviation in the data, the model’s preference for external information over its knowledge dropped noticeably, with an observed decline in correct response adherence by up to 35% as the perturbation level increased. This demonstrated a clear correlation between data accuracy and the effectiveness of RAG systems.
In conclusion, this research thoroughly analyzes RAG systems in LLMs, specifically exploring the balance between internally stored knowledge and externally retrieved information. The study reveals that while RAG systems significantly improve response accuracy when provided with correct data, their effectiveness diminishes with inaccurate external information. These insights underline the importance of enhancing RAG system designs to discriminate better and integrate external data, ensuring more reliable and robust model performance across varied real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
For Content Partnership, Please Fill Out This Form Here..
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.