

Image by Author | Ideogram
This article provides a conceptual overview and guide to understanding how to evaluate large language models (LLMs) built for addressing a variety of language use cases. A tour of common evaluation metrics and the specific language tasks they are intended for is provided, followed by a list of guidelines and best practices to shape a comprehensive and solid evaluation methodology.
An Overview of Common Metrics for LLMs Evaluation
LLMs are evaluated differently depending on the primary language task they are designed for. This diagram summarizes some common metrics used for various language tasks.
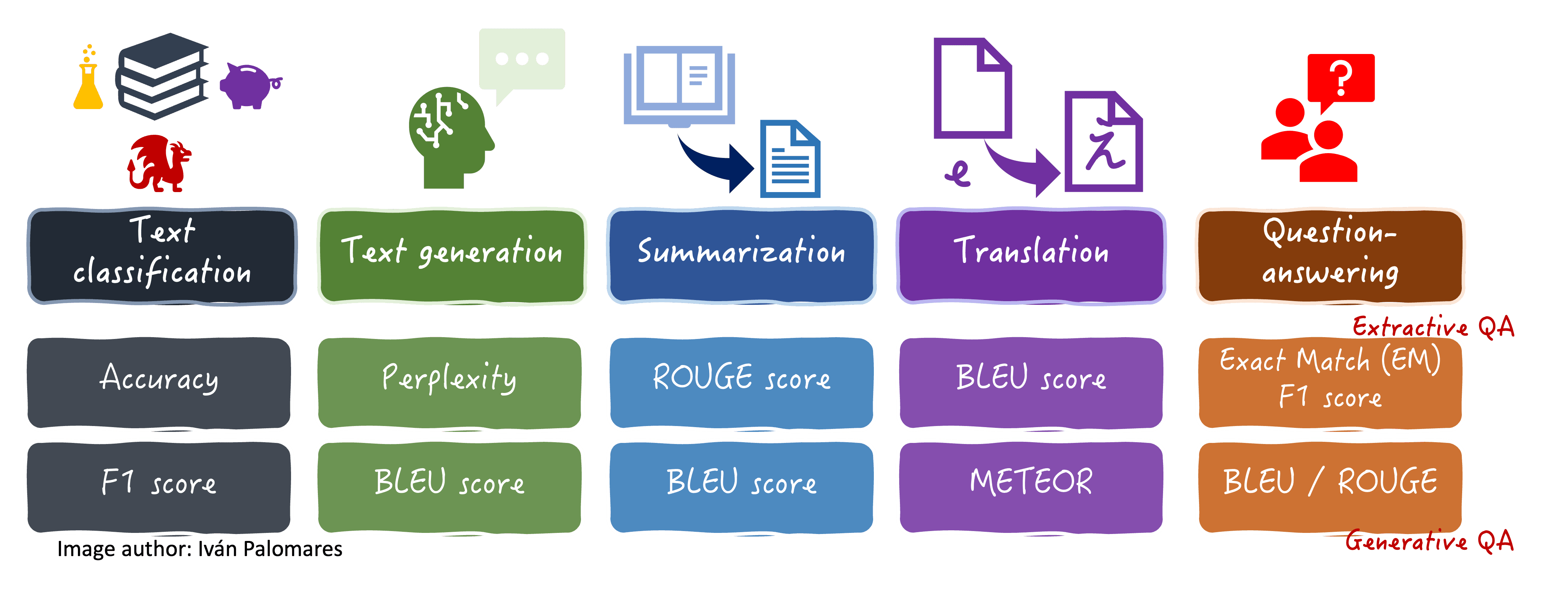
Common metrics to evaluate several language tasks in LLMs
Whilst in practice most metrics introduced can be used for several language tasks, as shown in the above diagram, below we categorize metrics based on the primary use case each is intended for.
Metrics for Text Classification LLMs
In LLMs trained specifically for classification tasks such as sentiment analysis or intent recognition in text, measuring their performance boils down to determining their classification accuracy. The simplest approach to doing this is calculating the percentage of correctly classified texts by the model out of the total number of examples in a test or validation set with ground-truth labels. Naturally, comprehensive classification metrics like F1-score and area under ROC curves can also be used.
Metrics for Text Generation LLMs
Evaluating LLMs specialized in language generation, such as GPT models, requires more specific metrics. One of them is perplexity, which measures how well the model predicts a sequence of words. Given the number of tokens N in a generated sequence and the probability associated with the ith generated token P(wi), perplexity can be computed by taking the exponential of the average negative log-likelihood of the predicted probabilities.
Lower perplexity signifies better performance, meaning the model assigned higher probabilities to the correct sequence of words, being more confident in the output produced.
Metrics for Text Summarization LLMs
A popular metric defined for evaluating text summarization LLMs is ROUGE (Recall-Oriented Understudy for Gist Evaluation). It measures the overlap between a summary generated by the model and one or several ground-truth, human-written summaries for the original text, called reference summaries. Variations of ROUGE like ROUGE-1, ROUGE-2, etc., capture different similarity nuances through n-gram overlapping measures. The reliance on human-generated reference summaries implies that ROUGE may sometimes be costly to utilize, which can be partly alleviated by human evaluation of generated summaries to ensure the quality of outputs.
Metrics for Language Translation LLMs
In addition to ROUGE, there is another metric defined to measure the quality of translations generated by LLMs by comparing them with reference translation: BLEU (BiLingual Evaluation Understudy). BLEU computes a similarity score between 0 and 1 by evaluating the overlap of n-grams between the generated translation and the reference translation. One aspect in which it differs from ROUGE is that it can apply a brevity penalty to discourage overly short translations, thereby adapting the computations to the specific use case of translating text.
An alternative metric that overcomes some limitations of ROUGE and BLEU is METEOR (Metric for Evaluation of Translations with Explicit ORdering). It is a more comprehensive metric that factors in aspects like N-gram overlap, precision, recall, word order, synonyms, stemming, and so on, thereby being sometimes used to evaluate the quality of generated text beyond just translations.
Metrics for Question-Answering (Q-A) LLMs
Question-answering LLMs can be extractive or abstractive. The simpler ones, extractive Q-A LLMs, extract the answer to an input question from a context (classically provided alongside the input but can also be built by RAG systems), performing a classification task at their core. Meanwhile, abstractive Q-A LLMs generate the answer “from scratch”. The bottom line, different evaluation metrics are used depending on the type of Q-A task:
- For extractive Q-A, a combination of F1 score and Exact Match (EM) is typically used. The EM evaluates whether the LLM’s extracted answer span matches a ground-truth answer exactly. The strict behavior of EM is smoothened by using it in conjunction with F1.
- For abstractive Q-A, metrics for assessing the quality of generated outputs like ROUGE, BLEU, and METEOR, are preferred.
How about perplexity? Isn’t it utilized for advanced text-generation-based tasks like summarization, translation, and abstractive Q-A? The truth is that this metric’s suitability is more nuanced and narrowed down to LLMs specialized in “plain text generation”, that is, given an input prompt, continuing or extending it by completing the follow-up sequence of words.
To gain an understanding of how these metrics behave, this table provides some simple examples of their use.
| Metric | Reference/Ground Truth | Model Output | Metric Score | Behavior |
|---|---|---|---|---|
| Perplexity | “The cat sat on the mat” | “A cat sits on the mat” | Lower (Better) | Measures how “surprised” the model is by the text. More predictable generated words equals less perplexity |
| ROUGE-1 | “The quick brown fox jumps” | “The brown fox quickly jumps” | Higher (Better) | Counts matching individual words: “the”, “brown”, “fox” = 3 matching unigrams |
| BLEU | “I love eating pizza” | “I really enjoy eating pizza” | Higher (Better) | Checks precise word matches: “I”, “eating”, “pizza” = partial match |
| METEOR | “She plays tennis every weekend” | “She plays tennis on weekends” | Higher (Better) | Allows more flexible matches: “plays”, “tennis”, “weekend” considered similar |
| Exact Match (EM) | “Paris is the capital of France” | “Paris is the capital of France” | 1 (Perfect) | Only counts as correct if entire response exactly matches ground truth |
| Exact Match (EM) | “Paris is the capital of France” | “Paris is France’s capital city” | 0 (No Match) | Slight variation means zero match |
Check out this article for a more practical insight into these metrics.
Guidelines and Best Practices for Evaluating LLMs
Now that you know the most common metrics for evaluating LLMs, how about outlining some guidelines and best practices for using them, thereby establishing solid evaluation methodologies?
- Be aware, realistic, and comprehensive in your LLM evaluation. Aware of the insights and limitations brought by each metric, realistic about the specific use case you are evaluating and the ground truth used, and comprehensive by using a balanced combination of metrics rather than a single one.
- Consider human feedback in the evaluation loop: objective metrics provide consistency in evaluations, but the subjectivity inherent to human evaluation is invaluable for nuanced judgments, such as assessing relevance, coherence, or creativity of generated outputs. Minimize the risk of bias by using clear guidelines, multiple reviewers, and advanced approaches like Reinforcement Learning from Human Feedback (RLHF), .
- Coping with model hallucinations during evaluation: hallucinations, where the LLM generates textually coherent but factually incorrect information, are hard to spot and evaluate. Investigate and use highly specialized metrics like FEVER, that assess factual accuracy, or rely on human reviewers to detect and penalize outputs containing hallucinations, especially in high-stakes domains like healthcare or law.
- Efficiency and scalability considerations: ensuring efficiency and scalability often involves automating parts of the process, e.g. by leveraging metrics like BLEU or F1 for batch evaluations, while limiting human assessments for critical cases.
- Ethical considerations for LLM evaluation: supplement the overall evaluation methodology for your LLMs with approaches to measure fairness, bias, and societal impacts. Define metrics that account for how the model performs across diverse groups, languages, and content types to avoid perpetuating biases, ensure data privacy mechanisms, and prevent unintentionally reinforcing harmful stereotypes or misinformation.
Wrapping Up
This article provided a conceptual overview of metrics, concepts, and guidelines needed to understand the how-tos, nuances, and challenges of evaluating LLMs. From this point, we recommend venturing into practical tools and frameworks to evaluate LLMs like Hugging Face’s evaluate library, which implements all the metrics defined in this article, or this article that discussed enhanced evaluation approaches.
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.