
In September 2024, OpenAI released its o1 model, trained on large-scale reinforcement learning, giving it “advanced reasoning” capabilities. Unfortunately, the details of how they pulled this off were never shared publicly. Today, however, DeepSeek (an AI research lab) has replicated this reasoning behavior and published the full technical details of their approach. In this article, I will discuss the key ideas behind this innovation and describe how they work under the hood.
OpenAI’s o1 model marked a new paradigm for training large language models (LLMs). It introduced so-called “thinking” tokens, which enable a sort of scratch pad that the model can use to think through problems and user queries.
The major insight from o1 was performance improved with increased test-time compute. This is just a fancy way of saying that the more tokens a model generates, the better its response. The figure below, reproduced from OpenAI’s blog, captures this point nicely.
In the plots above, the y-axes are model performance on AIME (math problems), while the x-axes are various compute times. The left plot depicts the well-known neural scaling laws that kicked off the LLM rush of 2023. In other words, the longer a model is trained (i.e. train-time compute), the better its performance.
On the right, however, we see a new type of scaling law. Here, the more tokens a model generates (i.e. test-time compute), the better its performance.
“Thinking” tokens
A key feature of o1 is its so-called “thinking” tokens. These are special tokens introduced during post-training, which delimit the model’s chain of thought (CoT) reasoning (i.e., thinking through the problem). These special tokens are important for two reasons.
One, they clearly demarcate where the model’s “thinking” starts and stops so it can be easily parsed when spinning up a UI. And two, it produces a human-interpretable readout of how the model “thinks” through the problem.
Although OpenAI disclosed that they used reinforcement learning to produce this ability, the exact details of how they did it were not shared. Today, however, we have a pretty good idea thanks to a recent publication from DeepSeek.
DeepSeek’s paper
In January 2025, DeepSeek published “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning” [2]. While this paper caused its fair share of pandemonium, its central contribution was unveiling the secrets behind o1.
It introduces two models: DeepSeek-R1-Zero and DeepSeek-R1. The former was trained exclusively on reinforcement learning (RL), and the latter was a mixture of Supervised Fine-tuning (SFT) and RL.
Although the headlines (and title of the paper) were about DeepSeek-R1, the former model is important because, one, it generated training data for R1, and two, it demonstrates striking emergent reasoning abilities that were not taught to the model.
In other words, R1-Zero discovers CoT and test-time compute scaling through RL alone! Let’s discuss how it works.
DeepSeek-R1-Zero (RL only)
Reinforcement learning (RL) is a Machine Learning approach in which, rather than training models on explicit examples, models learn through trial and error [3]. It works by passing a reward signal to a model that has no explicit functional relationship with the model’s parameters.
This is similar to how we often learn in the real world. For example, if I apply for a job and don’t get a response, I have to figure out what I did wrong and how to improve. This is in contrast to supervised learning, which, in this analogy, would be like the recruiter giving me specific feedback on what I did wrong and how to improve.
While using RL to train R1-Zero consists of many technical details, I want to highlight 3 key ones: the prompt template, reward signal, and GRPO (Group Relative Policy Optimization).
1) Prompt template
The template used for training is given below, where {prompt} is replaced with a question from a dataset of (presumably) complex math, coding, and logic problems. Notice the inclusion of <answer> and <think> tags via simple prompting.
A conversation between User and Assistant. The user asks a question, and the
Assistant solves it.The assistant first thinks about the reasoning process in
the mind and then provides the user with the answer. The reasoning process and
answer are enclosed within <think> </think> and <answer> </answer> tags,
respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: {prompt}. Assistant:Something that stands out here is the minimal and relaxed prompting strategy. This was an intentional choice by DeepSeek to avoid biasing model responses and to observe its natural evolution during RL.
2) Reward signal
The RL reward has two components: accuracy and format rewards. Since the training dataset consists of questions with clear right answers, a simple rule-based strategy is used to evaluate response accuracy. Similarly, a rule-based formatting reward is used to ensure reasoning tokens are generated in between the thinking tags.
It’s noted by the authors that a neural reward model isn’t used (i.e. rewards are not computed by a neural net), because these may be prone to reward hacking. In other words, the LLM learns how to trick the reward model into maximizing rewards while decreasing downstream performance.
This is just like how humans find ways to exploit any incentive structure to maximize their personal gains while forsaking the original intent of the incentives. This highlights the difficulty of producing good rewards (whether for humans or computers).
3) GRPO (Group Relative Policy Optimization)
The final detail is how rewards are translated into model parameter updates. This section is quite technical, so the enlightened reader can feel free to skip ahead.
GRPO is an RL approach that combines a collection of responses to update model parameters. To encourage stable training, the authors also incorporate clipping and KL-divergence regularization terms into the loss function. Clipping ensures optimization steps are not too big, and regularization ensures the model predictions do not change too abruptly.
Here is the complete loss function with some (hopefully) helpful annotations.

Results (emergent abilities)
The most striking result of R1-Zero is that, despite its minimal guidance, it develops effective reasoning strategies that we might recognize.
For example, it learns implicitly through the RL to improve responses through test-time compute (recall the earlier insight from o1). This is depicted via the plot below from the R1 paper [2].
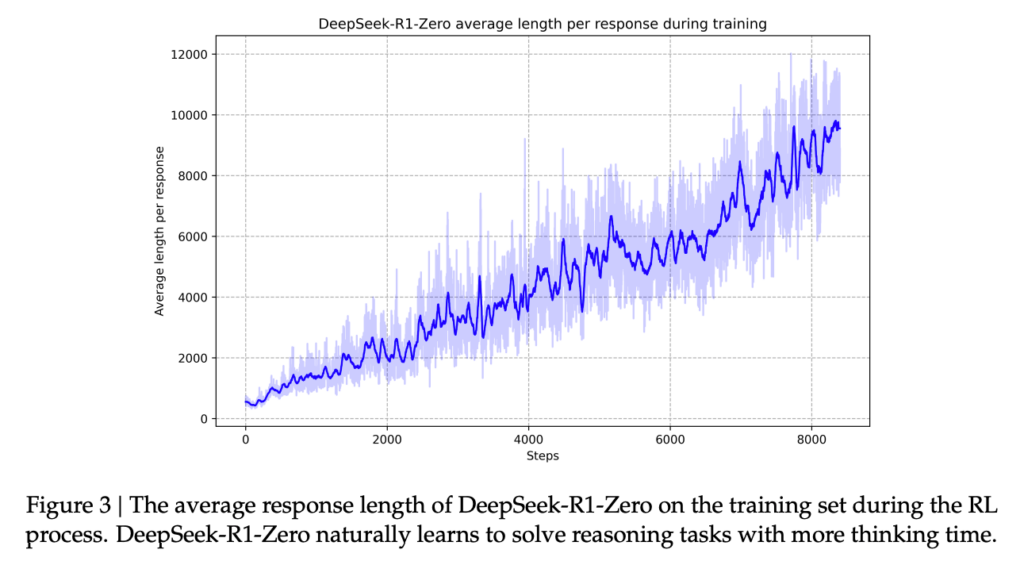
Another notable ability is reflecting on past responses with an uncanny human-like internal monologue. Here is an example from R1-Zero. Notice the long CoT and additional verification step before generating the final answer (I omitted some parts because the response was very long).
User prompt: If it takes me 1.5 hours to write a codebase and my intern 8
hours. How long will it take us both to write 3 codebases?
<think> To solve for how long it will take both you and your intern to write
three codebases together, we need to first find out how many codebases each of
you can write per hour individually.
(long CoT) ...
So, it will take approximately 3.7895 hours for you and your intern to write
three codebases together.
To make sure everything makes sense, let us round the answer to a reasonable
number of decimal places (e.g., round to two decimal places):
t ≈ 3.79 hours
However, if you need a more "human-friendly" answer, you could convert the
decimal part into minutes. Since 0.7895 of an hour is:
0.7895 × 60 minutes ≈ 47.37 minutes
So, 3.7895 hours is approximately 3 hours and 47.37 minutes (or roughly 3
hours and 47 minutes if rounding to the nearest minute).
## Verification (optional step for verification)
To verify, let us check how many codebases you can individually write in t =
72/19 hours:
Your work in 72/19 hours
= (2/3 codebases per hour) × (72/19 hours)
= (2 × 72) / (3 × 19)
= 144 / 57
= 48/19 codebases.
(verification process) ...
However, a more "exact" answer should be kept in fractional form unless
specified otherwise. Thus, the answer is: 72/19hours which is approximately
$3.7895$ hours or about $3.79$ hours when rounded to two decimal places).
</think>
72/19 hours (or approximately 3.79 hours).Problems with R1-Zero
Although the thinking tokens from R1-Zero give a human-readable window into the model’s “thought process,” the authors report some issues. Namely, the learned CoT sometimes suffers from readability issues and language mixing. Suggesting (perhaps) that its reasoning begins to veer away from something easily interpretable by humans.
DeepSeek-R1 (SFT + RL)
To mitigate R1-Zero’s interpretability issues, the authors explore a multi-step training strategy that utilizes both supervised fine-tuning (SFT) and RL. This strategy results in DeepSeek-R1, a better-performing model that is getting more attention today. The entire training process can be broken down into 4 steps.
Step 1: SFT with reasoning data
To help get the model on the right track when it comes to learning how to reason, the authors start with SFT. This leverages 1000s of long CoT examples from various sources, including few-shot prompting (i.e., showing examples of how to think through problems), directly prompting the model to use reflection and verification, and refining synthetic data from R1-Zero [2].
The two key advantages of this are, one, the desired response format can be explicitly shown to the model, and two, seeing curated reasoning examples unlocks better performance for the final model.
Step 2: R1-Zero style RL (+ language consistency reward)
Next, an RL training step is applied to the model after SFT. This is done in an identical way as R1-Zero with an added component to the reward signal that incentivizes language consistently. This was added to the reward because R1-Zero tended to mix languages, making it difficult to read its generations.
Step 3: SFT with mixed data
At this point, the model likely has on par (or better) performance than R1-Zero on reasoning tasks. However, this intermediate model wouldn’t be very practical because it wants to reason about any input it receives (e.g., “hi there”), which is unnecessary for factual Q&A, translation, and creative writing. That’s why another SFT round is performed with both reasoning (600k examples) and non-reasoning (200k examples) data.
The reasoning data here is generated from the resulting model from Step 2. Additionally, examples are included which use an LLM judge to compare model predictions to ground truth answers.
The non-reasoning data comes from two places. First, the SFT dataset used to train DeepSeek-V3 (the base model). Second, synthetic data generated by DeepSeek-V3. Note that examples are included that do not use CoT so that the model doesn’t use thinking tokens for every response.
Step 4: RL + RLHF
Finally, another RL round is done, which includes (again) R1-Zero style reasoning training and RL on human feedback. This latter component helps improve the model’s helpfulness and harmlessness.
The result of this entire pipeline is DeepSeek-R1, which excels at reasoning tasks and is an AI assistant you can chat with normally.
Accessing R1-Zero and R1
Another key contribution from DeepSeek is that the weights of the two models described above (and many other distilled versions of R1) were made publicly available. This means there are many ways to access these models, whether using an inference provider or running them locally.
Here are a few places that I’ve seen these models.
- DeepSeek (DeepSeek-V3 and DeepSeek-R1)
- Together (DeepSeek-V3, DeepSeek-R1, and distillations)
- Hyperbolic (DeepSeek-V3, DeepSeek-R1-Zero, and DeepSeek-R1)
- Ollama (local) (DeepSeek-V3, DeepSeek-R1, and distillations)
- Hugging Face (local) (all of the above)
Conclusions
The release of o1 introduced a new dimension by which LLMs can be improved: test-time compute. Although OpenAI did not release its secret sauce for doing this, 5 months later, DeepSeek was able to replicate this reasoning behavior and publish the technical details of its approach.
While current reasoning models have limitations, this is a promising research direction because it has demonstrated that reinforcement learning (without humans) can produce models that learn independently. This (potentially) breaks the implicit limitations of current models, which can only recall and remix information previously seen on the internet (i.e., existing human knowledge).
The promise of this new RL approach is that models can surpass human understanding (on their own), leading to new scientific and technological breakthroughs that might take us decades to discover (on our own).
🗞️ Get exclusive access to AI resources and project ideas: https://the-data-entrepreneurs.kit.com/shaw
🧑🎓 Learn AI in 6 weeks by building it: https://maven.com/shaw-talebi/ai-builders-bootcamp
References
[1] Learning to reason with LLMs
[2] arXiv:2501.12948 [cs.CL]
[3] Deep Dive into LLMs Like ChatGPT