
Data discovery has become increasingly challenging due to the proliferation of easily accessible data analysis tools and low-cost cloud storage. While these advancements have democratized data access, they have also led to less structured data stores and a rapid expansion of derived artifacts in enterprise environments. The growing complexity of data landscapes has made it difficult for users to find the right data for their tasks. Metadata, including information on ownership, usage, certification, and relationships, can be crucial in overpowering this challenge by providing context and constraining the search space. However, current data analysis tools offer limited support for metadata-driven data discovery, especially for non-technical users.
Existing attempts to overcome data discovery challenges have focused on two main areas: techniques for extracting and computing metadata, and interactive interfaces for data discovery. Researchers have developed methods to calculate relationships between datasets using various similarity measures and ensemble approaches to improve data discovery. On the interface side, faceted browsers, dynamic queries, and visual interaction systems like Kyrix-J, Auctus, and Ronin have been introduced to enhance user experience. However, these approaches often need more means to configure and customize data discovery UIs, typically hardcoding the data search support based on specific types of metadata. This lack of flexibility makes it difficult to adapt to evolving user needs and varying considerations of relevance across different domains and use cases, highlighting the need for more adaptable and customizable solutions.
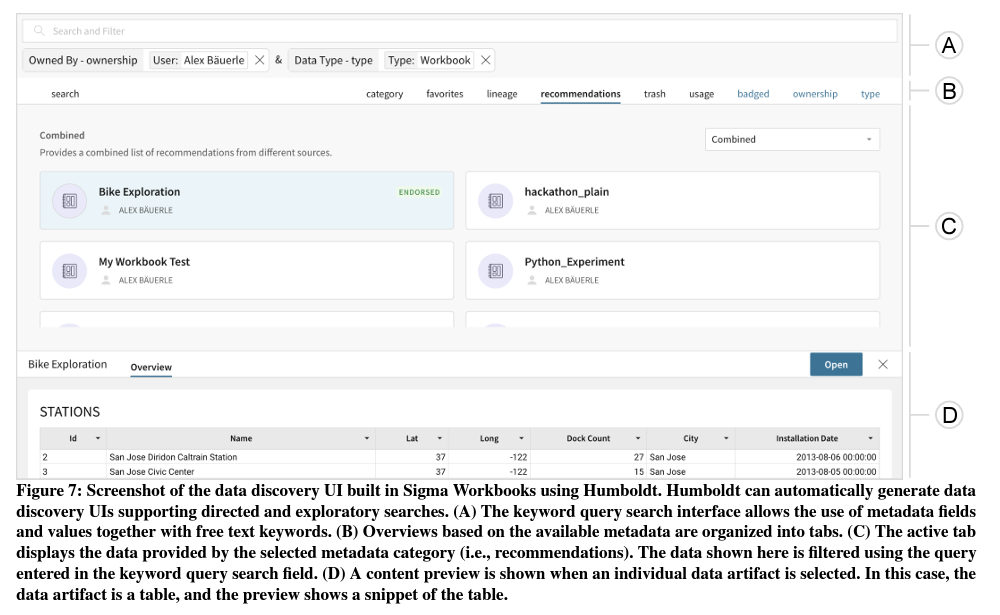
Researchers from AxiomBio, Amazon, and MIT introduce Humboldt as a unique solution to dynamically generate data discovery user interfaces (UIs) from declarative specifications. This approach enables easy integration and use of various metadata types in interactive data systems without requiring costly software upgrades. Humboldt’s framework allows for the addition of new metadata providers with minimal effort, automatically generating relevant views and visualizations. The system supports three main data discovery features: overviews, exploration, and search, catering to users’ needs for contextual views, exploration tools, and filtering options. Humboldt serves as an abstraction layer between metadata providers and the data discovery UI, facilitating easy modifications without altering UI code. Implemented in Sigma Workbook, a commercial SaaS application for business data analysis, Humboldt demonstrates its ability to generate interactive UIs supporting multiple search paradigms, various view types, composable queries, and ranking algorithms for metadata-driven data discovery. User studies have shown the effectiveness of the generated UI in integrating metadata for improved data discovery and search, highlighting Humboldt’s potential to tailor data discovery UIs to diverse user needs and preferences.
Humboldt is a framework for generating dynamic data discovery UIs based on declarative specifications. It has three key design goals: expressivity, composability, and configurability. The framework enables easy integration of various metadata types without requiring UI code changes. Humboldt’s specification formalizes data representations, including metadata providers, ranking, and customization options. It supports three main aspects of data discovery: overviews, exploration, and search. The system automatically generates views for different metadata providers, facilitates interactive data exploration, and creates a flexible query language for advanced search and filtering. Implemented in the Sigma Workbook, Humboldt demonstrates its ability to produce interactive UIs supporting multiple search paradigms, various view types, and composable queries. This approach allows for adaptable and customizable data discovery interfaces that can evolve with user needs and new metadata types, improving the overall data discovery experience in interactive data systems.
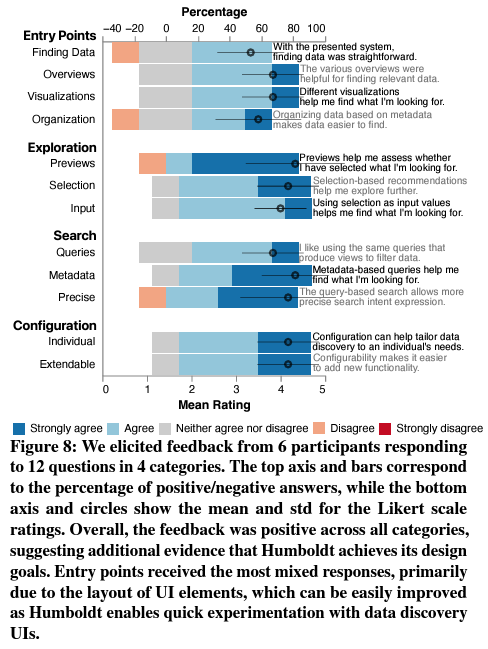
The user study of Humboldt-generated data discovery UI in the Sigma Workbook yielded positive results across four main tasks. All participants completed the tasks, with some needing minor assistance. The study revealed diverse user preferences in data discovery approaches, highlighting the importance of Humboldt’s flexibility. Participants appreciated the variety of views, exploration capabilities, and complex query interface. The customizability feature was highly valued, allowing users to tailor the interface to their specific needs. While some areas for improvement were identified, such as clearer metadata provider descriptions and enhanced layout, the post-study questionnaire revealed overall positive feedback across all categories. Metadata support for search and previews received the highest ratings. The study demonstrates Humboldt’s effectiveness in generating adaptable and user-friendly data discovery interfaces, achieving its design goals of expressivity, composability, and configurability.
The Humboldt framework operationalizes key ideas for effective data discovery in modern data systems. It treats metadata as a first-class citizen, enabling users to search and navigate data using valuable business and usage context. Recognizing diverse needs across organizations, teams, and individuals, Humboldt offers flexible interfaces that easily integrate various metadata sources. The framework supports multiple discovery paradigms and views, catering to different user preferences. Its reconfigurability and extensibility allow for customization to meet domain-specific requirements. By implementing these ideas, Humboldt provides a powerful, adaptable solution for creating user-friendly, context-rich data discovery interfaces that evolve with user needs and organizational demands.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.