
Multimodal Language Models MLLMs architectures have evolved to enhance text-image interactions through various techniques. Models like Flamingo, IDEFICS, BLIP-2, and Qwen-VL use learnable queries, while LLaVA and MGM employ projection-based interfaces. LLaMA-Adapter and LaVIN focus on parameter-efficient tuning. Dataset quality significantly impacts MLLM effectiveness, with recent studies refining visual instruction tuning datasets to improve performance across question-answering tasks. High-quality fine-tuning datasets with extensive task diversity have been leveraged to excel in image perception, reasoning, and OCR tasks.
The Img-Diff dataset introduces a novel approach by emphasizing image difference analysis, showing empirical effectiveness in augmenting MLLMs’ VQA proficiency and object localization capabilities. This focus sets Img-Diff apart from existing datasets and builds upon foundational works in the field. Previous methods like Shikra, ASM, and PINK utilized substantial amounts of object detection data to enhance MLLM localization capabilities, laying the groundwork for Img-Diff’s innovative approach to fine-grained image recognition and analysis.
The paper introduces the Img-Diff dataset, designed to enhance MLLMs’ fine-grained image recognition capabilities by focusing on object differences between similar images. Using a Difference Area Generator and a Difference Captions Generator, the dataset challenges MLLMs to identify matching and distinct components. Models fine-tuned with Img-Diff outperform state-of-the-art models on various image difference and VQA tasks. The study emphasizes the importance of high-quality data and evolving model architectures in improving MLLM performance. It reviews existing approaches like learnable queries and projection-based interfaces, highlighting the need for better datasets to tackle complex visual tasks involving subtle image differences. The research confirms Img-Diff’s diversity and quality, encouraging further exploration in multimodal data synthesis.
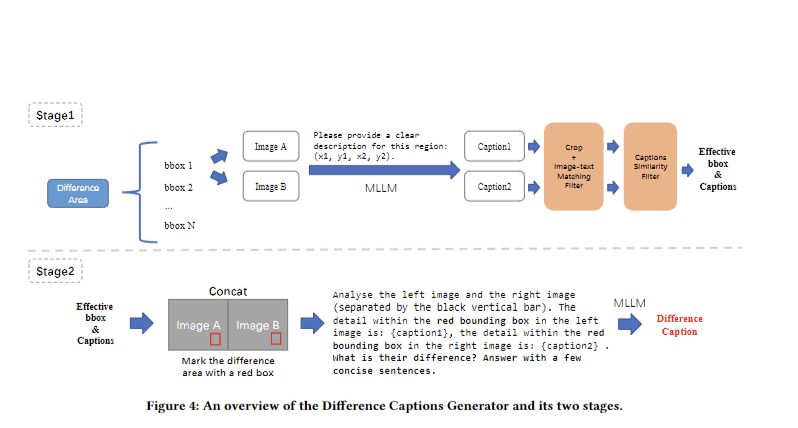
The researchers developed the Img-Diff dataset through a systematic approach. They generated 118,000 image pairs using MSCOCO captions, applying an Image Similarity Filter to obtain 38,533 highly similar pairs. Bounding box regions with lowest similarity were selected, setting N to 5. Two filtering processes—Image-Text Matching and Captions Similarity—ensured valid bounding boxes and captions. A Difference Area Generator produced 117,779 pieces of bounding box data, while a Difference Captions Generator created 12,688 high-quality “object replacement” instances with detailed descriptions. Finally, state-of-the-art MLLMs like LLaVA-1.5-7B and MGM-7B were fine-tuned using the dataset to improve performance on image difference tasks and VQA challenges, demonstrating Img-Diff’s effectiveness in enhancing MLLMs’ fine-grained image recognition capabilities.
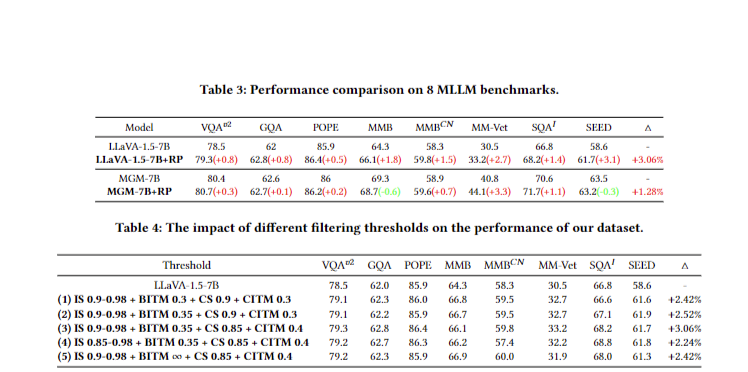
The Img-Diff dataset significantly enhanced MLLM performance on various benchmarks. LLaVA-1.5-7B showed improved scores on multiple tests, while MGM-7B had mixed results. Both models achieved new state-of-the-art scores on the Image-Editing-Request benchmark. LLaVA-1.5-7B achieved a 3.06% average performance increase across all benchmarks, compared to MGM-7B’s 1.28%. The improvements extended to Visual Question-answering tasks, demonstrating Img-Diff’s effectiveness in enhancing MLLMs’ image difference recognition and editing capabilities.
In conclusion, the paper introduces a novel dataset designed to enhance MLLMs’ performance in image difference recognition tasks. The Img-Diff dataset, created through innovative methods combining contrastive learning and image difference captioning, focuses on object differences in paired images. Fine-tuning MLLMs with this dataset yields competitive performance scores comparable to models trained on much larger datasets. The study emphasizes the importance of careful data generation and filtering processes, providing insights for future research in multimodal data synthesis. By demonstrating the effectiveness of targeted, high-quality datasets in improving MLLMs’ capabilities, the paper encourages further exploration in fine-grained image recognition and multimodal learning.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI