
Let’s Build a RAG-Powered Research Paper Assistant
Image by Author | Ideogram
In the era of generative AI, people have relied on LLM products such as ChatGPT to help with tasks. For example, we can quickly summarize our conversation or answer the hard questions. However, sometimes, the generated text is not accurate and irrelevant.
The RAG technique is emerging to help solve the problem above. Using the external knowledge source, an LLM can gain context not present in its data training. This method will enhance model accuracy and allow the model to access real-time data.
As the technique improves output relevancy, we can build a specific project around them. That’s why this article will explore how we can build a research paper assistant powered by RAG.
Preparation
For starters, we need to create a virtual environment for our project. You can initiate it with the following code.
|
python venv –m your_virtual_environment_name |
Activate the virtual environment, and then install the following libraries.
|
pip install streamlit PyPDF2 sentence–transformers chromadb litellm langchain langchain–community python–dotenv arxiv huggingface_hub |
Additionally, don’t forget to acquire a Gemini API key and a HuggingFace token to access the repository, as we will use them.
Create the file called app.py for building the assistant and .env file where you put the API key.
With everything in place, let’s start to build the assistant.
RAG-Powered Research Paper Assistant
Let’s start building our project. We will develop our research paper assistant with two different features for references. First, we can upload our PDF research paper and store it in a vector database for users to retrieve later. Second, we could search research papers within the arXiv paper database and store them in the vector database.
The image below shows this workflow for reference. The code for this project is also stored in the following repository.
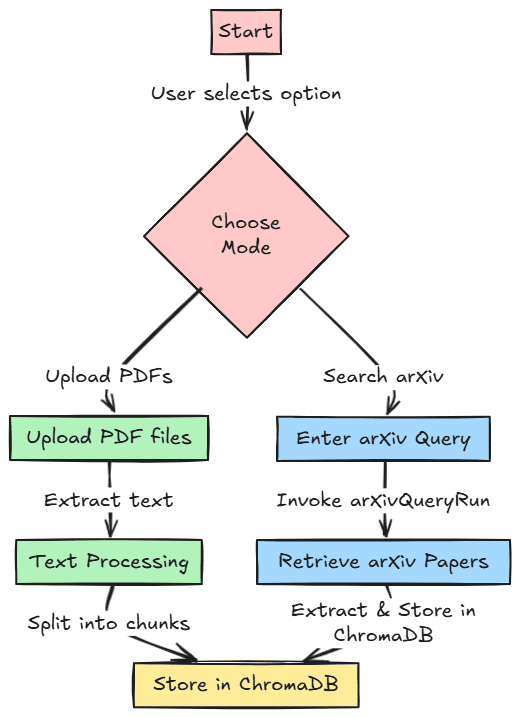
First, we must import all the required libraries and initiate all the environment variables we used for the project.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import os import PyPDF2 import streamlit as st from sentence_transformers import SentenceTransformer import chromadb from litellm import completion from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.tools import ArxivQueryRun from dotenv import load_dotenv
load_dotenv() gemini_api_key = os.getenv(“GEMINI_API_KEY”) huggingface_token = os.getenv(“HUGGINGFACE_TOKEN”)
if huggingface_token: login(token=huggingface_token)
client = chromadb.PersistentClient(path=“chroma_db”) text_embedding_model = SentenceTransformer(‘all-MiniLM-L6-v2’) arxiv_tool = ArxivQueryRun() |
After we import all the libraries and initiate the variables, we will create useful functions for our project.
Using the code below, we will create a function to extract text data from PDF files.
|
def extract_text_from_pdfs(uploaded_files): all_text = “” for uploaded_file in uploaded_files: reader = PyPDF2.PdfReader(uploaded_file) for page in reader.pages: all_text += page.extract_text() or “” return all_text |
Then, we develop a function to accept the previously extracted text and store it in the vector database. The function will also preprocess the raw text by splitting it into chunks.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def process_text_and_store(all_text): text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50, separators=[“\n\n”, “\n”, ” “, “”] ) chunks = text_splitter.split_text(all_text) try: client.delete_collection(name=“knowledge_base”) except Exception: pass
collection = client.create_collection(name=“knowledge_base”)
for i, chunk in enumerate(chunks): embedding = text_embedding_model.encode(chunk) collection.add( ids=[f“chunk_i”], embeddings=[embedding.tolist()], metadatas=[“source”: “pdf”, “chunk_id”: i], documents=[chunk] ) return collection |
Lastly, we prepare all the functions for retrieval with semantic search using embedding and generate the answer using the retrieved documents.
|
def semantic_search(query, collection, top_k=2): query_embedding = text_embedding_model.encode(query) results = collection.query( query_embeddings=[query_embedding.tolist()], n_results=top_k ) return results
def generate_response(query, context): prompt = f“Query: query\nContext: context\nAnswer:” response = completion( model=“gemini/gemini-1.5-flash”, messages=[“content”: prompt, “role”: “user”], api_key=gemini_api_key ) return response[‘choices’][0][‘message’][‘content’] |
We are now ready to build our RAG-powered research paper assistant. To develop the application, we will use Streamlit to build the front-end application, where we can choose whether to upload a PDF file or search arXiv directly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
def main(): st.title(“RAG-powered Research Paper Assistant”)
# Option to choose between PDF upload and arXiv search option = st.radio(“Choose an option:”, (“Upload PDFs”, “Search arXiv”))
if option == “Upload PDFs”: uploaded_files = st.file_uploader(“Upload PDF files”, accept_multiple_files=True, type=[“pdf”]) if uploaded_files: st.write(“Processing uploaded files…”) all_text = extract_text_from_pdfs(uploaded_files) collection = process_text_and_store(all_text) st.success(“PDF content processed and stored successfully!”)
query = st.text_input(“Enter your query:”) if st.button(“Execute Query”) and query: results = semantic_search(query, collection) context = “\n”.join(results[‘documents’][0]) response = generate_response(query, context) st.subheader(“Generated Response:”) st.write(response)
elif option == “Search arXiv”: query = st.text_input(“Enter your search query for arXiv:”)
if st.button(“Search ArXiv”) and query: arxiv_results = arxiv_tool.invoke(query) st.session_state[“arxiv_results”] = arxiv_results st.subheader(“Search Results:”) st.write(arxiv_results)
collection = process_text_and_store(arxiv_results) st.session_state[“collection”] = collection
st.success(“arXiv paper content processed and stored successfully!”)
# Only allow querying if search has been performed if “arxiv_results” in st.session_state and “collection” in st.session_state: query = st.text_input(“Ask a question about the paper:”) if st.button(“Execute Query on Paper”) and query: results = semantic_search(query, st.session_state[“collection”]) context = “\n”.join(results[‘documents’][0]) response = generate_response(query, context) st.subheader(“Generated Response:”) st.write(response) |
In the code above, you will note that our two features have been implemented. To start the application, we will use the following code.

You will see the above application in your web browser. To use the first feature, you can try uploading a PDF research paper file, and the application will process it.

If it’s a success, an alert will signify that the data have been processed and stored within the vector database.
Next, try to enter any query to ask something related to our research paper, and it will generate something like the following image.

The result is generated with the context we are given, as it references any of our documents.
Let’s try out the arXiv paper search feature. For example, here is how we search the paper about MLOps and a sample result.

If we about a paper we have previously searched, we will see something similar to the image below.

And that, my friends, is how we build a RAG-powered research paper assistant. You can tweak the code even further to have more specific features.
Conclusion
RAG is a generative AI technique that enhances the accuracy and relevance of responses by leveraging external knowledge sources. RAG can be used to build valuable applications, with one practical example being a RAG-powered research paper assistant.
In our adventure we have used Streamlit, LangChain, ChromaDB, the Gemini API, and HuggingFace models for embedding and text generation, which combined well to build our app, and we were able to upload our PDF files or search for papers directly on arXiv.
I hope this has helped!