
Long-context language models (LCLMs) have emerged as a promising technology with the potential to revolutionize artificial intelligence. These models aim to tackle complex tasks and applications while eliminating the need for intricate pipelines that were previously necessary due to context length limitations. However, the development and evaluation of LCLMs face significant challenges. Current evaluation methods rely on synthetic tasks or fixed-length datasets that fail to adequately assess the true capabilities of these models in real-world scenarios. The lack of rigorous benchmarks for truly long-context tasks hinders the ability to stress-test LCLMs on paradigm-shifting applications. Addressing these limitations is crucial for realizing the full potential of LCLMs and their impact on AI development.
Researchers have made several attempts to evaluate LCLMs, but each approach has limitations. While scalable, synthetic tasks like “Needle-in-A-Haystack” retrieval and multi-hop QA fail to capture the complexities of real-world scenarios. Other benchmarks using existing NLP datasets for extreme summarization and multi-document QA lack dynamic scaling capabilities, making them unsuitable for very long contexts. Instruction-following evaluations like LongAlpaca and LongBench-Chat offer limited task diversity and context lengths. Ada-LEval proposes a length-adaptable benchmark but relies on somewhat synthetic tasks. Studies on long-context QA using retrieved documents have shown promising results but are limited to contexts under 10,000 tokens. These existing methods fall short of comprehensively evaluating LCLMs on diverse, real-world tasks with truly long contexts, highlighting the need for more robust evaluation frameworks.
DeepMind Researchers introduce the Long-Context Frontiers (LOFT) to overcome the limitations of existing evaluation methods for LCLMs. LOFT comprises six tasks across 35 datasets, encompassing text, visual, and audio modalities. This comprehensive benchmark is designed to push LCLMs to their limits and assess their real-world impact. Unlike previous evaluations, LOFT allows for the automatic creation of increasing context lengths, currently extending to one million tokens with the potential for further expansion. The benchmark focuses on four key areas where LCLMs have disruptive potential: retrieval across multiple modalities, retrieval-augmented generation (RAG), SQL-free database querying, and many-shot in-context learning. By targeting these areas, LOFT aims to provide a rigorous and scalable evaluation framework that can keep pace with the evolving capabilities of LCLMs.
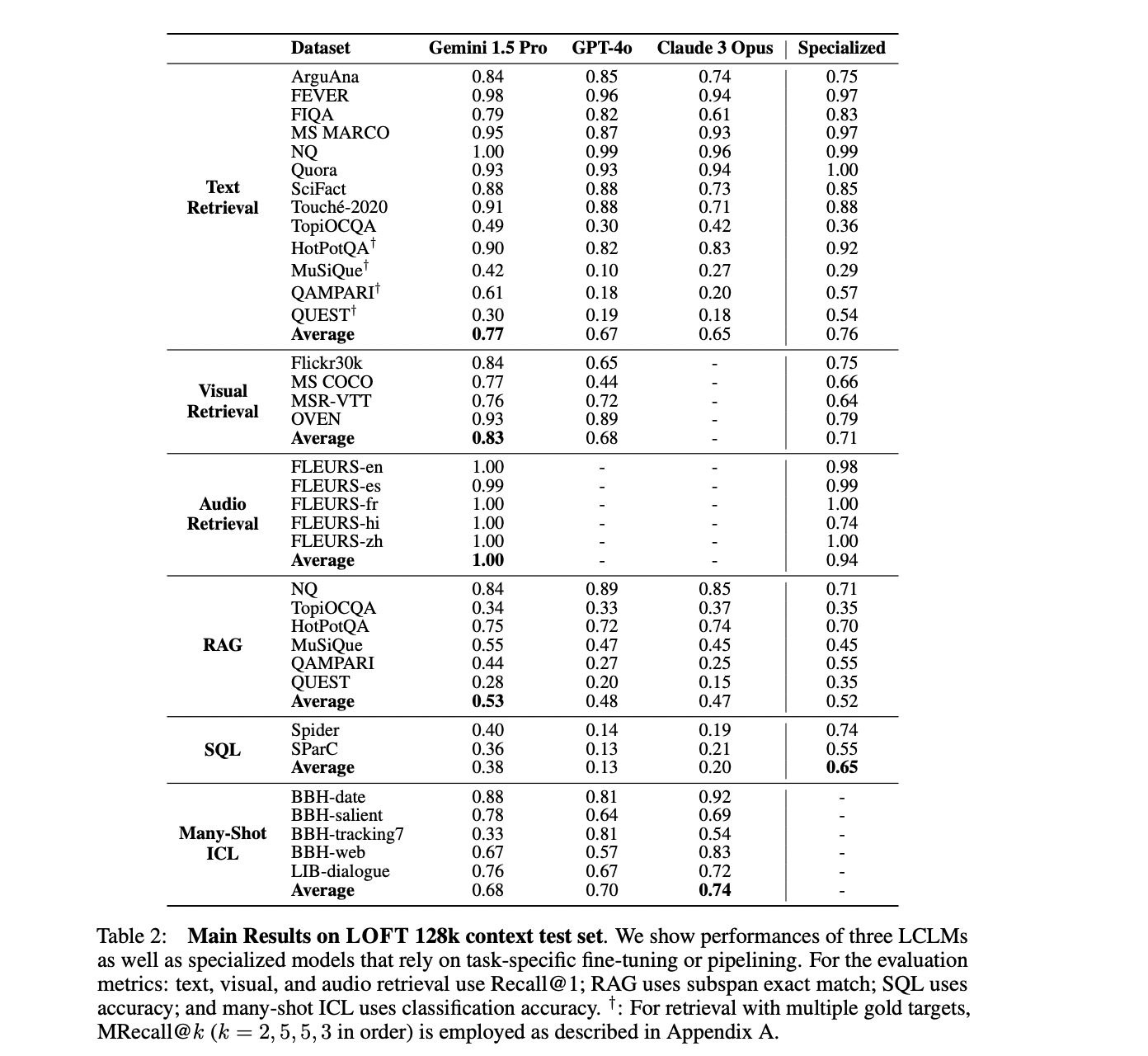
The LOFT benchmark encompasses a diverse range of real-world applications to evaluate LCLMs comprehensively. It features six main tasks: retrieval, RAG, SQL-like reasoning, and many-shot in-context learning (ICL), spanning 35 datasets across text, visual, and audio modalities. The benchmark is designed with three context length limits: 32k, 128k, and 1M tokens, with the potential to scale further. For retrieval and RAG tasks, LOFT creates shared corpora containing gold passages and random samples, ensuring smaller corpora are subsets of larger ones. Many-shot ICL tasks adapt datasets from Big-Bench Hard and LongICLBench, while SQL tasks use Spider and SparC datasets with associated databases. This structure allows for rigorous evaluation of LCLMs’ performance across various context lengths and task types.
The LOFT benchmark evaluates Gemini 1.5 Pro, GPT-4, and Claude 3 Opus across various tasks and context lengths. Gemini 1.5 Pro performs well in text retrieval, visual retrieval, and audio retrieval, often matching or exceeding specialized models. It excels in multi-hop RAG tasks but struggles with multi-target datasets at larger scales. SQL-like reasoning tasks show potential but require improvement. Many-shot ICL results vary, with Gemini 1.5 Pro and Claude 3 Opus performing strongly in different areas. The benchmark highlights LCLMs’ growing capabilities across diverse tasks and modalities, while also identifying areas for improvement, particularly in scaling to larger contexts and complex reasoning.
In this study LOFT benchmark has been introduced to assess the evolving capabilities of Large Context Language Models (LCLMs) as they scale to handle increasingly long contexts. LOFT comprises tasks designed to evaluate LCLMs on potential paradigm-shifting applications: retrieval, retrieval-augmented generation, SQL-like reasoning, and in-context learning. With dynamic scaling up to 1 million tokens and the potential to extend to 1 billion, LOFT ensures ongoing relevance as LCLMs advance. Initial results show LCLMs demonstrating competitive retrieval capabilities compared to specialized systems, despite lacking specific training. However, the benchmark also reveals significant room for improvement in long-context reasoning, particularly as models access even longer context windows.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.