
Large language models (LLMs) have revolutionized the field of AI with their ability to generate human-like text and perform complex reasoning. However, despite their capabilities, LLMs need help with tasks requiring domain-specific knowledge, especially in healthcare, law, and finance. When trained on large datasets, these models often miss critical information from specialized domains, leading to hallucinations or inaccurate responses. Enhancing LLMs with external data has been proposed as a solution to these limitations. By integrating relevant information, models become more precise and effective, significantly improving their performance. The Retrieval-Augmented Generation (RAG) technique is a prime example of this approach, allowing LLMs to retrieve necessary data during the generation process to provide more accurate and timely responses.
One of the most significant problems in deploying LLMs is their inability to handle queries that require specific and updated information. While LLMs are highly capable when dealing with general knowledge, they falter when tasked with specialized or time-sensitive queries. This shortfall occurs because most models are trained on static data, so they can only update their knowledge with external input. For example, in healthcare, a model that needs access to current medical guidelines will struggle to offer accurate advice, potentially putting lives at risk. Similarly, legal and financial systems require constant updates to keep up with changing regulations and market conditions. The challenge, therefore, lies in developing a model that can dynamically pull in relevant data to meet the specific needs of these domains.
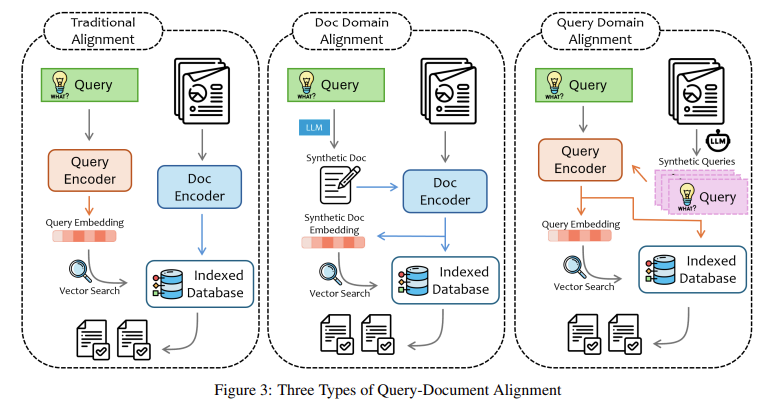
Current solutions, such as fine-tuning and RAG, have made strides in addressing these challenges. Fine-tuning allows a model to be retrained on domain-specific data, tailoring it for particular tasks. However, this approach is time-consuming and requires vast training data, which is only sometimes available. Moreover, fine-tuning often results in overfitting, where the model becomes too specialized and needs help with general queries. On the other hand, RAG offers a more flexible approach. Instead of relying solely on pre-trained knowledge, RAG enables models to retrieve external data in real-time, improving their accuracy and relevance. Despite its advantages, RAG still needs several challenges, such as the difficulty of processing unstructured data, which can come in various forms like text, images, and tables.
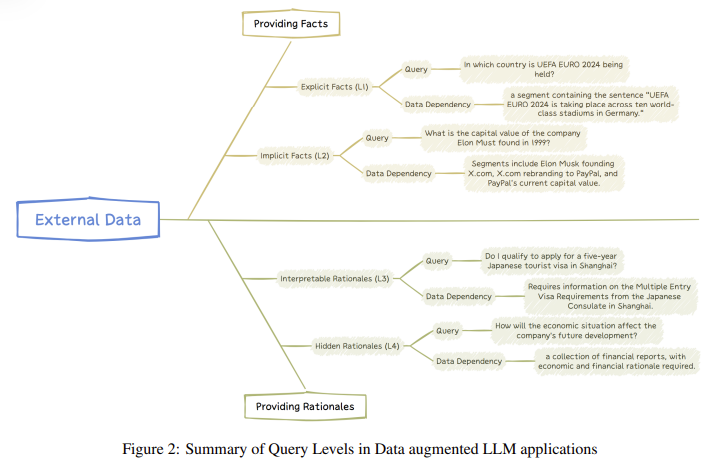
Researchers at Microsoft Research Asia introduced a novel method that categorizes user queries into four distinct levels based on the complexity and type of external data required. These levels are explicit facts, implicit facts, interpretable rationales, and hidden rationales. The categorization helps tailor the model’s approach to retrieving and processing data, ensuring it selects the most relevant information for a given task. For example, explicit fact queries involve straightforward questions, such as “What is the capital of France?” where the answer can be retrieved from external data. Implicit fact queries require more reasoning, such as combining multiple pieces of information to infer a conclusion. Interpretable rationale queries involve domain-specific guidelines, while hidden rationale queries require deep reasoning and often deal with abstract concepts.
The method proposed by Microsoft Research enables LLMs to differentiate between these query types and apply the appropriate level of reasoning. For instance, in the case of hidden rationale queries, where no clear answer exists, the model could infer patterns and use domain-specific reasoning methods to generate a response. By breaking down queries into these categories, the model becomes more efficient at retrieving the necessary information and providing accurate, context-driven responses. This categorization also helps reduce the computational load on the model, as it can now focus on retrieving only the data relevant to the query type rather than scanning vast amounts of unrelated information.
The study also highlights the impressive results of this approach. The system significantly improved performance in specialized domains like healthcare and legal analysis. For instance, in healthcare applications, the model reduced the rate of hallucinations by up to 40%, providing more grounded and reliable responses. The model’s accuracy in processing complex documents and offering detailed analysis increased by 35% in legal systems. Overall, the proposed method allowed for more accurate retrieval of relevant data, leading to better decision-making and more reliable outputs. The study found that RAG-based systems reduced hallucination incidents by grounding the model’s responses in verifiable data, improving accuracy in critical applications such as medical diagnostics and legal document processing.

In conclusion, this research provides a crucial solution to one of the fundamental problems in deploying LLMs in specialized domains. By introducing a system that categorizes queries based on complexity and type, the researchers at Microsoft Research have developed a method that enhances the accuracy and interpretability of LLM outputs. This framework enables LLMs to retrieve the most relevant external data and apply it effectively to domain-specific queries, reducing hallucinations and improving overall performance. The study demonstrated that using structured query categorization can improve results by up to 40%, making this a significant step forward in AI-powered systems. By addressing both the problem of data retrieval and the integration of external knowledge, this research paves the way for more reliable and robust LLM applications across various industries.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.