
Multimodal large language models (MLLMs) bridge vision and language, enabling effective interpretation of visual content. However, achieving precise and scalable region-level comprehension for static images and dynamic videos remains challenging. Temporal inconsistencies, scaling inefficiencies, and limited video comprehension hinder progress, particularly in maintaining consistent object and region representations across video frames. Temporal drift, caused by motion, scaling, or perspective changes, coupled with reliance on computationally heavy methods like bounding boxes or Region of Interest (RoI)-aligned features, increases complexity and limits real-time and large-scale video analysis.
Recent strategies, such as textual region coordinates, visual markers, and RoI-based features, have attempted to address these issues. However, they often fail to ensure temporal consistency across frames or efficiently process large datasets. Bounding boxes lack robustness for multi-frame tracking, and static frame analysis misses intricate temporal relationships. While innovations like embedding coordinates into textual prompts and using image-based markers have advanced the field, a unified solution for image and video domains remains out of reach.
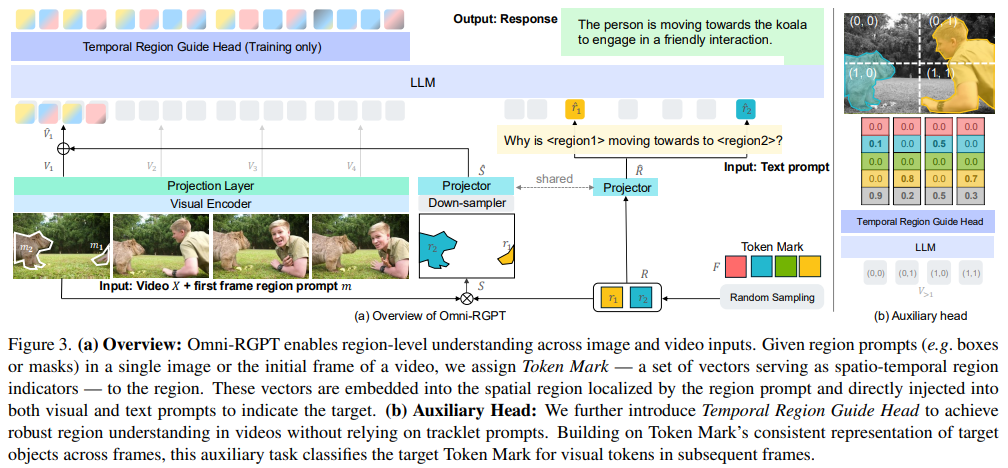
Researchers from NVIDIA and Yonsei University developed Omni-RGPT, a novel multimodal large language model designed to achieve seamless region-level comprehension in images and videos to address these challenges. This model introduces Token Mark, a groundbreaking method that embeds region-specific tokens into visual and text prompts, establishing a unified connection between the two modalities. The Token Mark system replaces traditional RoI-based approaches by defining a unique token for each target region, which remains consistent across frames in a video. This strategy prevents temporal drift and reduces computational costs, enabling robust reasoning for static and dynamic inputs. Including a Temporal Region Guide Head further enhances the model’s performance on video data by classifying visual tokens to avoid reliance on complex tracking mechanisms.
Omni-RGPT leverages a newly created large-scale dataset called RegVID-300k, which contains 98,000 unique videos, 214,000 annotated regions, and 294,000 region-level instruction samples. This dataset was constructed by combining data from ten public video datasets, offering diverse and fine-grained instructions for region-specific tasks. The dataset supports visual commonsense reasoning, region-based captioning, and referring expression comprehension. Unlike other datasets, RegVID-300k includes detailed captions with temporal context and mitigates visual hallucinations through advanced validation techniques.
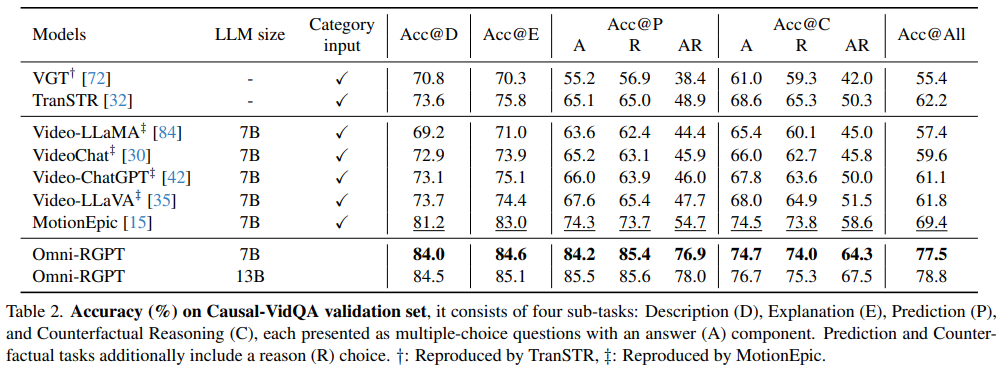
Omni-RGPT achieved state-of-the-art results on several benchmarks, including 84.5% accuracy on the Causal-VidQA dataset, which evaluates temporal and spatial reasoning across video sequences. The model outperformed existing methods like MotionEpic by over 5% in some sub-tasks, demonstrating superior performance in prediction and counterfactual reasoning. Similarly, the model excelled in video captioning tasks, achieving high METEOR scores on challenging datasets like Vid-STG and BenSMOT. The model achieved remarkable accuracy for image-based tasks on the Visual Commonsense Reasoning (VCR) dataset, outperforming methods specifically optimized for image domains.

Several key takeaways from the research on Omni-RGPT include:
- This approach enables consistent and scalable region-level understanding by embedding predefined tokens into visual and text inputs. This prevents temporal drift and supports seamless reasoning across frames.
- The dataset provides detailed, fine-grained, diverse annotations, enabling the model to excel in complex video tasks. It includes 294,000 region-level instructions and addresses gaps in existing datasets.
- Omni-RGPT demonstrated superior performance across benchmarks such as Causal-VidQA and VCR, achieving accuracy improvements of up to 5% compared to leading models.
- The model’s design reduces computational overhead by avoiding dependency on bounding box coordinates or full video tracklets, making it suitable for real-world applications.
- The framework seamlessly integrates image and video tasks under a single architecture, achieving exceptional performance without compromising efficiency.
In conclusion, Omni-RGPT addresses critical challenges in region-specific multimodal learning by introducing Token Mark and a novel dataset to support detAIled comprehension in images and videos. The model’s scalable design and state-of-the-art performance across diverse tasks set a new benchmark for the field. Omni-RGPT provides a robust foundation for future research and practical applications in AI by eliminating temporal drift, reducing computational complexity, and leveraging large-scale data.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
🚨 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.