
Information retrieval (IR) models face significant challenges in delivering transparent and intuitive search experiences. Current methodologies primarily rely on a single semantic similarity score to match queries with passages, leading to a potentially opaque user experience. This approach often requires users to engage in a cumbersome process of finding specific keywords, applying various filters in advanced search settings, and iteratively refining their queries based on previous search results. The need for users to craft the “just right” query to retrieve desired passages highlights the limitations of existing IR systems in providing efficient and user-friendly search capabilities.
Recent developments in IR models have introduced the use of instructions, moving beyond traditional dense retriever training that focused on similarity functions akin to phrase-level matching. Early efforts like TART and Instructor incorporated simple task prefixes during training. More recent models such as E5-Mistral, GritLM, and NV-Retriever have expanded on this approach by scaling up both dataset and model sizes. These newer models typically adopt the instruction set proposed by E5-Mistral. However, while these advancements represent progress in the field, they still primarily rely on a single instruction set and do not fully address the challenges of providing users with a more transparent and flexible search experience.
Researchers from Johns Hopkins University and Samaya AI have introduced Promptriever, a unique approach to information retrieval that enables control through natural language prompts. This model allows users to dynamically adjust relevance criteria using conversational descriptions, eliminating the need for multiple searches or complex filters. For instance, when searching for James Cameron movies, users can simply specify criteria like “Relevant documents are not codirected and are created before 2022.” Promptriever is built on a bi-encoder retriever architecture, utilizing large language models such as LLaMA-2 7B as its backbone. While pre-trained language models can adapt to natural language instructions, traditional IR training often compromises this capability by focusing solely on optimizing query-passage semantic similarity scores. Promptriever addresses this limitation, maintaining instruction-following capacity post-IR training.
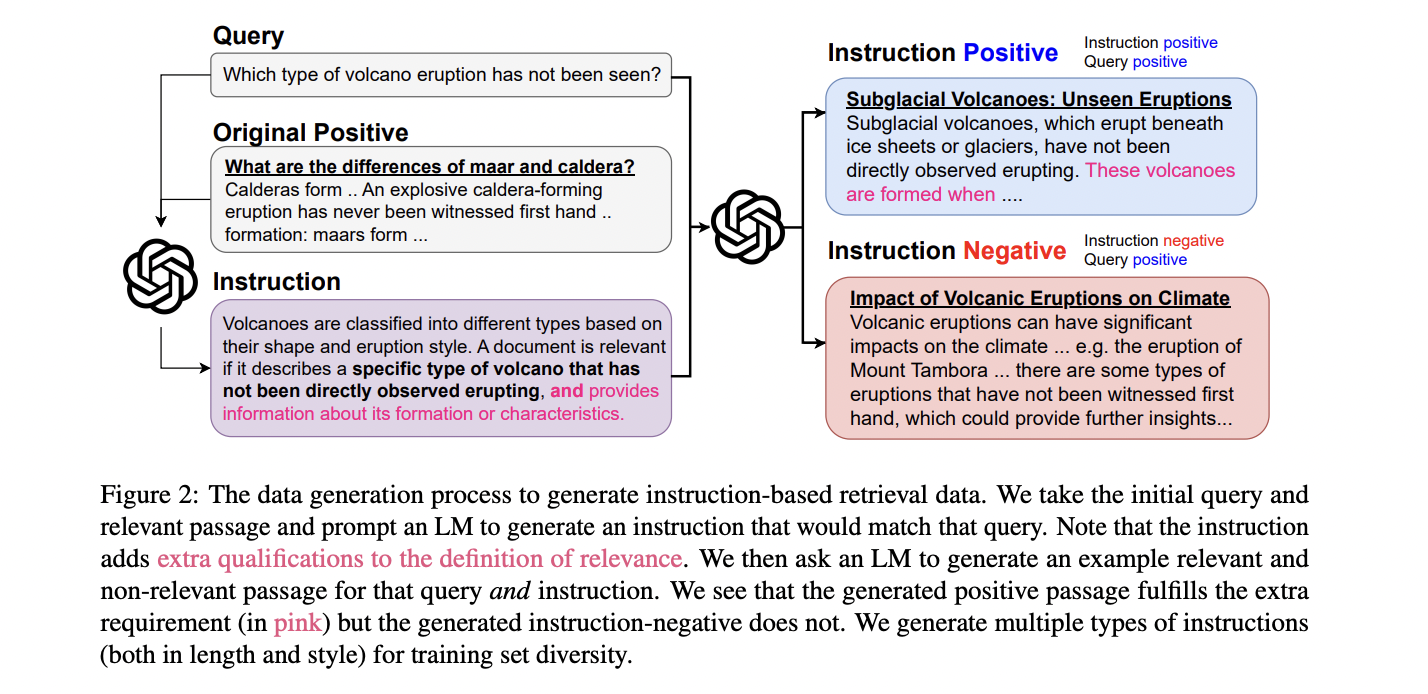
Promptriever utilizes a two-part data generation process to train its bi-encoder for instruction-based retrieval. The model builds upon the MS MARCO dataset, using the tevatron-msmarco-aug version with hard negatives. The first step involves instruction generation, where Llama-3-70B-Instruct creates diverse, specific instructions for each query, varying in length and style. These instructions maintain relevance to the original positive passages, as verified by FollowIR-7B.
The second step, instruction-negative mining, introduces passages that are query-positive but instruction-negative. This process encourages the model to consider both query and instruction during training. GPT-4 generates these passages, which are then filtered using FollowIR-7B to ensure accuracy. Human validation confirms the effectiveness of this filtering process, with the model-human agreement reaching 84%.
This comprehensive data augmentation approach enables Promptriever to adapt its relevance criteria dynamically based on natural language instructions, significantly enhancing its retrieval capabilities compared to traditional IR models.
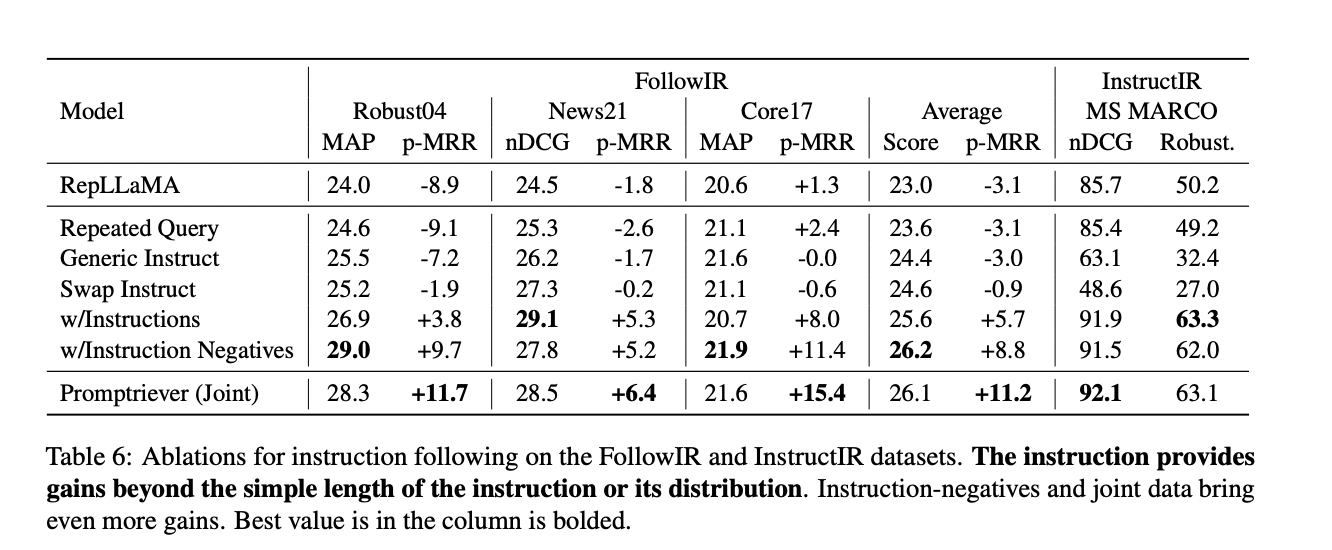
Promptriever demonstrates superior performance in instruction following while maintaining strong standard retrieval capabilities. It outperforms the original RepLLaMA by a significant margin, with improvements of +14.3 p-MRR and +3.1 in nDCG/MAP, establishing itself as the highest-performing dense retriever. While cross-encoder models achieve the best results due to their computational advantage, Promptriever’s performance as a bi-encoder model is comparable and more efficient.
In standard retrieval tasks without instructions, Promptriever performs on par with RepLLaMA for in-domain tasks (MS MARCO) and out-of-domain tasks (BEIR). Also, Promptriever exhibits 44% less variance to prompts compared to RepLLaMA and 77% less than BM25, indicating higher robustness to input variations. These results underscore the effectiveness of Promptriever’s instruction-based approach in enhancing both retrieval accuracy and adaptability to diverse queries.
This study presents Promptriever, a significant advancement in information retrieval, introducing the first zero-shot promptable retriever. Developed using a unique instruction-based dataset derived from MS MARCO, this model demonstrates superior performance in both standard retrieval tasks and instruction following. By adapting its relevance criteria dynamically based on per-query instructions, Promptriever showcases the successful application of prompting techniques from language models to dense retrievers. This innovation paves the way for more flexible and user-friendly information retrieval systems, bridging the gap between natural language processing and efficient search capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 52k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.