
Controlling the language proficiency levels in texts generated by large language models (LLMs) is a significant challenge in AI research. Ensuring that generated content is appropriate for various proficiency levels is crucial for applications in language learning, education, and other contexts where users may not be fully proficient in the target language. Without effective proficiency control, the usability and effectiveness of LLM-generated content are significantly hindered, especially for non-native speakers, children, and language learners.
Current methods to tackle this challenge include few-shot prompting, supervised finetuning, and reinforcement learning (RL). Few-shot prompting involves providing the model with a few examples to guide its output, while supervised finetuning adjusts the model using a labeled dataset. RL, specifically Proximal Policy Optimization (PPO), further refined the model’s outputs based on a reward system. However, these methods have limitations: few-shot prompting with open-source models often results in high computational costs and suboptimal performance, and supervised fine-tuning requires extensive labeled data, which may not be readily available. Moreover, RL techniques can be unstable and computationally intensive, making them less practical for large-scale applications.
A team of researchers from Stanford and Duolingo propose developing the CEFR-Aligned Language Model (CALM), which combines finetuning and PPO to align the output proficiency levels with the Common European Framework of Reference for Languages (CEFR) standards. This approach specifically addresses the limitations of existing methods by bridging the performance gap between proprietary models like GPT-4 and open-source alternatives. CALM is designed to generate high-quality, proficiency-controlled content at a fraction of the cost of using proprietary models. This represents a significant contribution to the field by making proficiency-controlled text generation more accessible and cost-effective.
The proposed method involves finetuning open-source models such as LLama-2-7B and Mistral-7B using a dataset generated by effective GPT-4 prompting strategies. The dataset, called TinyTolkien, consists of short stories with varying CEFR levels. Further training with PPO aligns the model outputs with the desired proficiency levels. Additionally, a sampling strategy was introduced to boost model performance by selecting the best output from multiple generations. The technical aspects crucial for understanding this approach include the use of linguistic features for automated CEFR scoring and the application of RL techniques to minimize ControlError, which measures the deviation of the generated text from the target proficiency level.
The results demonstrate that the proposed CALM model achieves a ControlError comparable to GPT-4 while significantly reducing costs. Evaluation metrics included ControlError, QualityScore, and computational cost. The findings were validated through both automatic scoring and a small-scale human study, which showed high ratings for quality and proficiency alignment. The key table below compares various prompting strategies and models, highlighting CALM’s superior performance in both ControlError and quality metrics. For instance, CALM with top-3 sampling achieved a ControlError of 0.15, outperforming other models and strategies.
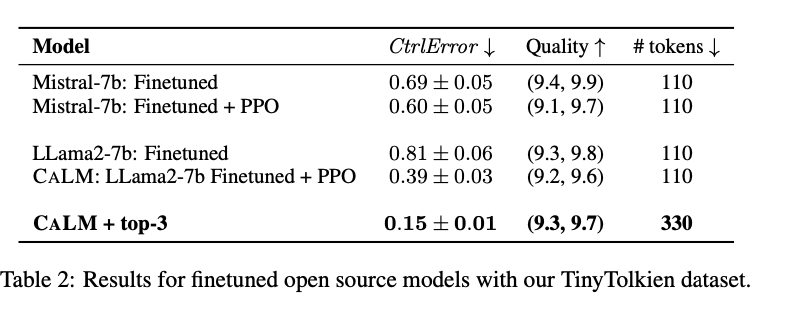
In conclusion, the researchers addressed the critical challenge of controlling the proficiency level of LLM-generated content. They proposed a novel approach combining finetuning and PPO, validated through rigorous evaluation, which significantly advances the field by providing an efficient, cost-effective solution for generating proficiency-controlled text. This work has the potential to enhance applications in education and language learning, making advanced AI tools more accessible to a broader audience.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
![]()
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.