
Outliers are unique in that they often don’t play by the rules. These data points, which significantly differ from the rest, can skew your analyses and make your predictive models less accurate. Although detecting outliers is critical, there is no universally agreed-upon method for doing so. While some advanced techniques like machine learning offer solutions, in this post, we will focus on the foundational Data Science methods that have been in use for decades.
Let’s get started.
Spotting the Exception: Classical Methods for Outlier Detection in Data Science
Photo by Haley Truong. Some rights reserved.
Overview
This post is divided into three parts; they are:
- Understanding Outliers and Their Impact
- Traditional Methods for Outlier Detection
- Detecting Outliers in the Ames Dataset
Understanding Outliers and Their Impact
Outliers can emerge for a variety of reasons, from data entry errors to genuine anomalies. Their presence can be attributed to factors like:
- Measurement errors
- Data processing errors
- Genuine extreme observations
Understanding the source of an outlier is crucial for determining whether to keep, modify, or discard it. The impact of outliers on statistical analyses can be profound. They can change the results of data visualizations, central tendency measurements, and other statistical tests. Outliers can also influence the assumptions of normality, linearity, and homoscedasticity in a dataset, leading to unreliable and spurious conclusions.
Kick-start your project with my book The Beginner’s Guide to Data Science. It provides self-study tutorials with working code.
Traditional Methods for Outlier Detection
In the realm of Data Science, several classical methods exist for detecting outliers. These can be broadly categorized into:
- Visual methods: Plots and graphs, such as scatter plots, box plots, and histograms, provide an intuitive feel of the data distribution and any extreme values.
- Statistical methods: Techniques like the Z-score, IQR (Interquartile Range), and the modified Z-score are mathematical methods used to define outliers based on data distribution.
- Probabilistic and statistical models: These leverage the probability distribution of data, such as the Gaussian distribution, to detect unlikely observations.
It’s essential to understand that the choice of method often depends on the nature of your dataset and the specific problem at hand.
Detecting Outliers in the Ames Dataset
In this section, you’ll dive into the practical application of detecting outliers using the Ames Housing Dataset. Specifically, you’ll explore three features: Lot Area, Sales Price, and Total Rooms Above Ground.
Visual Inspection
Visual methods are a quick and intuitive way to identify outliers. Let’s start with box plots for your chosen features.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Import the necessary libraries & load the dataset import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
Ames = pd.read_csv(‘Ames.csv’)
# Define feature names in full form for titles and axis feature_names_full = { ‘LotArea’: ‘Lot Area (sq ft)’, ‘SalePrice’: ‘Sales Price (US$)’, ‘TotRmsAbvGrd’: ‘Total Rooms Above Ground’ }
plt.figure(figsize=(18, 6)) features = [‘LotArea’, ‘SalePrice’, ‘TotRmsAbvGrd’]
for i, feature in enumerate(features, 1): plt.subplot(1, 3, i) sns.boxplot(y=Ames[feature], color=“lightblue”) plt.title(feature_names_full[feature], fontsize=16) plt.ylabel(feature_names_full[feature], fontsize=14) plt.xlabel(”) # Removing the x-axis label as it’s not needed
plt.tight_layout() plt.show() |
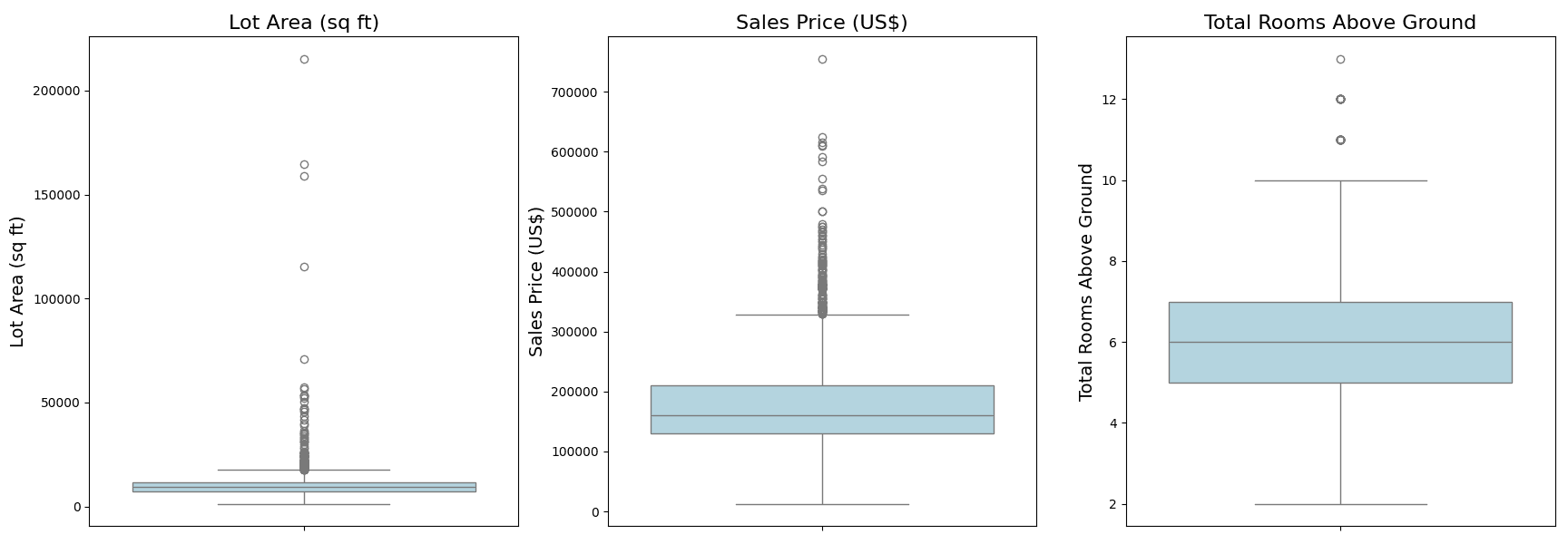
These plots provide immediate insights into potential outliers in your data. The dots you see beyond the whiskers represent data points that are considered outliers, lying outside 1.5 times the Interquartile Range (IQR) from the first and third quartiles. For instance, you might notice properties with exceptionally large lot areas or homes with a large number of rooms above ground.
Statistical Methods: IQR
The dots in the box plots above are greater than 1.5 times the Interquartile Range (IQR) from the third quartiles. It is a robust method to quantitatively identify outliers. You can precisely find and count these dots from the pandas DataFrame without the box plot:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
def detect_outliers_iqr_summary(dataframe, features): outliers_summary = {}
for feature in features: data = dataframe[feature] Q1 = data.quantile(0.25) Q3 = data.quantile(0.75) IQR = Q3 – Q1 lower_bound = Q1 – 1.5 * IQR upper_bound = Q3 + 1.5 * IQR outliers = data[(data < lower_bound) | (data > upper_bound)] outliers_summary[feature] = len(outliers)
return outliers_summary
outliers_summary = detect_outliers_iqr_summary(Ames, features) print(outliers_summary) |
This prints:
|
{‘LotArea’: 113, ‘SalePrice’: 116, ‘TotRmsAbvGrd’: 35} |
In your analysis of the Ames Housing Dataset using the Interquartile Range (IQR) method, you identified 113 outliers in the “Lot Area” feature, 116 outliers in the “Sales Price” feature, and 35 outliers for the “Total Rooms Above Ground” feature. These outliers are visually represented as dots beyond the whiskers in the box plots. The whiskers of the box plots typically extend up to 1.5 times the IQR from the first and third quartiles, and data points beyond these whiskers are considered outliers. This is just one definition of outliers. Such values should be further investigated or treated appropriately in subsequent analyses.
Probabilistic and Statistical Models
The natural distribution of data can sometimes help you identify outliers. One of the most common assumptions about data distribution is that it follows a Gaussian (or normal) distribution. In a perfectly Gaussian distribution, about 68% of the data lies within one standard deviation from the mean, 95% within two standard deviations, and 99.7% within three standard deviations. Data points that fall far away from the mean (typically beyond three standard deviations) can be considered outliers.
This method is particularly effective when the dataset is large and is believed to be normally distributed. Let’s apply this technique to your Ames Housing Dataset and see what you find.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# Define a function to detect outliers using the Gaussian model def detect_outliers_gaussian(dataframe, features, threshold=3): outliers_summary = {}
for feature in features: data = dataframe[feature] mean = data.mean() std_dev = data.std() outliers = data[(data < mean – threshold * std_dev) | (data > mean + threshold * std_dev)] outliers_summary[feature] = len(outliers)
# Visualization plt.figure(figsize=(12, 6)) sns.histplot(data, color=“lightblue”) plt.axvline(mean, color=‘r’, linestyle=‘-‘, label=f‘Mean: {mean:.2f}’) plt.axvline(mean – threshold * std_dev, color=‘y’, linestyle=‘–‘, label=f‘—{threshold} std devs’) plt.axvline(mean + threshold * std_dev, color=‘g’, linestyle=‘–‘, label=f‘+{threshold} std devs’)
# Annotate upper 3rd std dev value annotate_text = f‘{mean + threshold * std_dev:.2f}’ plt.annotate(annotate_text, xy=(mean + threshold * std_dev, 0), xytext=(mean + (threshold + 1.45) * std_dev, 50), arrowprops=dict(facecolor=‘black’, arrowstyle=‘wedge,tail_width=0.7’), fontsize=12, ha=‘center’)
plt.title(f‘Distribution of {feature_names_full[feature]} with Outliers’, fontsize=16) plt.xlabel(feature_names_full[feature], fontsize=14) plt.ylabel(‘Frequency’, fontsize=14) plt.legend() plt.show()
return outliers_summary
outliers_gaussian_summary = detect_outliers_gaussian(Ames, features) print(outliers_gaussian_summary) |
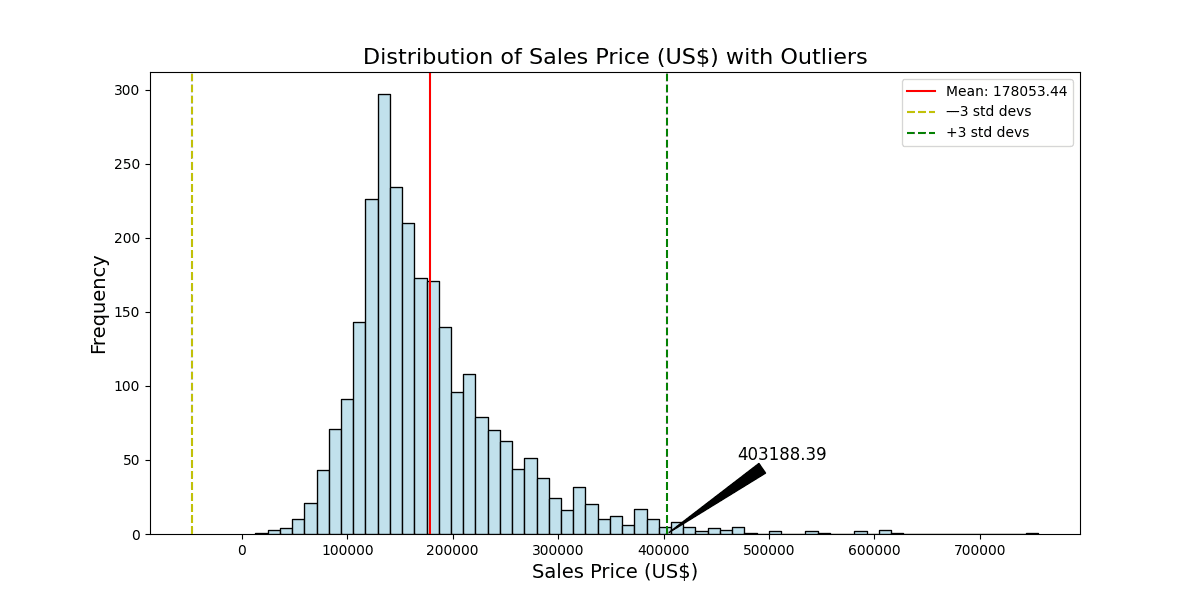
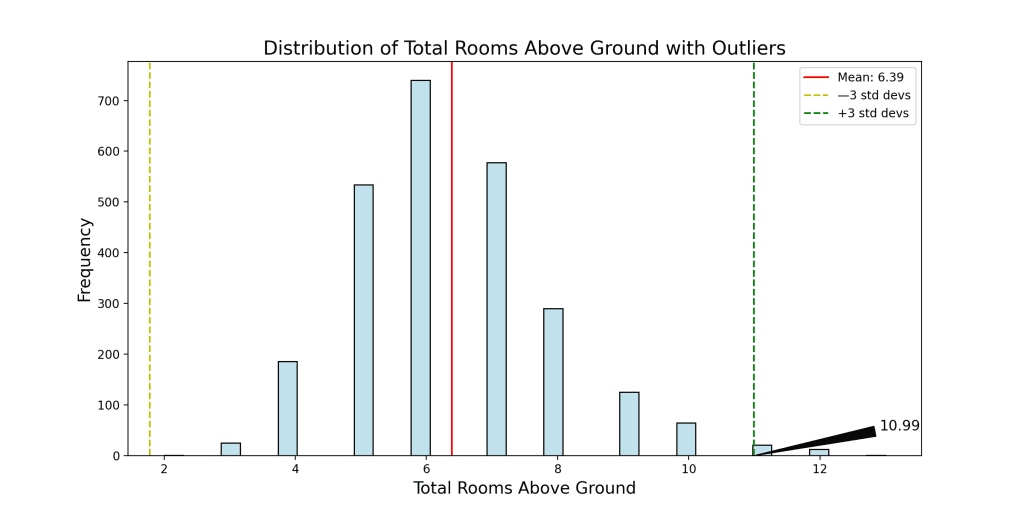
This shows these charts of distribution: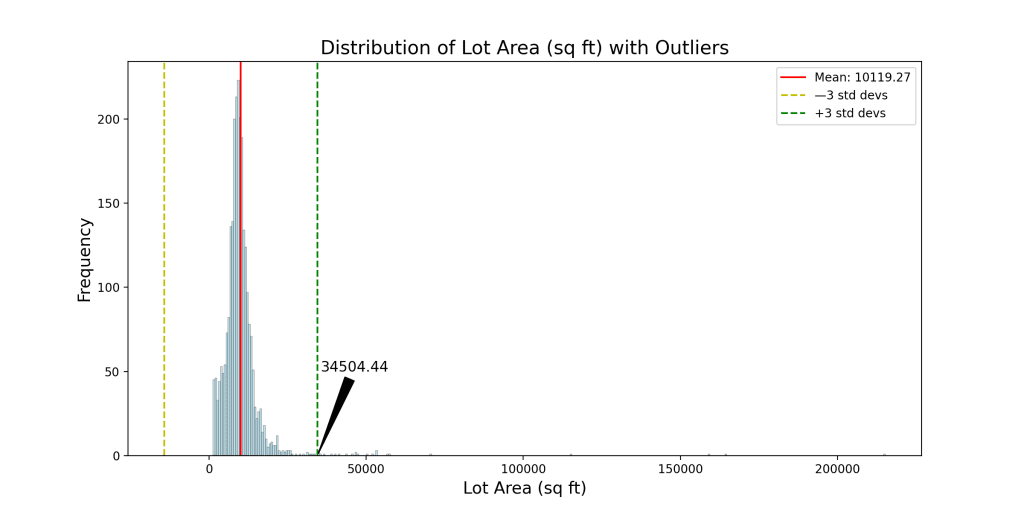
 Then it prints the following:
Then it prints the following:
|
{‘LotArea’: 24, ‘SalePrice’: 42, ‘TotRmsAbvGrd’: 35} |
Upon applying the Gaussian model for outlier detection, you observed that there are outliers in the “Lot Area,” “Sales Price,” and “Total Rooms Above Ground” features. These outliers are identified based on the upper threshold of three standard deviations from the mean:
- Lot Area: Any observation with a lot area larger than 34,505.44 square feet is considered an outlier. You found 24 such outliers in the dataset.
- Sales Price: Any observation above US$403,188.39 is considered an outlier. Your analysis revealed 42 outliers in the “Sales Price” feature.
- Total Rooms Above Ground: Observations with more than 10.99 rooms above ground are considered outliers. You identified 35 outliers using this criterion.
The number of outliers is different because the definition of outliers is different. These figures differ from your earlier IQR method, emphasizing the importance of utilizing multiple techniques for a more comprehensive understanding. The visualizations accentuate these outliers, allowing for a clear distinction from the main distribution of the data. Such discrepancies underscore the necessity of domain expertise and context when deciding on the best approach for outlier management.
To enhance your understanding and facilitate further analysis, it’s valuable to compile a comprehensive list of identified outliers. This list provides a clear overview of the specific data points that deviate significantly from the norm. In the following section, you’ll illustrate how to systematically organize and list these outliers into a DataFrame for each feature: “Lot Area,” “Sales Price,” and “Total Rooms Above Ground.” This tabulated format allows for easy inspection and potential actions, such as further investigation or targeted data treatment.
Let’s explore the approach that accomplishes this task.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# Define a function to tabulate outliers into a DataFrame def create_outliers_dataframes_gaussian(dataframe, features, threshold=3, num_rows=None): outliers_dataframes = {}
for feature in features: data = dataframe[feature] mean = data.mean() std_dev = data.std() outliers = data[(data < mean – threshold * std_dev) | (data > mean + threshold * std_dev)]
# Create a new DataFrame for outliers of the current feature outliers_df = dataframe.loc[outliers.index, [feature]].copy() outliers_df.rename(columns={feature: ‘Outlier Value’}, inplace=True) outliers_df[‘Feature’] = feature outliers_df.reset_index(inplace=True)
# Display specified number of rows (default: full dataframe) outliers_df = outliers_df.head(num_rows) if num_rows is not None else outliers_df
outliers_dataframes[feature] = outliers_df
return outliers_dataframes
# Example usage with user-defined number of rows = 7 outliers_gaussian_dataframes = create_outliers_dataframes_gaussian(Ames, features, num_rows=7)
# Print each DataFrame with the original format and capitalized ‘index’ for feature, df in outliers_gaussian_dataframes.items(): df_reset = df.reset_index().rename(columns={‘index’: ‘Index’}) print(f“Outliers for {feature}:\n”, df_reset[[‘Index’, ‘Feature’, ‘Outlier Value’]]) print() |
Now, before you unveil the results, it’s essential to note that the code snippet allows for user customization. By adjusting the parameter num_rows, you have the flexibility to define the number of rows you want to see in each DataFrame. In the example shared earlier, you used num_rows=7 for a concise display, but the default setting is num_rows=None, which prints the entire DataFrame. Feel free to tailor this parameter to suit your preferences and the specific requirements of your analysis.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
Outliers for LotArea: Index Feature Outlier Value 0 104 LotArea 53107 1 195 LotArea 53227 2 249 LotArea 159000 3 309 LotArea 40094 4 329 LotArea 45600 5 347 LotArea 50271 6 355 LotArea 215245
Outliers for SalePrice: Index Feature Outlier Value 0 29 SalePrice 450000 1 65 SalePrice 615000 2 103 SalePrice 468000 3 108 SalePrice 500067 4 124 SalePrice 475000 5 173 SalePrice 423000 6 214 SalePrice 500000
Outliers for TotRmsAbvGrd: Index Feature Outlier Value 0 50 TotRmsAbvGrd 12 1 165 TotRmsAbvGrd 11 2 244 TotRmsAbvGrd 11 3 309 TotRmsAbvGrd 11 4 407 TotRmsAbvGrd 11 5 424 TotRmsAbvGrd 13 6 524 TotRmsAbvGrd 11 |
In this exploration of probabilistic and statistical models for outlier detection, you focused on the Gaussian model applied to the Ames Housing Dataset, specifically utilizing a threshold of three standard deviations. By leveraging the insights provided by visualizations and statistical methods, you identified outliers and demonstrated their listing in a customizable DataFrame.
Further Reading
Resources
Summary
Outliers, stemming from diverse causes, significantly impact statistical analyses. Recognizing their origins is crucial as they can distort visualizations, central tendency measures, and statistical tests. Classical Data Science methods for outlier detection encompass visual, statistical, and probabilistic approaches, with the choice dependent on dataset nature and specific problems.
Application of these methods on the Ames Housing Dataset, focusing on Lot Area, Sales Price, and Total Rooms Above Ground, revealed insights. Visual methods like box plots provided quick outlier identification. The Interquartile Range (IQR) method quantified outliers, revealing 113, 116, and 35 outliers for Lot Area, Sales Price, and Total Rooms Above Ground. Probabilistic models, particularly the Gaussian model with three standard deviations, found 24, 42, and 35 outliers in the respective features.
These results underscore the need for a multifaceted approach to outlier detection. Beyond identification, systematically organizing and listing outliers in tabulated DataFrames facilitates in-depth inspection. Customizability, demonstrated by the num_rows parameter, ensures flexibility in presenting tailored results. In conclusion, this exploration enhances understanding and provides practical guidance for managing outliers in real-world datasets.
Specifically, you learned:
- The significance of outliers and their potential impact on data analyses.
- Various traditional methods are used in Data Science for outlier detection.
- How to apply these methods in a real-world dataset, using the Ames Housing Dataset as an example.
- Systematic organization and listing of identified outliers into customizable DataFrames for detailed inspection and further analysis.
Do you have any questions? Please ask your questions in the comments below, and I will do my best to answer.
Get Started on The Beginner’s Guide to Data Science!

Learn the mindset to become successful in data science projects
…using only minimal math and statistics, acquire your skill through short examples in Python
Discover how in my new Ebook:
The Beginner’s Guide to Data Science
It provides self-study tutorials with all working code in Python to turn you from a novice to an expert. It shows you how to find outliers, confirm the normality of data, find correlated features, handle skewness, check hypotheses, and much more…all to support you in creating a narrative from a dataset.
Kick-start your data science journey with hands-on exercises
See What’s Inside