
Image by Author | Canva
The STAR method — Situation, Task, Action, Result — is often a recommended framework for answering behavioral interview questions.
There are several problems with that.
First, I instantly dislike anything that is a must-use for answering interview questions. Curiously, promoted by the same hiring managers who are supposedly championing different personalities and individual quirks.
Showing individuality by doing exactly the same thing as everyone else? Yeah, no, it doesn’t work that way.

Source: Reddit
Another problem is that STAR doesn’t work for technical roles like data science. Yes, STAR is intended for answering behavioral questions. However, in data science, the technical aspect still seeps into your ‘behavior’. There really is no point in using STAR to show how calm you stay under the pressure of choosing the ML model if the model you choose is entirely wrong. Calmly making disastrous mistakes, I’m not sure companies are after that.
Data science is all about the Holy Trinity (keeping with the mood set by the meme above):
- Messiness: If the problem weren’t messy, you wouldn’t be called to solve it!
- Thinking: If the answer was obvious, they’d have used a spreadsheet and moved on!
- Metrics: If you can’t measure it, how will you make a decision and take credit for it later?
That necessitates your answers to touch on issues such as:
- How did you navigate the ambiguity of messy problems, data, and model limitations?
- Why did you apply that analysis and those tools? Why and how did you choose your model?
- What metrics did you track, and what impact did your model achieve?
Without this, for all we know, the same answer could be given by a project manager, a sales associate, or even someone from HR.
Using STAR doesn’t help you in making technical distinctions. It encourages storytelling, not problem-solving. It hides your thinking and skips talking about the impact. On top of that, it encourages robotic and uniform answers, which takes us to the first problem.
So, let me give you some tips on answering behavioral questions without STAR.
Tips for Answering Behavioral Questions – The Data Scientist Way
Here are some tips to keep you on the course of answering interview questions as a data scientist.
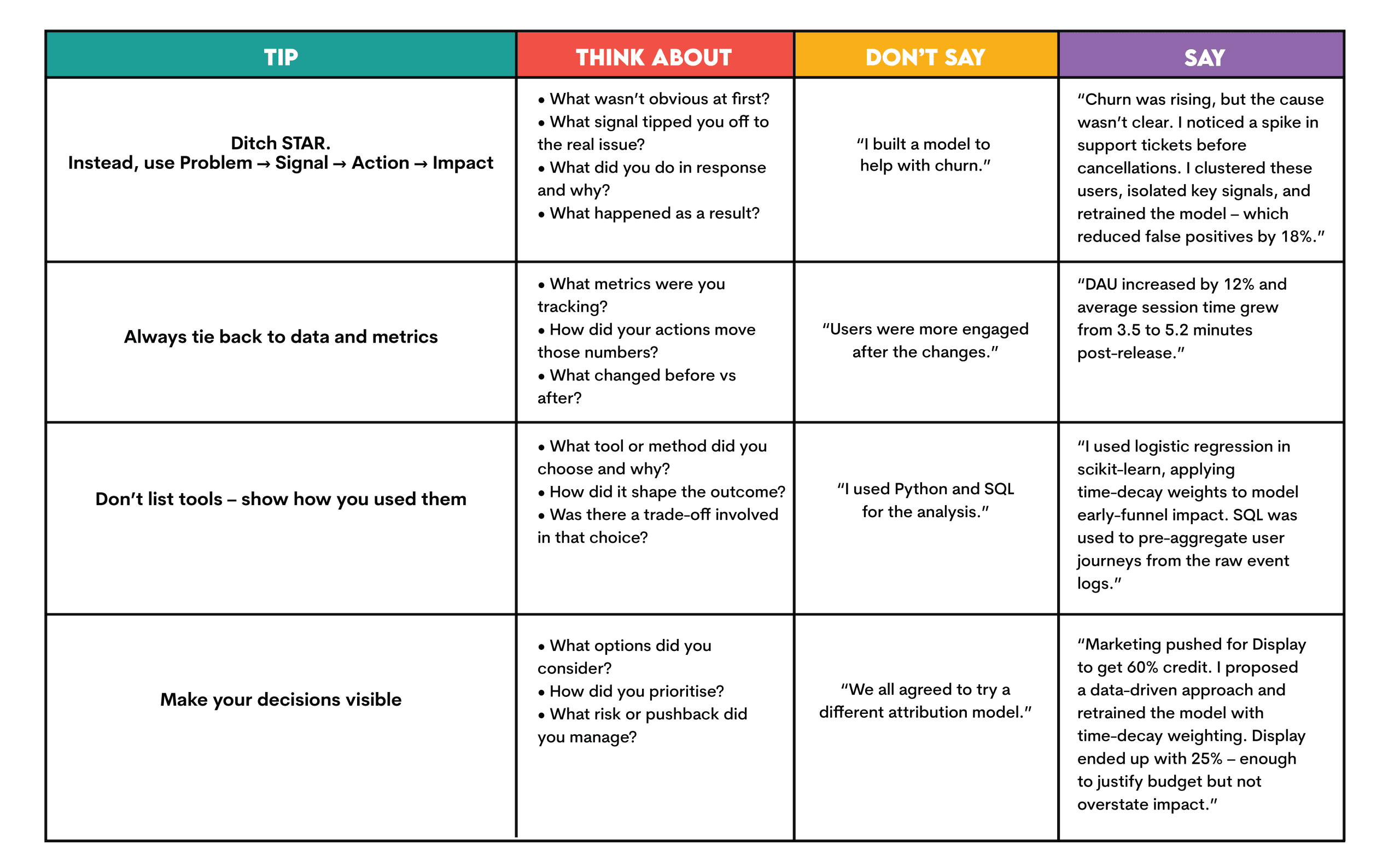
Let’s get practical now and show you how to apply the above tips to the actual interview questions.
Interview Question Examples
I’ll give you several examples of typical behavioral interview questions. I’ll first answer them using the STAR approach and then suggest a better answer. By better, I mean making your answer scream: “We have a data scientist here!”
Example #1
Q: Tell me about a time you made a mistake.
STAR Answer:
Situation: At my last job, we had a tight deadline for a customer churn model.
Task: I had to deliver model performance metrics before the stakeholder meeting.
Action: I built the pipeline quickly but forgot to drop data leakage columns.
Result: The model looked great, but it failed in production. I learned to always check for leakage.
Better Answer:
During a churn modelling project, I trained a scikit-learn model that hit 92% accuracy. That was unusually high, considering our historical average topped out at 80%. Something was off, even if nothing looked obviously broken.
I used pandas_profiling and custom datetime checks to audit the pipeline. That’s when I found the issue: the customer_last_support_call feature contained timestamps from after the churn event. The model had access to information it wouldn’t have at prediction time, which is classic data leakage.
The mistake was mine; I’d rushed to present results without validating the temporal logic. After realising this, I rebuilt the feature pipeline using pandas to filter pre-churn data only and rewrote the cross-validation process with TimeSeriesSplit to respect event order and avoid look-ahead bias. The new model dropped to 79%, which is much closer to historical performance and far more trustworthy.
I then added automated validation checks with pytest and Great Expectations to flag future-looking features early, and I documented the incident in our internal wiki as a reference for the team.
I learned that in data science, suspiciously good results are rarely a win. They’re a warning. Your job is to interrogate the data, question the metrics, and make sure the model reflects the real-world conditions it’s meant to inform.
Example #2
Q: Tell me about a time you had a conflict with a stakeholder.
STAR Answer:
Situation: I was working with a marketing manager on campaign attribution.
Task: She wanted to prove that a specific channel was driving all conversions.
Action: I showed her the data didn’t support that conclusion.
Result: We eventually agreed to use a multi-touch attribution model.
Better Answer:
We were analysing conversion attribution across four paid channels, and things got messy quickly. The marketing lead insisted Display was responsible for 60% of conversions, all based entirely on anecdotal feedback and intuition.
I pulled the data from BigQuery, and our existing last-touch model attributed just 15% of conversions to Display. That created friction: one side trusted the model, the other trusted their instinct.
Attribution is rarely clean. I didn’t dismiss the claim outright. I recognised that last-touch models underplay early-funnel influence. So I extracted the complete user journey data, cleaned it in pandas, and proposed an alternative: a logistic regression model with time-decay weighting. The idea was to capture each channel’s marginal contribution, with more recent touchpoints weighted slightly higher.
I trained the model using scikit-learn, applying exponential decay to features based on time-to-conversion. When we reassigned attribution based on the model’s predicted probabilities, Display’s share rose from 15% to 25%. Not 60%, but a meaningful improvement that reflected partial influence.
That helped shift the conversation. It gave the marketing team enough validation to feel heard without us over-indexing on gut instinct. I also built a Streamlit dashboard that updated weekly and let stakeholders adjust decay assumptions to see attribution changes in real time.
This experience reinforced that attribution isn’t about getting the one “right” number; it’s about quantifying uncertainty in a way that supports better, more defensible decisions.
Example #3
Q: Tell me about a time you influenced business decisions.
STAR Answer:
Situation: Our team wanted to understand user drop-off.
Task: I was asked to analyse funnel data.
Action: I created a dashboard showing drop-off at step 2.
Result: The product team used this to improve the onboarding flow.
Better Answer:
When I was asked to look into high drop-offs in our onboarding funnel, the data was ambiguous. We had a 62% abandonment rate between sign-up and first action, but the aggregate view didn’t explain what drove it.
I ran a cohort-level funnel analysis using SQL and pandas, slicing by platform and acquisition source. That’s when a signal emerged: Android users were failing at the first step 40% more often than iOS users.
There was no logged bug and no red flags in the instrumentation, so I dug deeper. I pulled session replay and screen resolution data, and that’s when the root cause clicked: the CTA button was rendering below the fold on smaller Android screens. It wasn’t visible without scrolling — something the product team had missed because they were testing primarily on iOS devices.
I proposed an A/B test, implemented using our internal experimentation platform, to reposition the CTA for Android. The test group saw an 18% increase in activation and a 6% lift in 30-day retention.
However, the bigger win was process-related: I built a Metabase dashboard to track onboarding retention by device cohort. That dashboard is now part of the weekly PM review cycle across three product teams, helping them catch platform-specific friction earlier.
This wasn’t just about fixing a UI issue – it was about using data to make something measurable, repeatable, and actionable.
Conclusion
The STAR approach can probably help answer some behavioral interview questions. However, that approach is not particularly suited for data science interviews.
Even when answering behavioral questions, you should show that you’re a data scientist and a good one at that. Follow the examples and tips I gave you, tweak them a little to suit your personality and experience, and I’ll bet you’ll do well in the interviews.
Nate Rosidi is a data scientist and in product strategy. He’s also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.