
Large Language Models (LLMs) have gained significant attention in the field of simultaneous speech-to-speech translation (SimulS2ST). This technology has become crucial for low-latency communication in various scenarios, such as international conferences, live broadcasts, and online subtitles. The primary challenge in SimulS2ST lies in producing high-quality translated speech with minimal delay. This requires a sophisticated policy to determine the optimal moments to initiate translation within streaming speech inputs (READ action) and subsequently generate coherent target speech outputs (WRITE action).
Current methodologies face several challenges. Existing simultaneous translation methods primarily focus on text-to-text (Simul-T2TT) and speech-to-text translation (Simul-S2TT). These approaches typically rely on cascading external modules like speech recognition (ASR) and text-to-speech synthesis (TTS) to achieve SimulS2ST. However, this cascaded approach tends to amplify inference errors progressively between modules and impedes the joint optimization of various components, highlighting the need for a more integrated solution.
Researchers have made several attempts to address the challenges in simultaneous speech-to-speech translation, primarily focusing on Simul-T2TT and Simul-S2TT translation methods. In Simul-T2TT, approaches are categorized into fixed and adaptive methods. Fixed methods, such as the wait-k policy, employ a predetermined strategy of waiting for a set number of tokens before alternating between READ and WRITE actions. Adaptive methods utilize techniques like monotonic attention, alignments, non-autoregressive architecture, or language models to dynamically perform Simul-T2TT. For Simul-S2TT, the focus has been on speech segmentation. Fixed pre-decision methods divide speech into equal-length segments, while adaptive methods split speech inputs into words or segments before applying Simul-T2TT policies. Some researchers have also explored applying offline models to Simul-S2TT tasks. Despite these advancements, these methods still rely heavily on cascading external modules, which can lead to error propagation and hinder joint optimization of the translation process.
Researchers from Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences (ICT/CAS), Key Laboratory of AI Safety, Chinese Academy of Sciences, University of Chinese Academy of Sciences, School of Future Science and Engineering, Soochow University present StreamSpeech, it addresses SimulS2ST challenges by introducing textual information for both source and target speech, providing intermediate supervision and guiding policy through text-based alignments. This direct SimulS2ST model employs a two-pass architecture, first translating source speech to target text hidden states, and then converting these to target speech. Multiple CTC decoders, optimized via ASR and S2TT auxiliary tasks, provide intermediate supervision and learn alignments for policy guidance. By jointly optimizing all modules through multi-task learning, StreamSpeech enables concurrent learning of translation and policy, potentially overcoming the limitations of previous cascaded approaches.
StreamSpeech’s architecture comprises three main components: a streaming speech encoder, a simultaneous text decoder, and a synchronized text-to-unit generation module. The streaming speech encoder utilizes a chunk-based Conformer design, which enables it to process streaming inputs while maintaining bi-directional encoding within local chunks. The simultaneous text decoder generates target text by attending to the source speech hidden states, guided by a policy that determines when to generate each target token. This policy is informed by alignments learned through multiple CTC decoders, which are optimized via auxiliary tasks of ASR and S2TT. The text-to-unit generation module employs a non-autoregressive architecture to synchronously generate units corresponding to the decoded text. Finally, a HiFi-GAN vocoder synthesizes the target speech from these units.
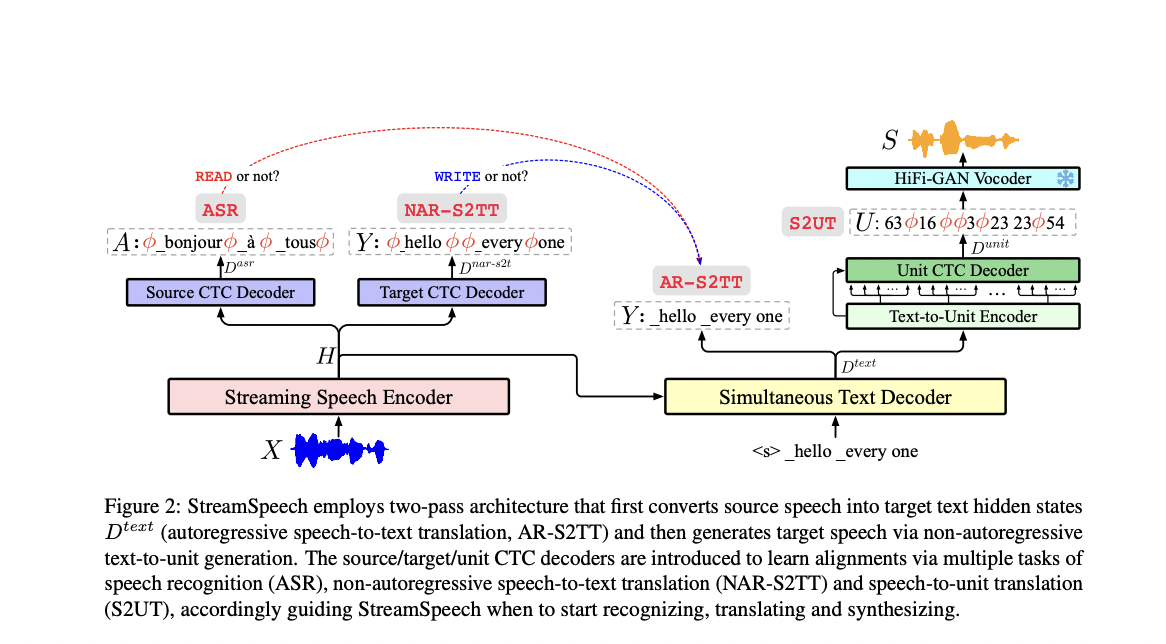
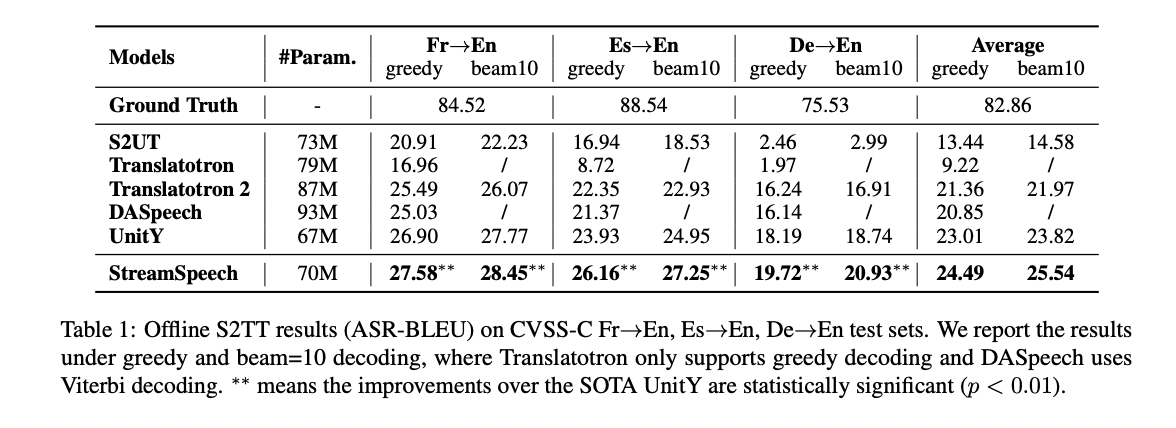
StreamSpeech demonstrates superior performance in both offline and S2ST tasks. In offline S2ST, it outperforms the state-of-the-art UnitY model with an average improvement of 1.5 BLEU. The model’s architecture, combining autoregressive speech-to-text translation with non-autoregressive text-to-unit generation, proves effective in balancing modeling capabilities and alignment capture. In simultaneous S2ST, StreamSpeech significantly outperforms the Wait-k baseline, showing approximately 10 BLEU improvement under low latency conditions across French, Spanish, and German to English translations. The model’s alignment-derived policy enables more appropriate translation timing and coherent target speech generation. Also, StreamSpeech shows advantages over cascaded systems, highlighting the benefits of its direct approach in reducing error accumulation and improving overall performance in Simul-S2ST tasks.
StreamSpeech represents a significant advancement in simultaneous speech-to-speech translation technology. This innovative “All in One” seamless model effectively handles streaming ASR, simultaneous translation, and real-time speech synthesis within a unified framework. Its comprehensive approach allows for improved performance across multiple tasks, including offline speech-to-speech translation, streaming ASR, simultaneous speech-to-text translation, and simultaneous speech-to-speech translation.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.