
Text-to-speech (TTS) is a machine learning task in which the model transforms the text input into audio output. You might already encounter TTS applications in daily life, such as GPS producing spoken directions or voice response from our phone virtual assistant.
Technological advancement has driven TTS systems to more than simple robotic voices in the modern era. Instead, we have more varying human-like speech with inflection mimicking normal conversation.
As the application of TTS becomes massive, we need to understand TTS solutions with contemporary models. Models such as E2-TTS and F5-TTS have presented breakthroughs that use current architecture to help the model generate high-quality audio with minimal latency.
This article will focus on the E2 and F5 TTS models and how to apply them in your project.
Let’s get into it.
E2 and F5-TTS Model
Let’s briefly discuss the F5 and E2 TTS Models to know them better.
E2 TTS (Embarrassingly Easy TTS) is a fully non-autoregressive zero-shot TTS model that can generate speaker voice.
E2 TTS is a model developed by the Microsoft team in response to complex traditional TTS systems that rely on autoregressive or hybrid autoregressive/non-autoregressive architectures. Models such as Voicebox and NaturalSpeech 3 have produced significant results in TTS quality, but the architecture is often perceived as too complex and having bad inference latency.
E2 TTS produces a more straightforward model using only two components: the flow-matching Transformer and the vocoder. The method eliminates the need for other elements, such as phoneme alignment, which allows for streamlined system architecture.
F5 TTS (A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching) is more recent research as it is built on top of the foundation developed by E2 TTS models and similar models. The model is created in response to flaws in traditional TTS systems, such as inferences latency and unnaturalness from the output.
The model explores non-autoregressive and flow-based techniques for generating mel spectrogram components as a foundation. Still, the team evolved further by combining a flow-matching approach with a Diffusion Transformer (DiT). The methods allow the model to generate better-quality speech with much faster inference as the pipeline becomes simpler.
Over time, newer models will emerge that surpass the E2 and F5 TTS models. However, these models represent the current state-of-the-art TTS technology, and most applications will perform well with them.
With how well the model performs, it’s beneficial to understand how to use these models in the next section. We will use the HuggingFace Space to make it easier for us to test the models.
Audio Model Testing
The E2 TTS and F5 TTS Base Models are available in HuggingFace, and we can download them. However, we will use the Hugging Space, which has implemented the E2 and F5 TTS for us.
Let’s open them, and you will see the page below.

You can select either the E2 or F5 models to try. Currently, the space only supports English and Chinese, but you can always fine-tune the model to apply it to another language.
The model will need a sample audio as a reference to generate a human-like speech from the text. You can either drop the file or record it by yourself. Then, you need to pass the text to develop into the field.
Overall, it will look like this.

You can access the advanced settings to manipulate the model parameters and pass the reference text to enable precise TTS generation. If you feel things are already promising, you don’t need to change anything.
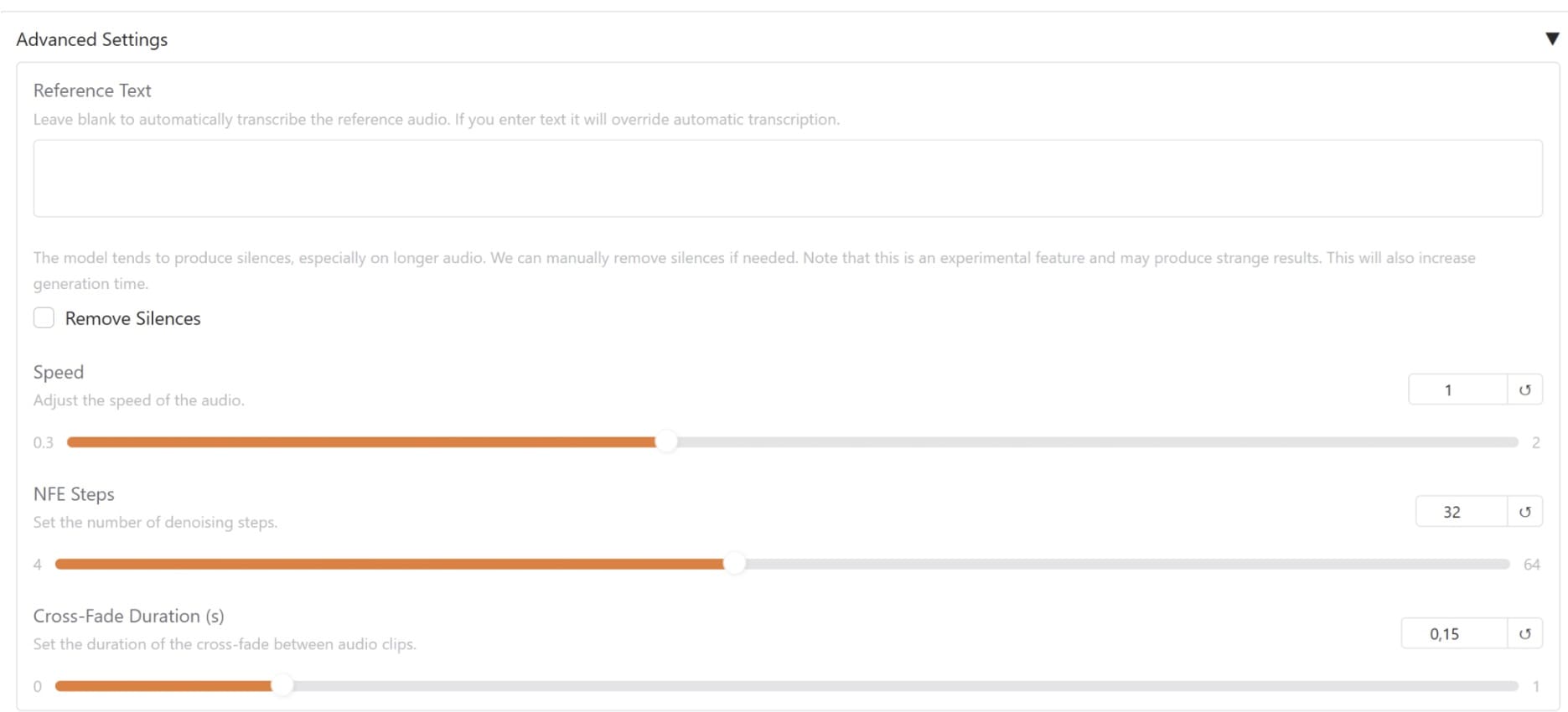
The audio result is available to play and download in the section below. It also provides a spectrogram to analyze the generated audio.

You can use the model to generate them simultaneously if you have multiple reference audio, such as various speech emotions or voice types.
To do that, select the Multi-Speech option, and you will be presented in the selection below.

You can upload and add different reference audio with other labels for each. Try to add as much as you need.
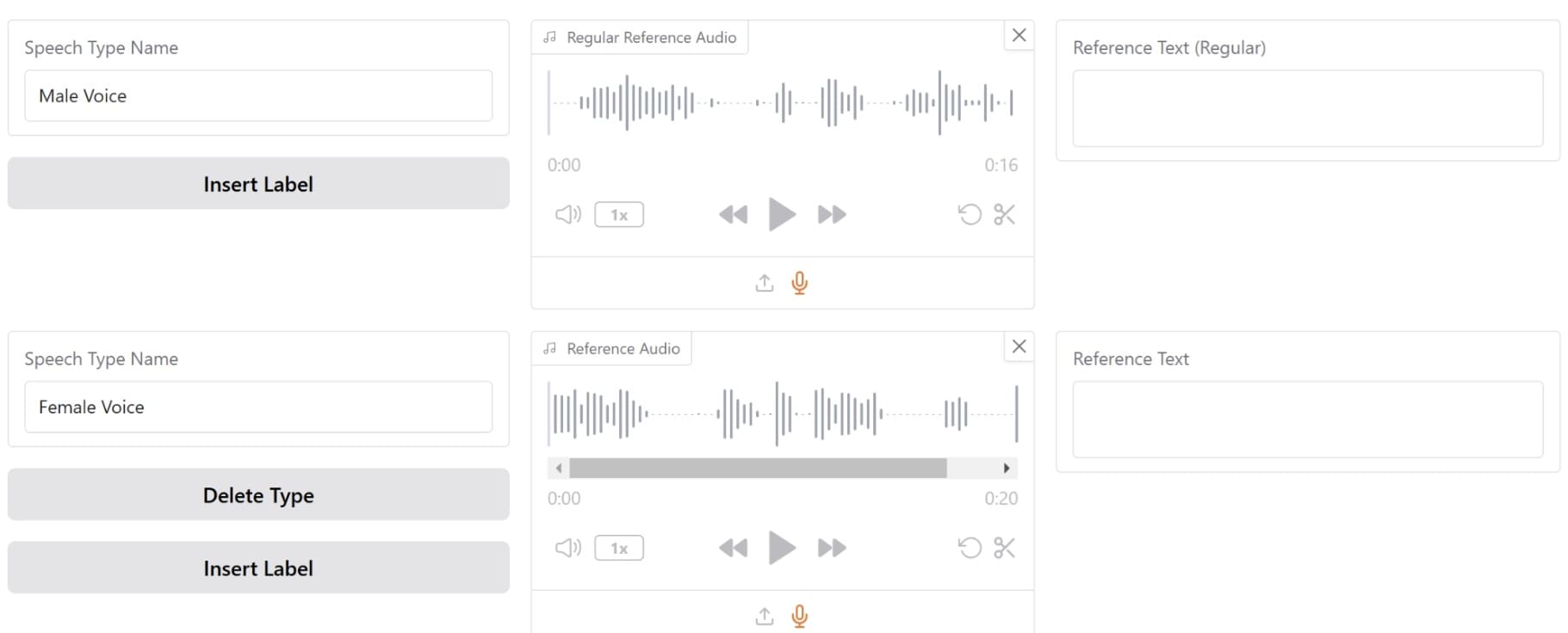
Then, we can generate multiple speeches within the audio by passing the text to generate. In a multi-speech generation, you will pass the speech type label before the text to indicate which audio to use.
For example, I generate two-person conversations using previous references I upload to the model.

The result is ready, and you only need to download it if you need it. The audio quality will depend on all the references you pass, including the emotion or inflection. If you feel the output is not good, it usually comes from the audio reference quality we pass.
Lastly, the space allows for Voice Chat conversations with the Chat Model, where the model replies to the conversations with the reference voice we pass. For example, I am passing the reference chat like in the image below and having the System Prompt stay in default.
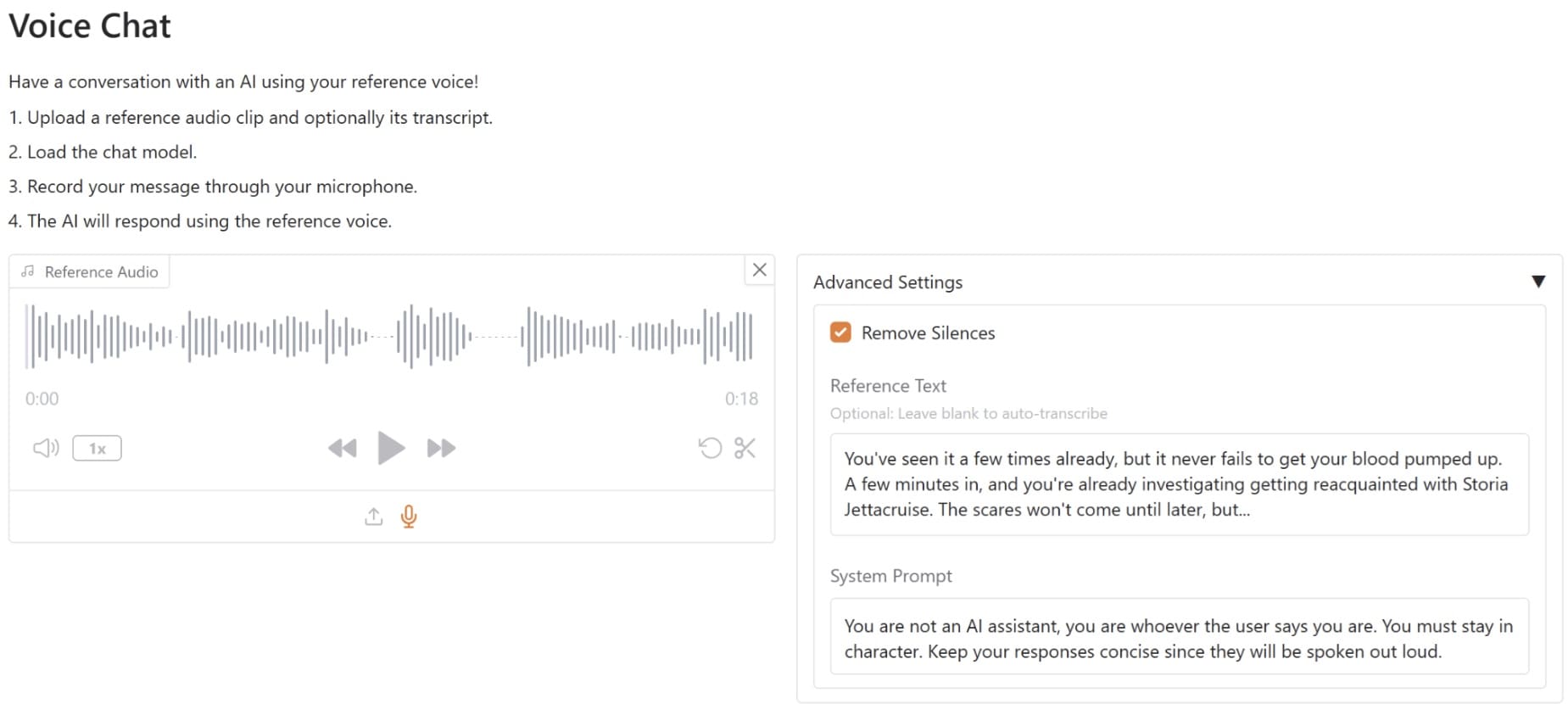
Next, I recorded the message I wanted to input into the Chat model. The model generated results in text and audio formats, utilizing the reference audio provided earlier.

You can keep the conversation going, and the audio reference will generate the audio result quickly and faithfully.
That’s all the implementation of the E2 and F5 TTS model in the HuggingFace Space. You can always try to copy the code base to use them in your project.
Conclusion
Contemporary text-to-speech solutions, such as E2 and F5 TTS models, have signified technological advancements in the TTS field. These models address traditional challenges, like inference latency and unnatural speech, with innovative architectures that streamline processes and enhance output quality.
By leveraging platforms like HuggingFace Space, we have tried implementing the models in various use cases and applications to produce human-like speech output and conversations.
Understanding and utilizing state-of-the-art models like E2 and F5 TTS will ensure your skill is relevant for businesses and developers that require audio-based innovations.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and data tips via social media and writing media. Cornellius writes on a variety of AI and machine learning topics.