
Large Language Models (LLMs) have revolutionized natural language processing but face significant challenges in handling very long sequences. The primary issue stems from the Transformer architecture’s quadratic complexity relative to sequence length and its substantial key-value (KV) cache requirements. These limitations severely impact the models’ efficiency, particularly during inference, making them prohibitively slow for generating extended sequences. This bottleneck hinders the development of applications that require reasoning over multiple long documents, processing large codebases, or modeling complex environments in agent-based systems. Researchers are therefore seeking more efficient architectures that can maintain or surpass the performance of Transformers while significantly reducing computational demands.
Researchers have explored various approaches to qualify the efficiency challenges in LLMs. Attention-free models, such as S4, GSS, and BiGS, have demonstrated improved computational and memory efficiency. The Mamba model, incorporating input-specific context selection, has shown superior performance compared to Transformers across different scales. Other sub-quadratic and hybrid architectures have also been proposed. Distillation techniques have been employed to transfer knowledge from Transformers to linear RNN-style models, as seen in Laughing Hyena and progressive knowledge approaches. Speculative decoding has emerged as a promising method to accelerate inference, utilizing smaller draft models to generate candidate tokens for verification by larger target models. These approaches include rejection sampling schemes, tree-structured candidate organization, and both trained and training-free draft models.
Researchers from Cornell University, the University of Geneva, Together AI, and Princeton University propose a unique approach to mitigate the efficiency challenges of LLM models by distilling a pre-trained Transformer into a linear RNN. This method aims to preserve generation quality while significantly improving inference speed. The proposed technique involves mapping Transformer weights to a modified Mamba architecture, which can be directly initialized from the attention block of a pre-trained model. A multistage distillation pipeline, combining progressive distillation, supervised fine-tuning, and directed preference optimization, is introduced to enhance perplexity and downstream performance. The researchers also develop a hardware-aware speculative sampling algorithm and a fast kernel for speculative decoding on Mamba and hybrid architectures, achieving a throughput of over 300 tokens/second for a 7B-parameter model. This approach effectively applies speculative decoding to the hybrid architecture, addressing the need for efficient inference in complex LLM applications.
The proposed method transforms Transformer models into Mamba models using linear RNNs, addressing the limitations of attention mechanisms. By expanding the linear hidden state capacity through Mamba’s continuous-time state-space model, the approach dynamically constructs a discrete-time linear RNN. This innovative architecture initializes from attention parameters and employs hardware-aware factorization for efficient implementation. The method then applies knowledge distillation to compress the large Transformer model into a smaller Mamba-based network, focusing on fine-tuning and alignment steps. This process combines sequence-level knowledge distillation and word-level KL-Divergence for supervised fine-tuning while adapting Direct Preference Optimization for preference alignment.
The distillation process enables the student model to learn from the teacher’s output distribution and generation, optimizing for both performance and alignment with desired preferences. Throughout this process, MLP layers from the original model remain frozen, while Mamba layers are trained to capture the distilled knowledge. This approach allows for the replacement of attention blocks with linear RNN blocks while maintaining model performance. By expanding the hidden state size and using hardware-aware factorization, the method achieves efficient implementation, enabling larger hidden sizes without significant computational costs. The resulting Mamba-based model combines the benefits of Transformer architectures with the efficiency of linear RNNs, potentially advancing the field of LLMs.
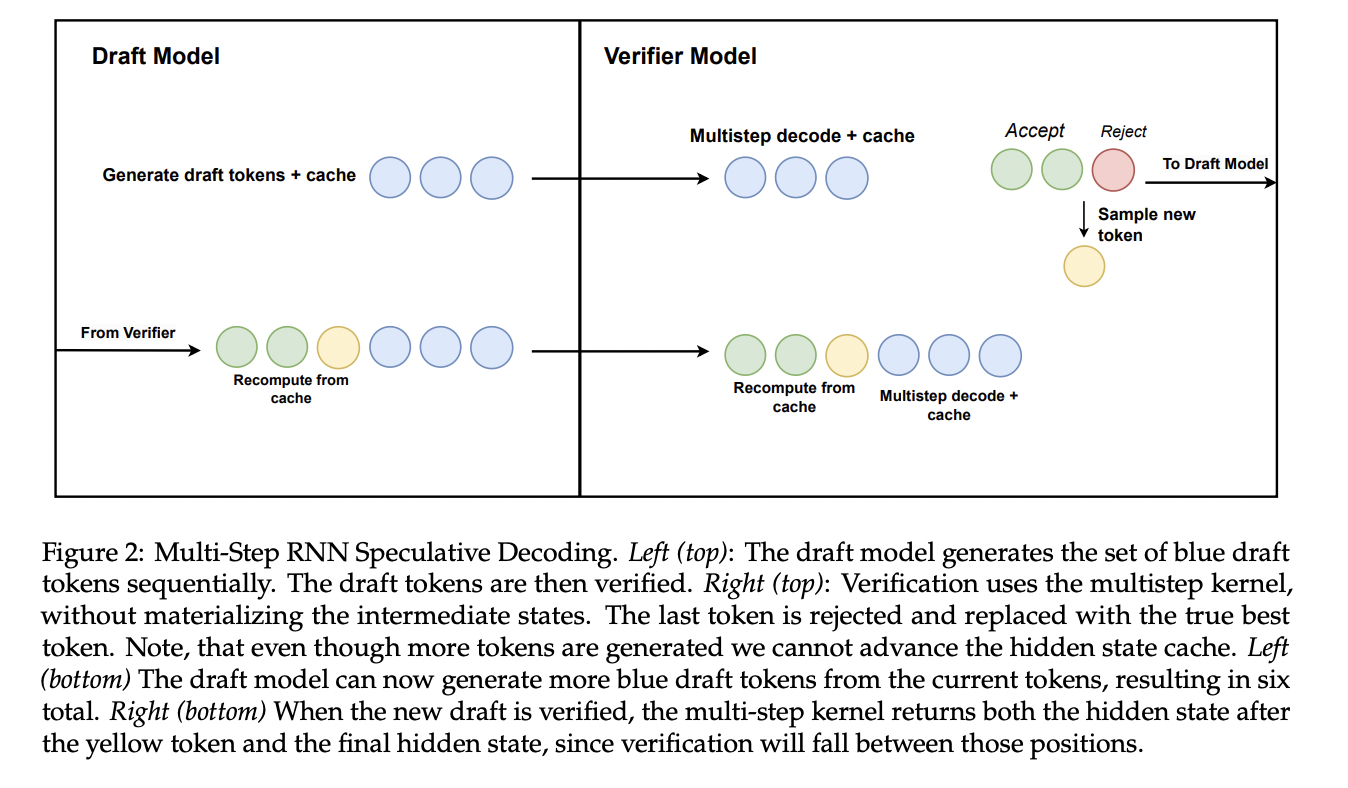
The distilled hybrid Mamba models demonstrate competitive performance on various benchmarks. On chat benchmarks like AlpacaEval and MT-Bench, the 50% hybrid model achieves similar or slightly better scores than its teacher model, outperforming some larger transformers. In zero-shot and few-shot evaluations, the hybrid models surpass open-source linear RNN models trained from scratch, with performance degrading as more attention layers are replaced. The hybrid models also show promising results on the OpenLLM Leaderboard and ZeroEval benchmark. Speculative decoding experiments with these hybrid models achieve speedups of up to 1.88x on a single GPU. Overall, the results indicate that the distilled hybrid Mamba models offer a good balance between efficiency and performance.

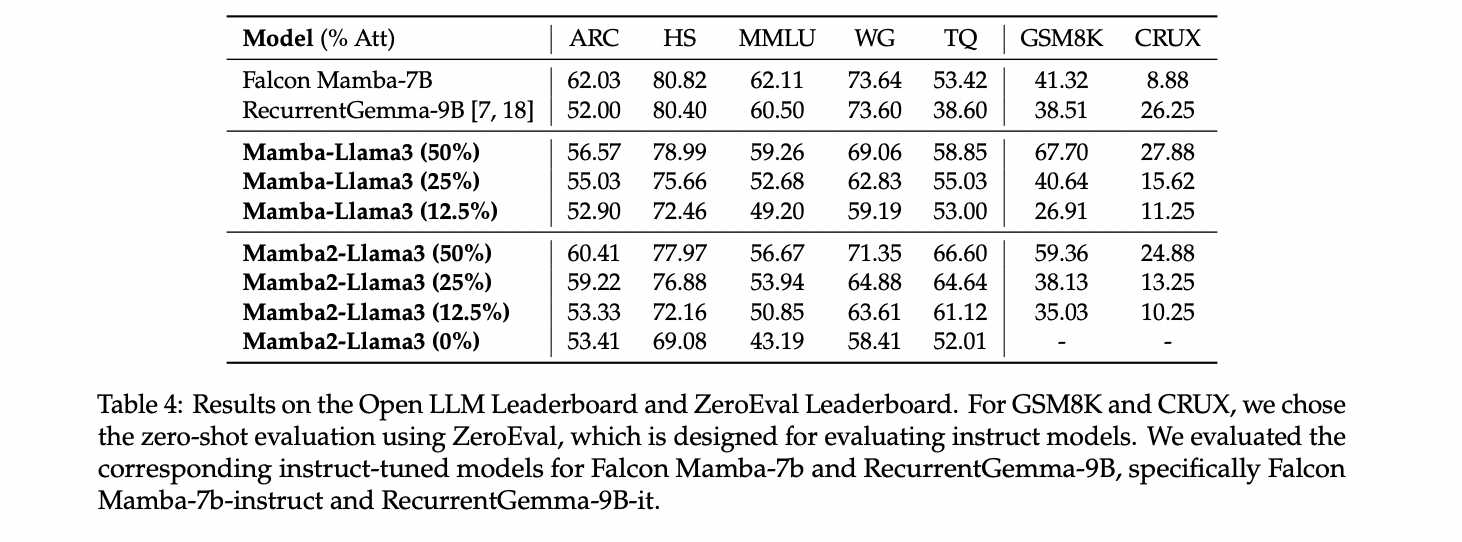
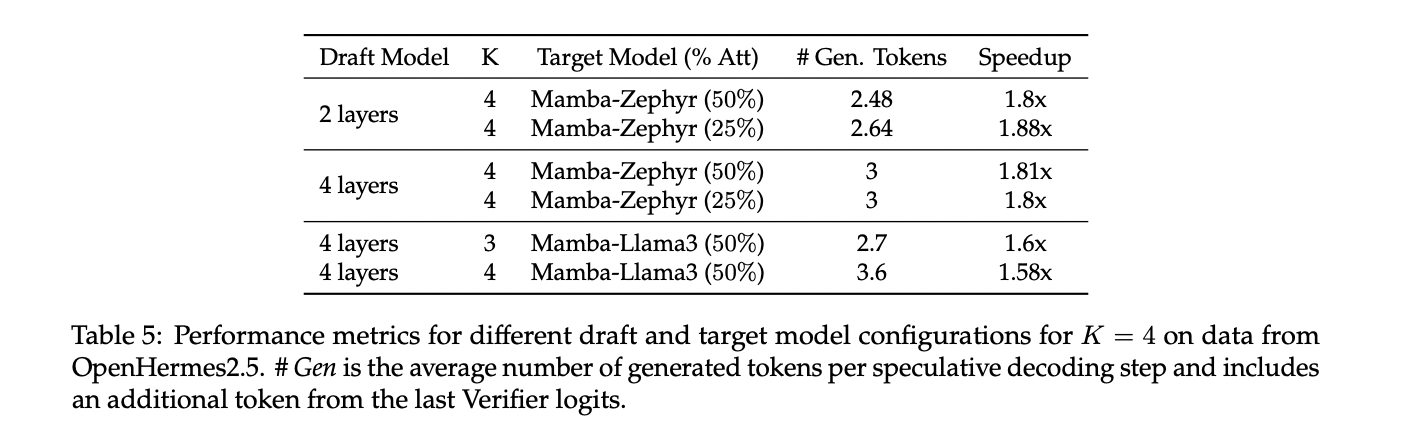
This study presents a unique method for transforming Transformer models into more efficient Mamba-based models using linear RNNs. Results show that the distilled hybrid Mamba models achieve comparable or better performance than their teacher models on various benchmarks, including chat tasks and general language understanding. The method demonstrates particular success in maintaining performance while reducing computational costs, especially when retaining 25-50% of attention layers. Also, the researchers introduce an innovative speculative decoding algorithm for linear RNNs, further enhancing inference speed. These findings suggest significant potential for improving the efficiency of LLMs while preserving their capabilities.
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.