
Image by Author | Ideogram
Learning the necessary knowledge skills to become an LLM engineer sounds like a daunting quest to many, not only because it is — let’s face it — not the easiest thing to learn, but also because it’s hard to decide where to start and how to build up your learning journey.
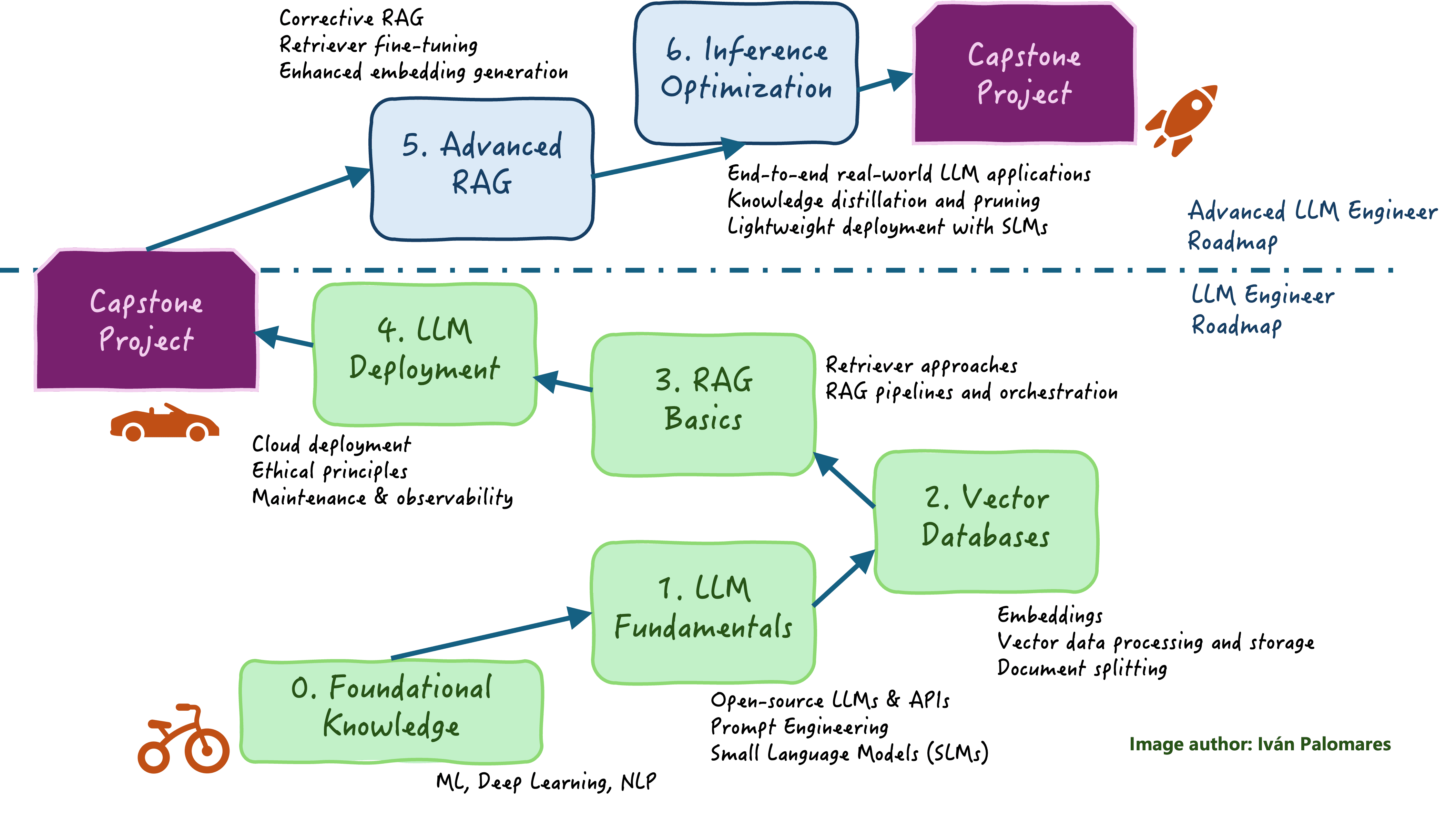
This article presents a comprehensive roadmap that puts all the pieces of the intricate jigsaw together, providing a clear learning pathway to becoming a skilled LLM engineer: from the underlying AI and machine learning (ML) foundations to retrieval augmented generation (RAG) approaches to real-world LLM application deployment.
Let’s start with the basics and then gradually move from the most indispensable LLM engineering topics to more advanced ones, by subdividing the overall roadmap into two major milestones for progressive learning:
- LLM Engineer Roadmap
- Advanced LLM Engineer Roadmap
LLM Engineer Roadmap
LLM Engineer Roadmap
The first part of the roadmap covers foundational knowledge and skills, subsequently moving into leveraging and deploying simple standalone and RAG-based LLM applications.
0. Foundational Knowledge
For some wannabe LLM engineers with an AI/ML background, this “stage zero” could be skipped or taken to freshen up knowledge. If that’s not your case, take note of the basics to acquire first, before diving deep into LLMs.
- Machine learning basics: understand supervised and unsupervised models, linear and nonlinear models, gradient descent optimization to build models that learn from data, and metrics to evaluate ML models.
- Deep learning: neural network architectures, the backpropagation process to train them, and optimization approaches like optimizers, batch normalization, etc.
- NLP fundamentals: LLMs are, in essence, Natural Language Processing (NLP) elevated to their maximum exponent. Hence it is crucial to learn NLP concepts and key processes to process text data like tokenization, embeddings, sequence modeling, and understanding the transformer architecture under which LLMs sit.
1. LLM Fundamentals
A gentle way to immerse yourself in LLMs includes working with LLM APIs like OpenAI and Hugging Face, which provide ready-to-use and pre-trained LLMs to play and experiment with. Likewise, explore specific open-source models like LLaMA, and leverage Small Language Models (SLMs) like DistilBERT and TinyBERT to fully explore how they can address a variety of language understanding and language generation tasks.
2. Vector Databases
After touching base with LLMs, and to prepare for later stages of the roadmap, it’s time to learn all about vector databases, that is, storing, managing, and processing efficient representations of text data like thousands or millions of documents. This is the fuel of every LLM system, not only to learn to perform language tasks when they are being trained but also (as we will reveal shortly) to perform inference as effectively as possible. At this phase, familiarize yourself with document ingestion and splitting techniques, learn how to build document embeddings using models like BERT and SentenceTransformers, and learn how to implement vector databases for semantic search, with tools like FAISS or Pinecone.
3. RAG Basics
RAG has become a virtually indispensable aid for enhancing the performance of standalone LLMs by relying on additional sources of retrieved knowledge from vector databases to improve the answers to user queries. Getting familiar with orchestration frameworks like LangChain and LlamaIndex at this stage, optimizing retrievers, and building prompt templates, are crucial skills needed to build simple RAG pipelines. We recommend the Understanding RAG article series for a conceptual introduction to this exciting and cornerstone part of LLM engineering nowadays.
4. LLM Deployment
To wrap up the “not-so-basic” part of this roadmap, let’s plunge into aspects related to deploying LLMs. Learn how to deploy LLMs in cloud environments like GCP or AWS, as well as edge environments; how to monitor performance metrics, detect errors and drifts for observing and maintaining deployed models, and expose yourself to ethical AI principles like bias mitigation and explainability, both crucial to LLMs released into the real world. Finalize by trying to deploy a basic or lightweight language model (possibly an SLM) like a Q&A chatbot using a combination of the tools learned so far. This could make for a nice capstone project at this milestone.
Advanced LLM Engineer Roadmap
This part dives deeper into LLM fine-tuning, optimization, and advanced LLM approaches, to culminate with a proposal for a capstone project in which we suggest you create a more complex, high-performance LLM application to consolidate yourself as an LLM engineering pro.
5. Advanced RAG and LLM Evaluation
This is the right time to dive much deeper into advanced RAG approaches like corrective and fusion retrieval techniques (filtering, reranking, etc.), explore ways to improve RAG performance with HyDE (Hypothetical Document Embedding) to build enhanced embeddings, or learning the evaluation method known as ‘LLM-as-a-Judge‘ to comprehensively assess LLM outputs beyond usual metrics. A Better Way To Evaluate LLMs. Last, explore retriever fine-tuning techniques for domain-specific use cases.
6. Inference Optimization
Almost there! At this point, you should be ready to fully immerse yourself into advanced mechanisms to optimize deployed LLMs, like model quantization to reduce the size and latency of your models, knowledge distillation to create SLMs upon LLMs, pruning methods to remove unnecessary parameters and improve efficiency (recall that LLMs typically have up to billions of parameters!), and in general, fully examine how to leverage SLMs for deploying lightweight solutions efficiently.
Wrapping Up
The LLM engineering roadmap described in this article is designed to help learners progress logically from foundations to advanced practical skills, thereby gaining hands-on experience to develop or deal with modern LLM tools, applications, and techniques.
On top of the knowledge gained at the end of the itinerary, it is always important to understand the many trade-offs to consider when it comes to LLMs, for example the performance-efficiency trade-off usually related to the choice between LLMs or their minimalistic counterpart: SLMs. The learning content suggested for advanced stages are designed to prepare you to tackle real-world challenges, from building lightweight applications to scaling business-oriented LLM systems in a variety of scenarios.
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.