
In AI, developing language models that can efficiently and accurately perform diverse tasks while ensuring user privacy and ethical considerations is a significant challenge. These models must handle various data types and applications without compromising performance or security. Ensuring that these models operate within ethical frameworks and maintain user trust adds another layer of complexity to the task.
Traditional AI models often rely heavily on massive server-based computations, leading to challenges in efficiency and latency. Current methods include various forms of transformer architectures, which are neural networks designed for processing data sequences. Combined with sophisticated training processes and data preprocessing techniques, these architectures aim to improve model performance and reliability. However, these methods often fall short in balancing efficiency, accuracy, and ethical considerations, especially in real-time applications on personal devices.
Researchers from Apple have introduced two primary language models: a 3 billion parameter model optimized for on-device usage and a larger server-based model designed for Apple’s Private Cloud Compute. These models are crafted to balance efficiency, accuracy, and responsible AI principles, focusing on enhancing user experiences without compromising on privacy and ethical standards. Introducing these models signifies a step towards more efficient and user-centric AI solutions.
The on-device model employs pre-normalization with RMSNorm, grouped-query attention with eight key-value heads, and SwiGLU activation for efficiency. RoPE positional embeddings support long-context processing. The training utilized a diverse dataset mixture, including licensed data from publishers, open-source datasets, and publicly available web data. Pre-training was conducted on 6.3 trillion tokens for the server model and a distilled version for the on-device model. The server model underwent continued pre-training at a sequence length of 8192 with a mixture that upweights math and code data. The context-lengthening stage used sequences of 32768 tokens with synthetic long-context Q&A data. Post-training involved supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) to enhance instruction-following and conversational capabilities.
The performance of these models has been rigorously evaluated, demonstrating strong capabilities across various benchmarks. The on-device model scored 61.4 on the HELM MMLU 5-shot benchmark, while the server model scored 75.4. In addition, the server model showed impressive results in GSM8K with a score of 72.4, ARC-c with 69.7, and HellaSwag with 86.9. The AFM-server also excelled in the Winogrande benchmark with a score of 79.2. These results indicate significant improvements in instruction following, reasoning, and writing tasks. Furthermore, the research highlights a commitment to ethical AI, with extensive measures taken to prevent the perpetuation of stereotypes and biases, ensuring robust and reliable model performance.
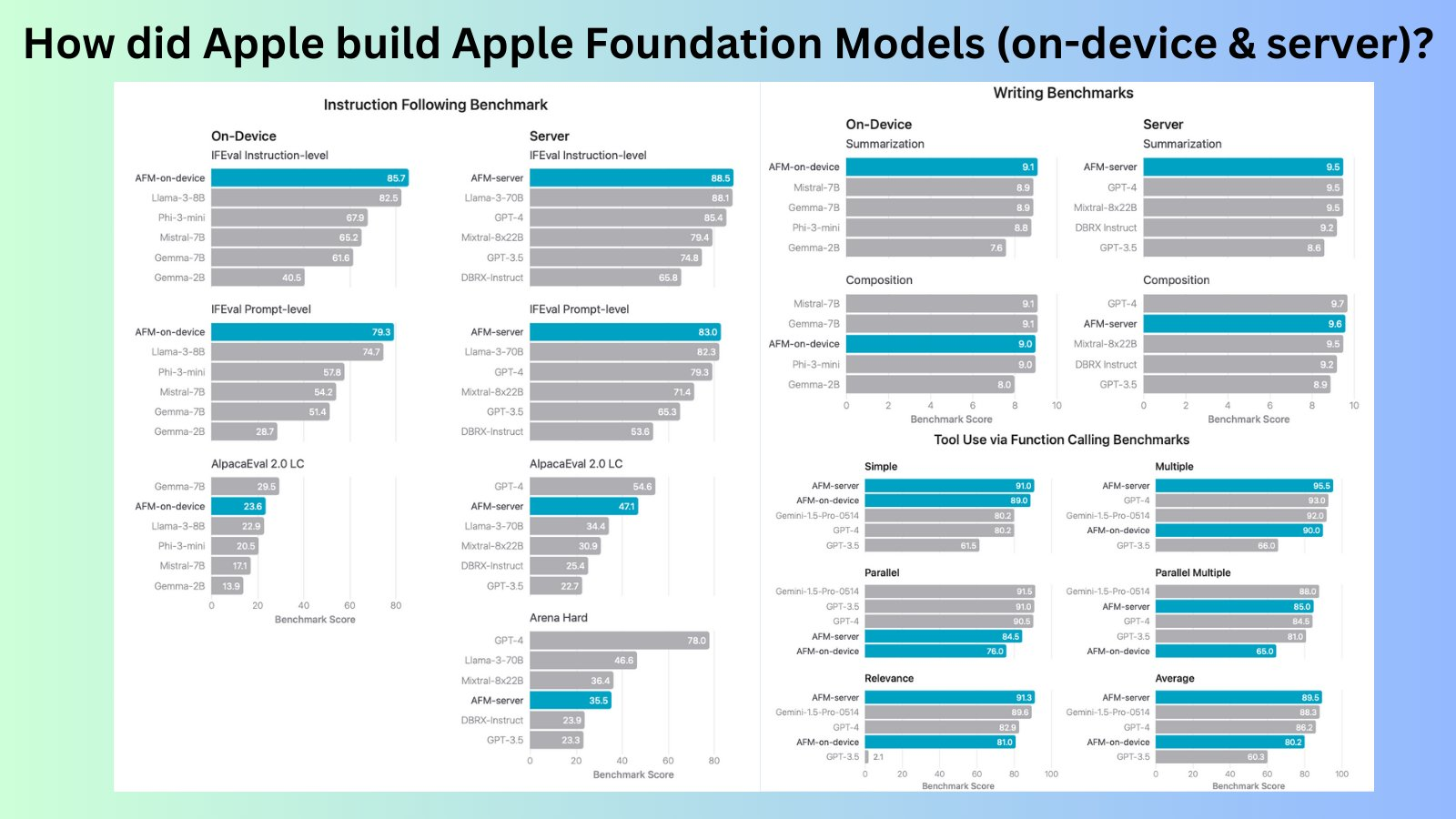
The research addresses the challenges of developing efficient and responsible AI models. The proposed methods and technologies demonstrate significant advancements in AI model performance and ethical considerations. These models offer valuable contributions to the field by focusing on efficiency and ethical AI, showcasing how advanced AI can be implemented in user-friendly and responsible ways.
In conclusion, the paper provides a comprehensive overview of Apple’s development and implementation of advanced language models. It addresses the critical problem of balancing efficiency, accuracy, and ethical considerations in AI. The researchers’ proposed methods significantly improve model performance while focusing on user privacy and responsible AI principles. This work represents a significant advancement in the field, offering a robust framework for future AI developments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
