
Spoken term detection (STD) is a critical area in speech processing, enabling the identification of specific phrases or terms in large audio archives. This technology is extensively used in voice-based searches, transcription services, and multimedia indexing applications. By facilitating the retrieval of spoken content, STD plays a pivotal role in improving the accessibility and usability of audio data, especially in domains like podcasts, lectures, and broadcast media.
A significant challenge in spoken term detection is the effective handling of out-of-vocabulary (OOV) terms and the computational demands of existing systems. Traditional methods often depend on automatic speech recognition (ASR) systems, which are resource-intensive and prone to errors, particularly for short-duration audio segments or under variable acoustic conditions. Further, these methods need help accurately segment continuous speech, making identifying specific terms without context difficult.
Existing approaches to STD include ASR-based techniques that use phoneme or grapheme lattices, as well as dynamic time warping (DTW) and acoustic word embeddings for direct audio comparisons. While these methods have their merits, they are limited by speaker variability, computational inefficiency, and challenges in processing large datasets. Current tools also need help generalizing to different datasets, especially for terms not encountered during training.
Researchers from the Indian Institute of Technology Kanpur and imec – Ghent University have introduced a novel speech tokenization framework named BEST-STD. This approach encodes speech into discrete, speaker-agnostic semantic tokens, enabling efficient retrieval with text-based algorithms. By incorporating a bidirectional Mamba encoder, the framework generates highly consistent token sequences across different utterances of the same term. This method eliminates the need for explicit segmentation and handles OOV terms more effectively than previous systems.
The BEST-STD system uses a bidirectional Mamba encoder, which processes audio input in both forward and backward directions to capture long-range dependencies. Each layer of the encoder projects audio data into high-dimensional embeddings, which are discretized into token sequences through a vector quantizer. The model employs a self-supervised learning approach, leveraging dynamic time warping to align utterances of the same term and create frame-level anchor-positive pairs. The system uses an inverted index for storing tokenized sequences, allowing for efficient retrieval by comparing token similarity. During training, the system generates consistent token representations, ensuring invariance to the speaker and acoustic variations.
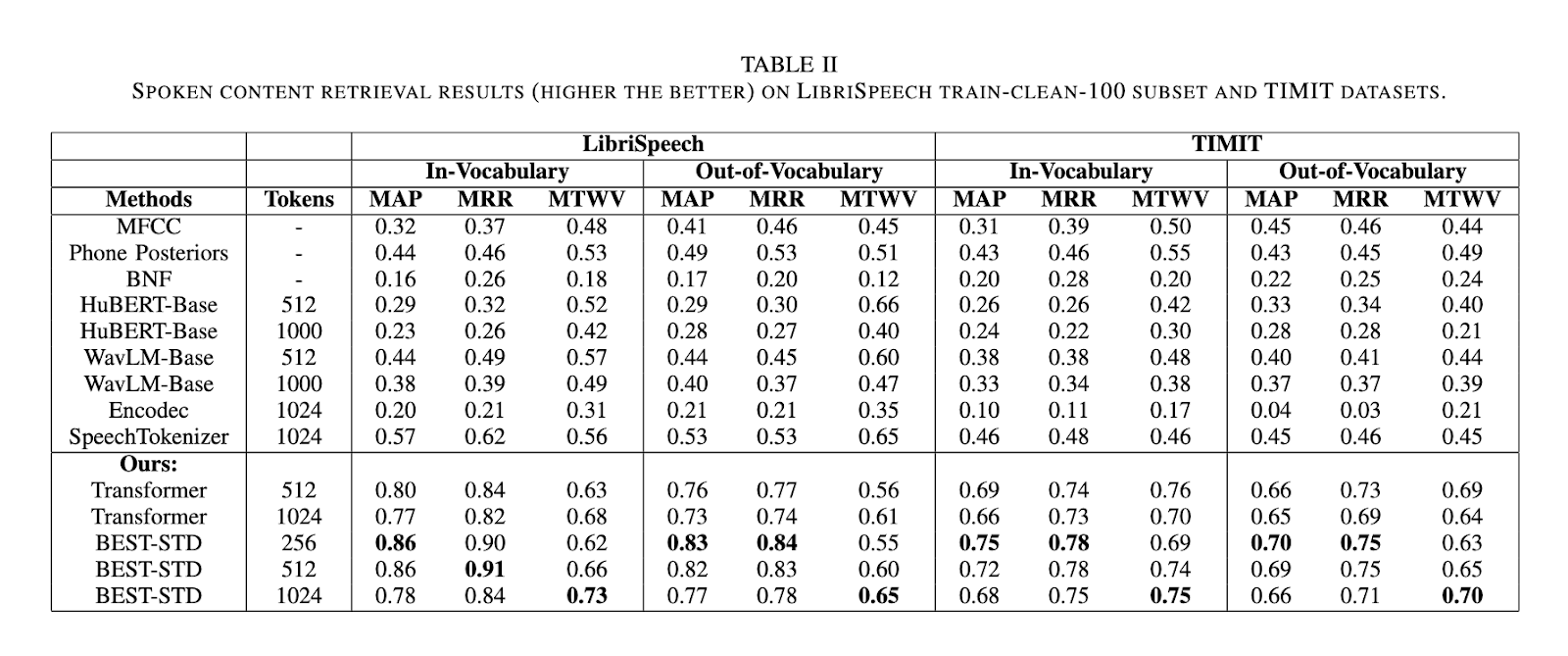
The BEST-STD framework demonstrated superior performance in evaluations conducted on the LibriSpeech and TIMIT datasets. Compared to traditional STD methods and state-of-the-art tokenization models like HuBERT, WavLM, and SpeechTokenizer, BEST-STD achieved significantly higher Jaccard similarity scores for token consistency, with unigram scores reaching 0.84 and bigram scores at 0.78. The system outperformed baselines on spoken content retrieval tasks in mean average precision (MAP) and mean reciprocal rank (MRR). For in-vocabulary terms, BEST-STD achieved MAP scores of 0.86 and MRR scores of 0.91 on the LibriSpeech dataset, while for OOV terms, the scores reached 0.84 and 0.90 respectively. These results underline the system’s ability to effectively generalize across different term types and datasets.
Notably, the BEST-STD framework also excelled in retrieval speed and efficiency, benefiting from an inverted index for tokenized sequences. This approach reduced reliance on computationally intensive DTW-based matching, making it scalable for large datasets. The bidirectional Mamba encoder, in particular, proved more effective than transformer-based architectures due to its ability to model fine-grained temporal information critical for spoken term detection.
In conclusion, the introduction of BEST-STD marks a significant advancement in spoken term detection. By addressing the limitations of traditional methods, this approach offers a robust & efficient solution for audio retrieval tasks. The use of speaker-agnostic tokens and a bidirectional Mamba encoder not only enhances performance but also ensures adaptability to diverse datasets. This framework demonstrates promise for real-world applications, paving the way for improved accessibility and searchability in audio processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
🎙️ 🚨 ‘Evaluation of Large Language Model Vulnerabilities: A Comparative Analysis of Red Teaming Techniques’ Read the Full Report (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.