
With researchers aiming to unify visual generation and understanding into a single framework, multimodal artificial intelligence is evolving rapidly. Traditionally, these two domains have been treated separately due to their distinct requirements. Generative models focus on producing fine-grained image details while understanding models prioritize high-level semantics. The challenge lies in integrating both capabilities effectively without compromising performance. As autoregressive modeling gains traction in visual tasks, the demand for a unified tokenizer that seamlessly bridges these objectives is growing.
One major challenge in this area is the disparity in visual tokenization. Current approaches often specialize in either image generation or understanding but fail to perform optimally in both tasks simultaneously. Generative models like VQVAE encode image details efficiently but struggle to align visual features with textual representations. Conversely, models like CLIP excel at semantic alignment but lack the fine-grained detail needed for high-quality image reconstruction. This misalignment creates inefficiencies, making it difficult to develop multimodal models that can generate and interpret images equally proficiently. Researchers have been exploring ways to resolve these conflicts, but existing solutions often involve increasing model complexity without fundamentally addressing the tokenization gap.
Current methods attempt to bridge this gap by integrating separate tokenization strategies for different tasks. Some models incorporate contrastive learning into generative tokenizers to enhance semantic consistency. However, these techniques introduce training conflicts that degrade model performance. Many solutions rely on large codebooks to increase token representation capacity, but excessive codebook expansion leads to underutilization and inefficiencies. The lack of a unified approach continues to hinder advancements in multimodal learning, highlighting the need for an effective tokenizer that balances generative and understanding capabilities without adding unnecessary computational overhead.
A research team from The University of Hong Kong, ByteDance Inc., and Huazhong University of Science and Technology introduced UniTok, a discrete visual tokenizer designed to unify visual generation and understanding. Their method overcomes the limitations of existing approaches through multi-codebook quantization, which expands token representation without causing optimization instability—this strategy structures vector quantization into independent sub-codebooks, enabling better representation of visual features across tasks. By addressing the fundamental bottleneck of limited discrete token capacity, UniTok achieves superior image reconstruction and semantic alignment performance.
The UniTok model employs a unified training paradigm integrating reconstruction and contrastive learning objectives. The core innovation lies in multi-codebook quantization, where visual tokens are divided into multiple independent sub-codebooks instead of a single large one. This increases the representation space while maintaining computational efficiency. UniTok also incorporates attention-based factorization, which enhances token expressiveness by preserving semantic information during compression. Unlike conventional vector quantization, this approach prevents loss conflicts and improves token utilization, ensuring visual features are accurately encoded for generative and discriminative tasks. The researchers trained UniTok on DataComp-1B, a dataset containing 1.28 billion image-text pairs, with images resized to a resolution 256×256. The tokenizer was tested under two conditions: with pretrained CLIP weight initialization and without it. The model’s ability to achieve high zero-shot accuracy in both cases demonstrates the effectiveness of its unified design.
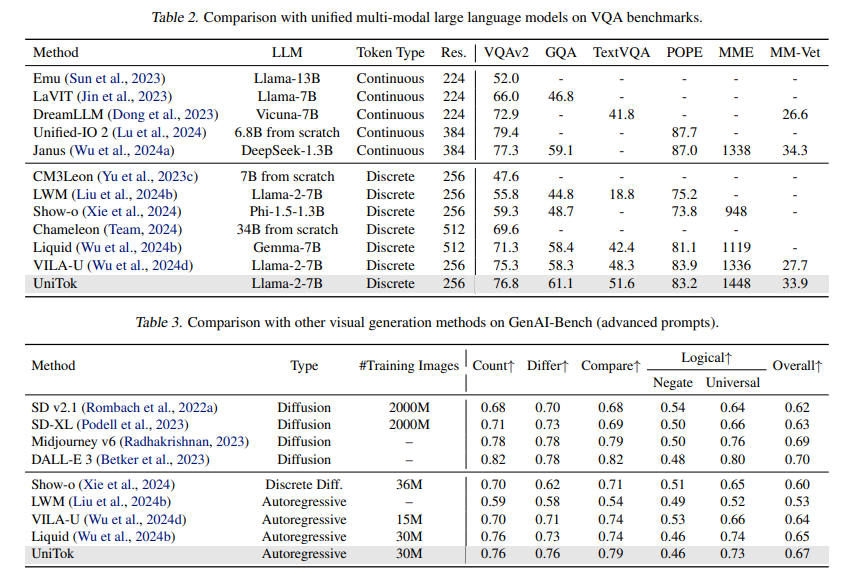
Experimental evaluations confirm UniTok’s superiority over existing tokenizers. On ImageNet, UniTok achieves an rFID of 0.38 compared to 0.87 for SD-VAE, indicating a significant improvement in reconstruction quality. Further, it records a zero-shot classification accuracy of 78.6%, outperforming CLIP’s 76.2%. The model also excels in visual question-answering benchmarks, surpassing VILA-U in accuracy by 3.3% on TextVQA and demonstrating a significant improvement of 112 points on the MME-Perception scores. These results highlight UniTok’s ability to handle image generation and understanding effectively. When tested on multimodal large language models, UniTok outperforms traditional VQVAE tokenizers and significantly reduces the gap between discrete and continuous tokenization approaches. The success of UniTok suggests that enhancing discrete token representation through multi-codebook quantization is a viable solution for unifying multimodal learning frameworks.

UniTok marks a major advancement in the integration of visual generation and understanding. Resolving tokenization bottlenecks through multi-codebook quantization enables more effective multimodal learning. The research demonstrates that when optimized correctly, discrete tokenization can rival or even surpass continuous tokenization methods. This innovation lays the foundation for future improvements in multimodal AI, offering a scalable solution for large vision-language models. The strong experimental results validate UniTok as a promising approach for achieving seamless integration between visual generation and understanding, paving the way for more advanced multimodal models in the future.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
🚨 Recommended Read- LG AI Research Releases NEXUS: An Advanced System Integrating Agent AI System and Data Compliance Standards to Address Legal Concerns in AI Datasets
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.